cybersecurity_alarm_analysis
收藏Hugging Face2025-06-01 更新2025-06-02 收录
下载链接:
https://huggingface.co/datasets/tiangler/cybersecurity_alarm_analysis
下载链接
链接失效反馈官方服务:
资源简介:
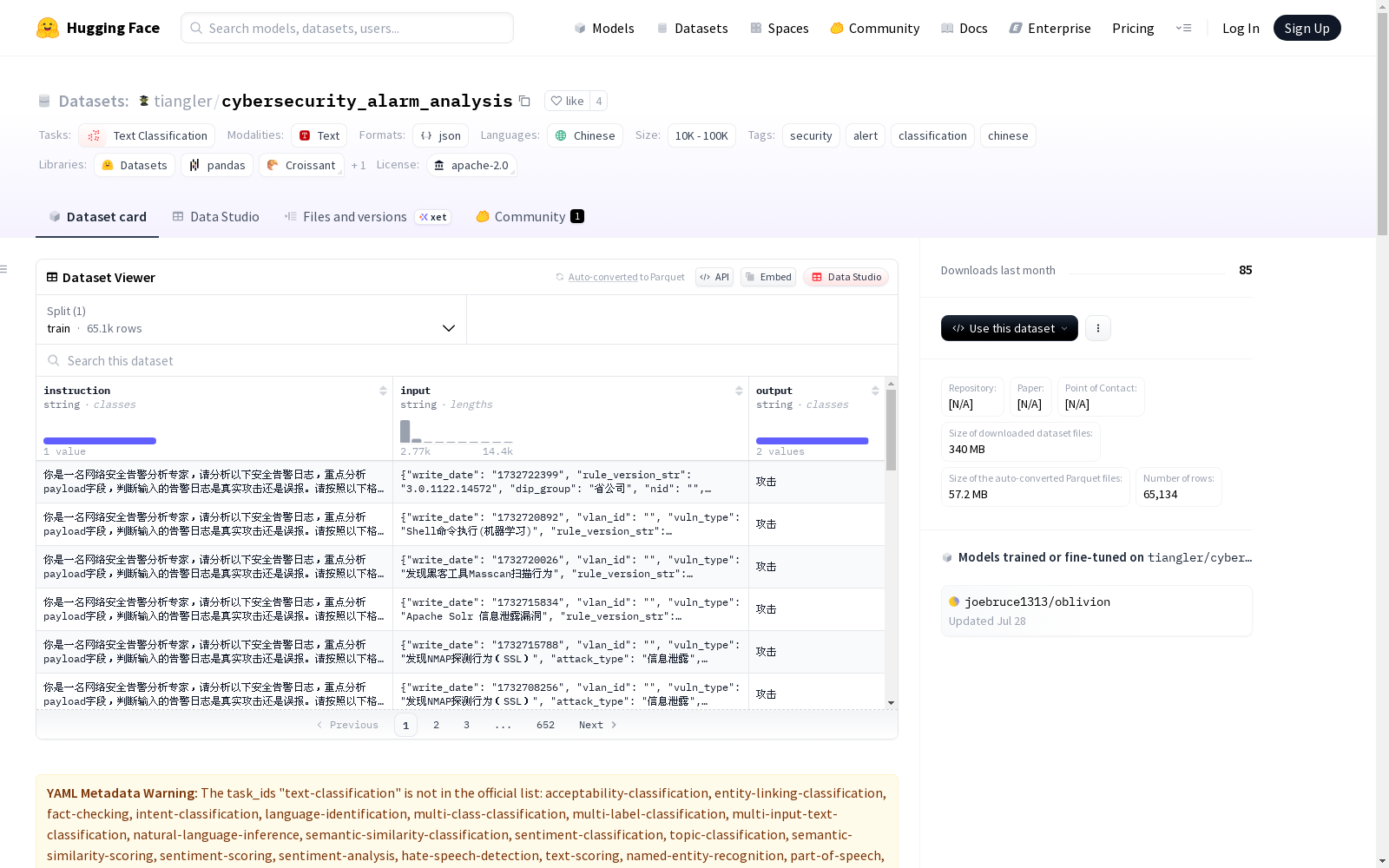
安全告警分类数据集,包含中文安全告警日志数据,用于训练模型进行安全告警的分类,区分攻击和误报。数据集采用Alpaca格式,每个样本包含任务说明、告警日志数据和分类标签。数据集规模在10K到100K之间,主要来源于中国网络环境的安全告警系统,由安全分析师进行标注。
This is a security alert classification dataset containing Chinese-language security alert log data, which is intended for training models to classify security alerts and differentiate between attacks and false positives. The dataset adheres to the Alpaca format, with each sample consisting of a task instruction, alert log data, and a classification label. The dataset size ranges from 10K to 100K samples, and it is mainly sourced from security alert systems in Chinese network environments, with annotations completed by security analysts.
