TMPAoDai
收藏Hugging Face2026-05-06 更新2026-05-07 收录
下载链接:
https://huggingface.co/datasets/multimedia-synergy-lab/TMPAoDai
下载链接
链接失效反馈官方服务:
资源简介:
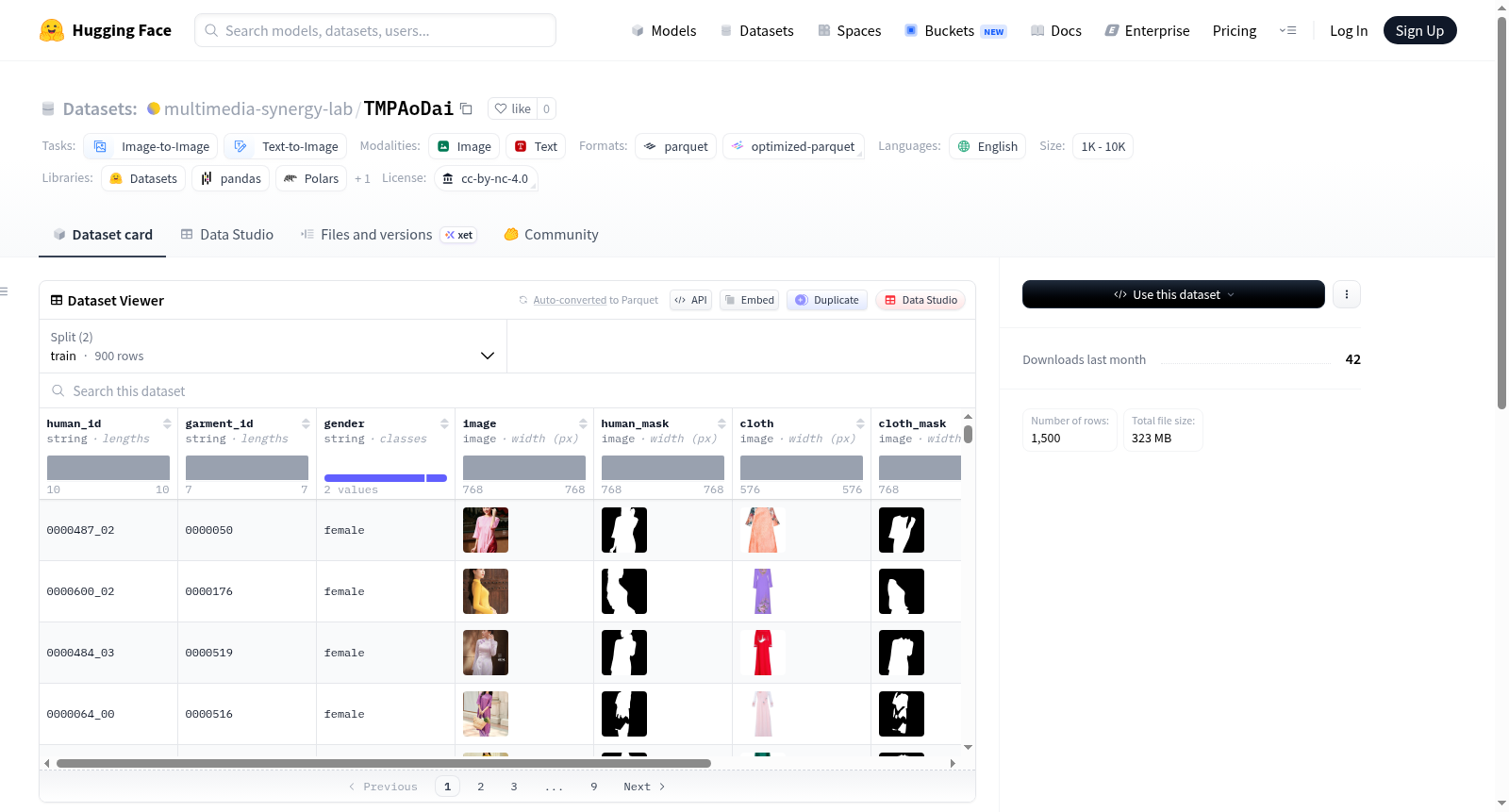
TMPAoDai是一个专为TMPAoDai研究设计的精选数据集,包含配对的真人图像、服装图像、分割掩码以及丰富的姿势描述。数据集采用cc-by-nc-4.0许可,语言为英语。数据集结构包括训练集和测试集,分别包含900和600个样本,总下载大小为322,713,554字节,数据集总大小为322,812,133字节。数据集特征包括人类ID、服装ID、性别、图像、人类掩码、服装、服装掩码、姿势和姿势描述。数据集适用于图像到图像和文本到图像任务,规模介于1K到10K之间。数据集目录结构包括姿势描述文件、图像目录、掩码目录以及训练和测试配对的CSV文件。
TMPAoDai is a curated dataset specifically designed for TMPAoDai research, containing paired real-person images, clothing images, segmentation masks, and rich pose descriptions. The dataset is licensed under cc-by-nc-4.0 and is in English. The dataset structure includes training and test sets, containing 900 and 600 samples respectively, with a total download size of 322,713,554 bytes and a total dataset size of 322,812,133 bytes. Dataset features include human ID, clothing ID, gender, image, human mask, clothing, clothing mask, pose, and pose description. The dataset is suitable for image-to-image and text-to-image tasks, with a scale between 1K and 10K. The dataset directory structure includes pose description files, image directories, mask directories, and CSV files for training and test pairs.
创建时间:
2026-05-06
原始信息汇总
