memelives-open-contributions
收藏Hugging Face2026-03-08 更新2026-03-09 收录
下载链接:
https://huggingface.co/datasets/qqder/memelives-open-contributions
下载链接
链接失效反馈官方服务:
资源简介:
MemeLives Open Contributions(模因永生・人類智慧文庫)是一个即将推出的AI原生人类智慧数据集,旨在通过引导式问答收集真人自愿贡献的结构化思想记录。数据集特别注重隐私保护,所有数据在离开设备前都经过个人可识别信息(PII)剥离和时间粗化处理,并通过Ed25519签名确保数据完整性。数据集包含多种记录类型,如问卷回答、文章、语音转录和铭文,每笔记录都包含丰富的元数据,如问题来源、回答内容、情感标签和质量评分等,适用于指令调优(SFT)、无配对偏好学习(KTO)、人格建模(Persona/Character AI)、价值观对齐(RLHF)和数字人文研究等应用场景。数据集以CC-BY-SA-4.0许可发布,未来将通过MemeLives iOS App收集用户贡献。
创建时间:
2026-02-26
原始信息汇总
MemeLives Open Contributions(模因永生・人類智慧文庫)数据集概述
数据集状态
- 当前状态:即将推出(Coming Soon),数据集目前为占位用途。
- 原因:MemeLives App 尚在开发中,未上架 App Store,目前尚无任何数据。
- 计划:待 App 上线且用户开始贡献后,本仓库将开始收录数据。
数据集简介
- 定位:世界上第一个 AI 原生的人类智慧数据集。
- 数据来源:非社交媒体爬取,而是真人在引导式问答中主动贡献的结构化思想记录。
数据集特点
- 结构:天然的 question → response pair,零清洗直接用于 SFT。
- 身份:密码学身份(BIP-39 → Ed25519),同一 author 的所有回答可重建完整 persona。
- 标签:原生语义分类(category、genre、question_source)。
- 深度:引导式深度问答 + AI 追问,挖掘真实价值观与人生经历。
- 多轮:支持 question → response → follow_up_question → follow_up_answer 结构。
- 合法性:使用者主动 opt-in + CC-BY-SA 4.0 + Ed25519 签名。
主要应用场景
- Instruction Tuning (SFT)
- Unpaired Preference Learning (KTO)
- Persona / Character AI
- Values Alignment (RLHF)
- Digital Humanities
数据描述与处理
- 数据性质:每一笔记录都是用户通过 MemeLives App 主动撰写并选择以 CC-BY-SA-4.0 授权公开的文字内容。
- 本地处理:所有数据在离开装置前皆经过以下处理:
- PII 剥离:移除姓名、地址、电话、身份证号等个人可识别信息。
- 时间粗化:日期精度降低至月份(YYYY-MM)。
- Ed25519 签署:每笔贡献由使用者的 BIP-39 衍生密钥签署,确保数据完整性。
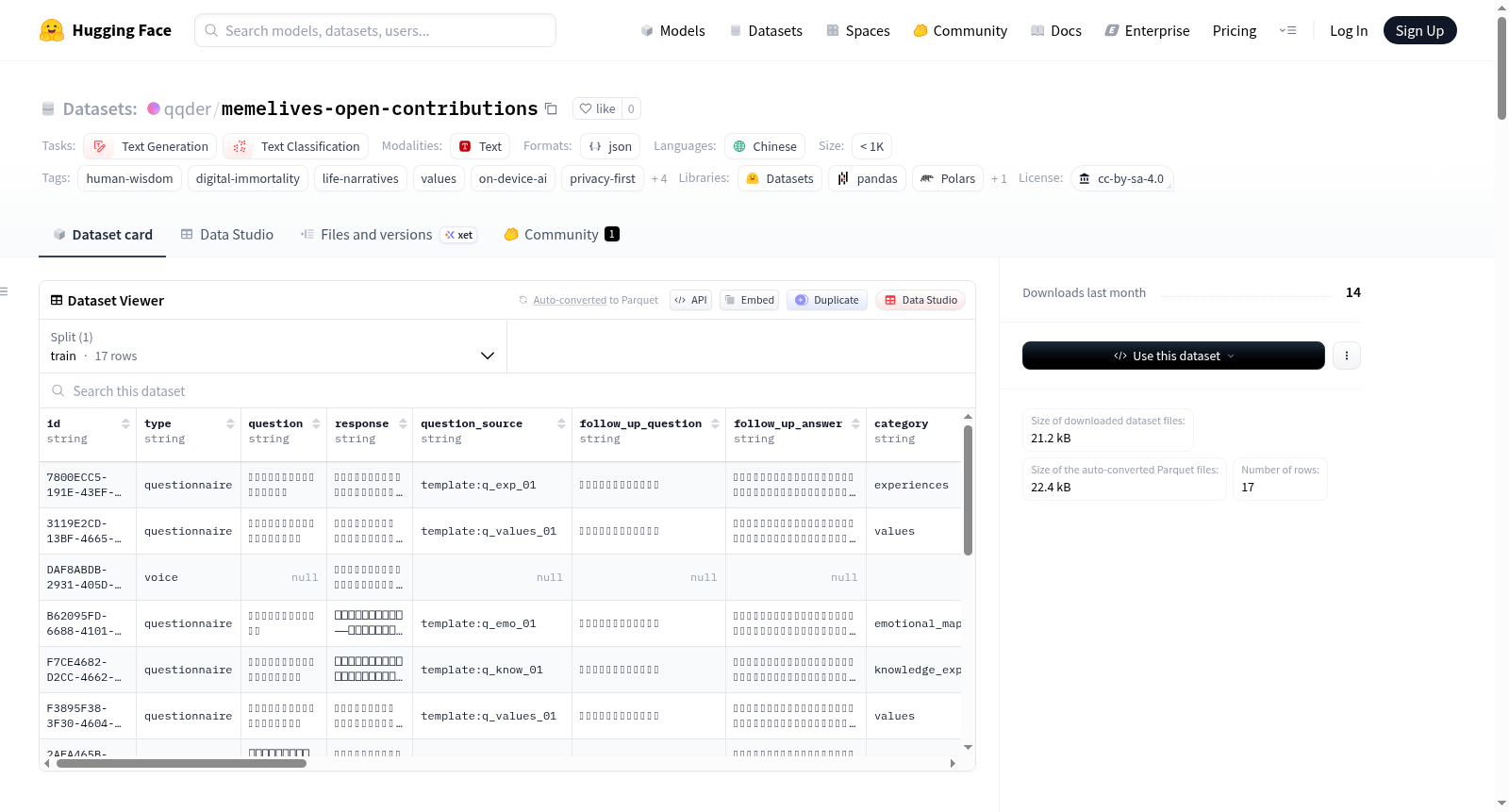
数据字段
| 字段 | 类型 | 说明 |
|---|---|---|
id |
string | 贡献 UUID |
type |
string | 来源类型:questionnaire、essay、voice、inscription(v2+) |
question |
string | null |
response |
string | PII 剥离后的回答/文字内容 |
question_source |
string | null |