创建时间:
2025-06-01
搜集汇总
数据集介绍
构建方式
在网络安全监测领域,该数据集通过系统化采集真实安全告警系统的日志记录构建而成。原始数据涵盖了SQL注入、命令执行、信息泄露等多种典型攻击类型的告警信息,由专业安全分析师对每条告警进行人工标注,区分真实攻击与误报情形。数据采用Alpaca指令微调格式进行结构化处理,形成包含任务指令、告警详情和分类标签的标准样本。
特点
该数据集呈现显著的中文网络安全文本特性,其告警日志以JSON格式完整保留了攻击类型、漏洞分类、危害等级等关键字段。数据规模达到六万余条,但存在极端类别不平衡现象,攻击样本占比不足0.5%,这精准反映了实际安防场景中误报频发的行业现状。数据集未对IP地址等敏感信息进行脱敏处理,保留了网络威胁分析的原始语境。
使用方法
使用者可通过加载标准化的指令-输入-输出三元组进行模型训练,其中指令字段明确要求模型扮演安全分析专家角色。输入层需解析包含多维度安全参数的JSON格式告警数据,输出层则对应二分类标签判断。针对数据不平衡问题,建议采用过采样或代价敏感学习等策略优化模型性能。该数据集适用于微调大语言模型在中文安全文本分类场景下的推理能力。
背景与挑战
背景概述
随着网络安全威胁日益复杂化,安全告警分析成为保障信息系统安全的关键环节。该数据集由安全分析师团队于近年构建,专注于解决安全运营中心面临的核心问题——高效区分真实攻击与系统误报。作为中文网络安全领域的重要资源,其采用Apache 2.0许可协议,包含6.5万余条标注样本,通过Alpaca结构化格式呈现,为基于大语言模型的智能安全分析提供了重要支撑。该数据集的出现显著推动了自动化威胁检测技术的发展,为减少安全运维中的人力资源浪费提供了数据基础。
当前挑战
在网络安全告警分类领域,核心挑战在于如何从海量嘈杂日志中精准识别极少数真实攻击。数据集构建过程中面临多重困难:原始数据存在极度类别不平衡,攻击样本占比仅0.45%,导致模型容易产生预测偏差;安全告警类型覆盖度有限,可能无法全面反映现实威胁场景;标注工作依赖安全分析师的主观判断,存在标注一致性风险。此外,数据集未对IP地址等敏感信息进行脱敏处理,且主要反映中国网络环境特征,这些因素都可能影响模型的泛化能力和实际部署效果。
常用场景
经典使用场景
在网络安全领域,安全告警分析是保障信息系统安全的核心环节。该数据集通过提供结构化的中文告警日志,支持模型学习区分真实攻击与误报,典型应用于构建智能告警分类系统,帮助自动化处理海量安全事件。
实际应用
在实际应用中,该数据集可集成到企业安全运营中心(SOC)的告警流水线中,辅助分析师快速筛选高优先级威胁。通过减少误报干扰,能够有效降低响应延迟,提升网络安全防护体系的整体效能。
衍生相关工作
基于该数据集的特性,衍生出多类经典研究,如结合过采样技术处理极端类别不平衡的分类模型、针对中文安全文本的预训练语言模型微调方法,以及融合多模态告警上下文的联合分析框架,这些工作进一步拓展了智能安全分析的边界。
以上内容由遇见数据集搜集并总结生成