TMPAoDai 数据集概述
基本信息
- 许可证:CC-BY-NC-4.0(非商业用途)
- 语言:英语
- 任务类型:图像到图像生成、文本到图像生成
- 数据规模:1K < n < 10K
数据集大小
- 总下载大小:322,713,554 字节
- 数据集总大小:322,812,133 字节
数据划分
| 划分 | 样本数量 | 大小(字节) |
|---|---|---|
| 训练集 | 900 | 192,212,650 |
| 测试集 | 600 | 130,599,483 |
数据特征
每条数据包含以下字段:
- human_id:人类身份标识(字符串)
- garment_id:服装身份标识(字符串)
- gender:性别(字符串)
- image:人类图像(图像类型)
- human_mask:人类分割掩码(图像类型)
- cloth:服装图像(图像类型)
- cloth_mask:服装分割掩码(图像类型)
- pose:姿态(字符串)
- pose_description:姿态描述(字符串)
数据集结构
dataset/ ├── pose_desc.csv # 姿态描述文件 ├── train/ # 训练集 │ ├── images/ # 人类图像 │ ├── human_masks/ # 人类掩码 │ ├── cloths/ # 服装图像 │ ├── cloth_masks/ # 服装掩码 │ └── train_pair.csv # 训练配对信息 └── test/ # 测试集 ├── images/ ├── human_masks/ ├── cloths/ ├── cloth_masks/ └── test_pair.csv
主要用途
该数据集专为TMPAoDai研究而构建,包含配对的人类图像、服装图像、分割掩码以及丰富的姿态描述,适用于图像到图像和文本到图像的生成任务。
搜集汇总
数据集介绍
构建方式
TMPAoDai数据集专为图像到图像及文本到图像的生成任务而设计,其构建过程精心且系统。数据集中每一样本均包含成对的人体全身图像与指定衣物图像,并辅以对应的分割掩码,包括人体掩码与衣物掩码。此外,数据集还收录了详细的姿态描述文本,这些描述通过分析姿态信息生成,从而为多模态学习任务提供了丰富的对齐信息。整体而言,该数据集通过整合视觉与文本模态,构建了一套高质量、结构化的配准样本集合。
特点
该数据集的一大显著特点在于其多维度、高一致性的数据结构。每一样本不仅包含原始图像与衣物图像,还提供了精准的分割掩码,这极大地便利了区域级图像生成与编辑任务。同时,姿态描述文本的引入,使得模型能够学习到姿态与外貌之间的关联,为文本驱动的图像生成提供了新的可能性。数据集的规模适中,训练集与测试集分别包含900和600个样本,总计1500个高质量对,平衡了数据丰富性与实验效率。
使用方法