follow_up_question |
string | null |
follow_up_answer |
string | null |
category |
string | 问卷类别:life_narrative、values、relationships 等 |
genre |
string | 文体:autobiography、fiction、essay、dialogue |
content_type |
string | null |
specificity |
string | null |
temporal_reference |
string | null |
quality_score |
float | null |
mood |
string | null |
emotion_intensity |
int | null |
word_count |
int | 字数 |
language |
string | BCP-47 语言码(如 zh-Hant) |
date |
string | 粗化后的日期(YYYY-MM) |
author |
object | 作者信息 |
author.id |
string | 作者 Meme ID(格式:meme_xxx) |
author.motto |
string | 作者座右铭(选填) |
author.epitaph |
string | 作者墓志铭(选填) |
author.mission |
string | 作者使命(v2+,选填) |
author.life_advice |
string | 作者箴言(v2+,选填) |
author.hardest_lesson |
string | 作者教训(v2+,选填) |
author.deepest_love |
string | 作者挚爱(v2+,选填) |
author.gratitude |
string | 作者感谢(v2+,选填) |
author.message_to_future |
string | 作者留言(v2+,选填) |
annotation_version |
int | 标注版本(0 = 未标注,1+ = 已标注) |
record_schema_version |
int | 该笔记录写入时的 schema 版本(1 或 2) |
schema_version |
int | 汇出脚本的 schema 版本(目前为 2) |
exported_at |
string | 汇出时间(ISO 8601 UTC) |
signature |
string | Ed25519 签名(格式:ed25519:hex) |
结构化 Q&A 设计
- 设计目的:question/response 分离设计。
- 适用场景:
- Instruction tuning:question → response 为天然的 instruction-output pair。
- Persona modeling:同一 author 的多笔 Q&A 可重建思维模式。
- Values alignment:category + question_source 提供语义分类。
- Multi-turn dialogue:follow_up_question + follow_up_answer 扩展对话深度。
训练元数据
- 用途:每笔记录包含由装置端 AI 自动标注的训练元数据,可直接用于数据筛选和训练管线。
- 关键字段与用途:
content_type:区分事实/观点/轶事/反思/说明,控制 SFT 训练分布。specificity:过滤泛泛内容,优先使用深度个人记录。temporal_reference:叙事结构分析,平衡过去/未来导向的回答。quality_score:LIMA 启发的品质过滤(建议阈值 ≥ 0.4),也可作为 KTO implicit 偏好信号。mood+emotion_intensity:Plutchik 8 情绪标注 + 强度,控制情绪分布。
- 训练格式:
- SFT 格式:每笔记录可直接转换为 OpenAI messages 格式
{"messages": [{role, content}]}。 - KTO 格式(无配对偏好学习):
quality_score >= 0.6→ positive,0.3–0.6→ negative,< 0.3→ skip。
- SFT 格式:每笔记录可直接转换为 OpenAI messages 格式
隐私保护
- 本地处理:所有 AI 处理皆在用户装置本地执行(Apple Foundation Models + on-device LLM)。
- 数据收集:不收集任何用户数据——App 不追踪、不分析使用行为。
- 用户权利:用户可随时在 App 中撤回公开贡献。
- 地理位置:无 GPS 追踪——地点为用户自行输入的文字描述。
- 身份识别:仅通过 BIP-39 助记词衍生的密码学密钥,无账号系统。
授权条款
- 许可证:CC-BY-SA-4.0 (https://creativecommons.org/licenses/by-sa/4.0/)。
数据来源
数据由 MemeLives iOS App 用户通过以下方式产生:
- 文字书写
- 语音录入(本地 Whisper 转录)
- 结构化问卷回答
Schema 版本历史
- 版本追踪:使用语义版本号追踪 schema 演进。每笔记录带有
record_schema_version(写入时版本)和schema_version(汇出时版本)。 - 版本固定:可通过 HuggingFace git tag 固定版本(例如:
load_dataset("qqder/memelives-open-contributions", revision="v2"))。
v2(目前)
- 铭文字段扩展:
author对象新增 6 个选填字段(mission、life_advice、hardest_lesson、deepest_love、gratitude、message_to_future)。 - 新记录类型:
type: "inscription"—— 用户主动刻写的结构化短宣言,4 类别 × 2 项 = 8 项铭文。- 信念:座右铭、使命。
- 智慧:箴言、教训。
- 牵挂:挚爱、感谢。
- 永恒:墓志铭、留言。
- 向后相容:v1 记录的
author仅含id、motto、epitaph,新字段不存在。
v1(初始)
- 基础 schema:entries、questionnaire responses、training metadata。
- 作者对象:
author对象包含id、motto、epitaph。
引用信息
如使用本数据集,请引用: bibtex @dataset{memelives_open_contributions, title={MemeLives Open Contributions}, author={MemeLives Contributors}, year={2026}, url={https://huggingface.co/datasets/qqder/memelives-open-contributions}, license={CC-BY-SA-4.0} }
搜集汇总
数据集介绍
构建方式
在数字人文与人工智能交叉领域,MemeLives Open Contributions数据集开创了一种全新的构建范式。它并非通过传统网络爬虫从社交媒体中被动抓取,而是通过一款名为MemeLives的移动应用,引导真实用户以结构化问答形式主动贡献其思想与人生叙事。数据采集过程严格遵循隐私优先原则,所有处理均在用户设备本地完成,包括语音转录与初步标注。用户在明确同意CC-BY-SA-4.0许可协议后,其经过个人可识别信息剥离和时间粗化处理的回答,会通过基于BIP-39助记词衍生的Ed25519密钥进行密码学签名,确保数据来源的真实性与完整性,最终汇集成这份AI原生的人类智慧记录。
特点