使用TMPAoDai数据集时,研究者可依据其结构化目录轻松访问各模态数据。典型应用场景包括虚拟试衣、人物图像生成与编辑等。具体而言,用户可通过加载配对CSV文件获取样本索引,进而读取对应的人体图像、衣物图像及掩码。姿态描述文本可作为条件输入,用于指导生成模型的语义控制。该数据集支持多种任务范式,既可用于监督学习中的图像翻译,也可作为多模态生成模型的训练语料。
背景与挑战
背景概述
TMPAoDai数据集是由研究团队针对图像到图像及文本到图像生成任务构建的高质量资源,发布于近年,专注于越南传统服饰奥黛(Ao Dai)的虚拟试穿与生成研究。该数据集以细粒度的服装与人体配对数据为核心,包含900个训练样本和600个测试样本,每对数据涵盖人体图像、服装图像、分割掩码及详细的姿态描述,旨在推动跨模态生成模型在特定文化服饰场景下的性能提升。通过提供精确的掩码与姿态信息,TMPAoDai为研究人员探索语义对齐、服装迁移及姿态可控生成等前沿问题提供了标准化基准,对促进计算机视觉在文化遗产数字化与时尚科技领域的应用具有重要影响。
当前挑战
TMPAoDai所解决的领域挑战在于,现有通用虚拟试穿数据集多关注西方或现代服饰,缺乏针对特定文化服装(如奥黛)的精细化姿态与结构匹配数据,导致模型在处理复杂褶皱、非对称设计及传统纹样时泛化能力不足。构建过程中面临多重困难:首先,奥黛的贴身剪裁要求高精度的人体与服装分割掩码,人工标注成本极高且需专业服装知识;其次,多样化的站姿与动作使得姿态描述与图像对齐存在歧义,需设计统一的编码规则;最后,样本规模有限(不足1500对),如何在少量数据下避免过拟合并保证生成图像的细节保真度,成为技术落地的关键瓶颈。
常用场景
经典使用场景
TMPAoDai数据集在虚拟试衣与图像生成领域扮演着关键角色,其核心应用场景在于实现基于文本或图像的服装迁移任务。该数据集精心配对了人体图像、服装图像、分割掩码以及丰富的姿态描述,为研究者提供了从原始图像中精准提取服装、保留人体姿态并自然合成新着装的技术验证平台。经典使用方式包括利用条件生成对抗网络或扩散模型,以服装掩码和姿态描述为引导,生成穿着指定服装的逼真人体图像,从而推动图像到图像及文本到图像生成任务的发展。
解决学术问题
该数据集直面虚拟试衣领域数据匮乏与语义对齐困难的双重挑战,尤其解决了服装与人体姿态在复杂场景下的精准匹配问题。通过提供高精度的分割掩码和姿态描述,TMPAoDai助力学术研究攻克了服装变形、遮挡处理及纹理细节保留等核心难题。其意义在于为无监督或弱监督的服装迁移方法设立了标准化基准,促进了学者们在跨域图像合成与条件生成模型方面的理论突破,为后续研究构建了可复现、可比较的评估框架。
衍生相关工作
基于TMPAoDai数据集,衍生出一系列具有影响力的研究进展,包括面向服装形状保持的形变模拟算法、基于注意力机制的空间自适应生成模型,以及融合姿态关键点的可控虚拟试衣框架。这些工作分别从几何变换、语义对齐与多模态条件融合等角度深化了数据集的利用价值,推动了如VITON-HD和HR-VITON等前沿模型的改进迭代。该数据集的出现还激发了学者对少样本服装迁移与对抗性鲁棒性的探索,形成了以数据驱动为核心的研究生态。
以上内容由遇见数据集搜集并总结生成