该数据集的核心特征在于其高度结构化与丰富的元数据标注。每条记录天然构成“问题-回答”对,可直接用于指令微调,免除了传统文本清洗的繁琐步骤。其独特之处在于引入了密码学身份系统,使得同一作者的多条贡献能够关联起来,为构建连贯的人格图谱提供了可能。数据集内置了精细的语义分类标签,如内容类别、文体、情绪及质量评分,这些元数据均由设备端人工智能自动生成,为模型训练提供了多维度的筛选与控制信号。此外,部分记录还包含AI追问产生的多轮对话,进一步挖掘了回答的深度与上下文。
使用方法
该数据集为多种人工智能训练范式提供了即用型数据支持。对于指令微调,其结构化的问答对可直接转换为消息格式用于监督微调。在偏好学习方面,记录中的质量评分可作为隐式偏好信号,无需人工配对即可用于KTO等无配对偏好学习算法。研究者可利用密码学身份字段,聚合同一作者的多条记录,用于训练具有一致人格的角色AI或智能体。丰富的分类标签便于进行数据筛选,例如基于价值观类别进行对齐研究,或根据情绪标签平衡训练数据的情感分布。数据集采用语义化版本管理,使用者可通过指定修订版号加载特定模式版本的数据以确保实验可复现性。
背景与挑战
背景概述
在数字人文与人工智能交叉领域,如何构建高质量、富含人类深层智慧与价值观的文本数据,是推动个性化AI与价值对齐研究的关键。MemeLives Open Contributions数据集应运而生,作为世界上首个AI原生的人类智慧数据集,它由MemeLives项目团队于2026年前后发起并构建。该数据集的核心研究问题聚焦于通过结构化的引导式问答,主动采集真实个体的人生叙事、价值观与深度反思,旨在为指令微调、人格建模及价值对齐等前沿任务提供稀缺的中文深度对话资源。其创新性地采用密码学身份与本地化隐私保护设计,不仅为数字永生与文化遗产保存提供了新范式,也对促进具有连贯人格图谱的AI智能体发展产生了潜在影响力。
当前挑战
该数据集旨在解决构建富含人类深层智慧与连贯人格的AI训练数据这一领域核心挑战,具体包括如何超越社交媒体浅层文本,系统性地挖掘并结构化记录个体的价值观、人生经历与情感深度。在构建过程中,团队面临多重技术与社会挑战:首要挑战在于设计既能引导深度表达又能保护用户隐私的交互机制,确保数据在离开设备前完成个人可识别信息剥离与时间粗化;其次,建立基于密码学身份(BIP-39 → Ed25519)的数据完整性验证与跨记录人格图谱重建体系,在匿名性与人格连贯性之间取得平衡;此外,开发适用于设备端的自动化标注流程(如质量评分、情绪分类),以生成可直接用于SFT、KTO等训练流程的元数据,同时应对数据规模初期较小、需持续吸引用户自愿贡献以保障数据多样性与代表性的长期挑战。
常用场景
经典使用场景
在人工智能与数字人文的交叉领域,MemeLives Open Contributions数据集以其独特的结构化问答设计,为指令微调提供了天然的高质量语料。每一笔记录都包含清晰的提问与回答对,无需额外清洗即可直接应用于监督微调,有效解决了中文深度对话数据稀缺的瓶颈。其多轮追问机制进一步拓展了对话的深度与连贯性,使得模型能够学习到更复杂、更具上下文关联的人类思维模式。
实际应用
在实际应用层面,该数据集为开发个性化、高隐私保护的AI助手提供了关键支持。基于同一密码学身份下的多轮问答,可以训练出具有独特人格和记忆的对话代理,应用于陪伴型机器人、个性化教育或心理辅导等场景。其严格的隐私保护设计,包括设备端处理和PII剥离,确保了在医疗健康、个人传记记录等敏感领域应用时的合规性与安全性,实现了技术实用性与伦理规范的平衡。
衍生相关工作
围绕该数据集的结构与理念,已衍生出多个方向的前沿探索。在模型训练方法上,其质量评分字段为无配对偏好学习算法提供了直接的隐式信号,推动了如KTO等高效对齐技术的发展。在数字人文领域,它启发了基于大规模个人叙事的口述历史与文化变迁量化研究。同时,其密码学身份与结构化铭文的设计,也为构建去中心化的数字遗产与人格永续系统提供了重要的技术原型与数据范式。
以上内容由遇见数据集搜集并总结生成


