SigmaLaw-ABSA
收藏arXiv2020-11-12 更新2024-06-21 收录
下载链接:
https://osf.io/37gkh/
下载链接
链接失效反馈官方服务:
资源简介:
SigmaLaw-ABSA是由莫拉图瓦大学计算机科学与工程系创建的法律意见文本方面的情感分析数据集,包含2000条英文法律意见文本,由人类法官手动标注。该数据集旨在支持法律领域的方面情感分析研究,解决自动从法律文本中提取信息的需求。数据集内容包括法律案例中的不同方面及其情感极性,适用于深度学习模型在法律文本情感分析中的应用。
SigmaLaw-ABSA is an aspect-based sentiment analysis (ABSA) dataset focused on legal opinion texts, developed by the Department of Computer Science and Engineering of the University of Moratuwa. It consists of 2000 English legal opinion texts manually annotated by human judges. This dataset is designed to facilitate aspect-based sentiment analysis research in the legal domain, addressing the demand for automated information extraction from legal texts. The dataset encompasses various aspects and their corresponding sentiment polarities within legal cases, and is suitable for applying deep learning models to sentiment analysis tasks on legal texts.
提供机构:
莫拉图瓦大学计算机科学与工程系
创建时间:
2020-11-12
搜集汇总
数据集介绍
构建方式
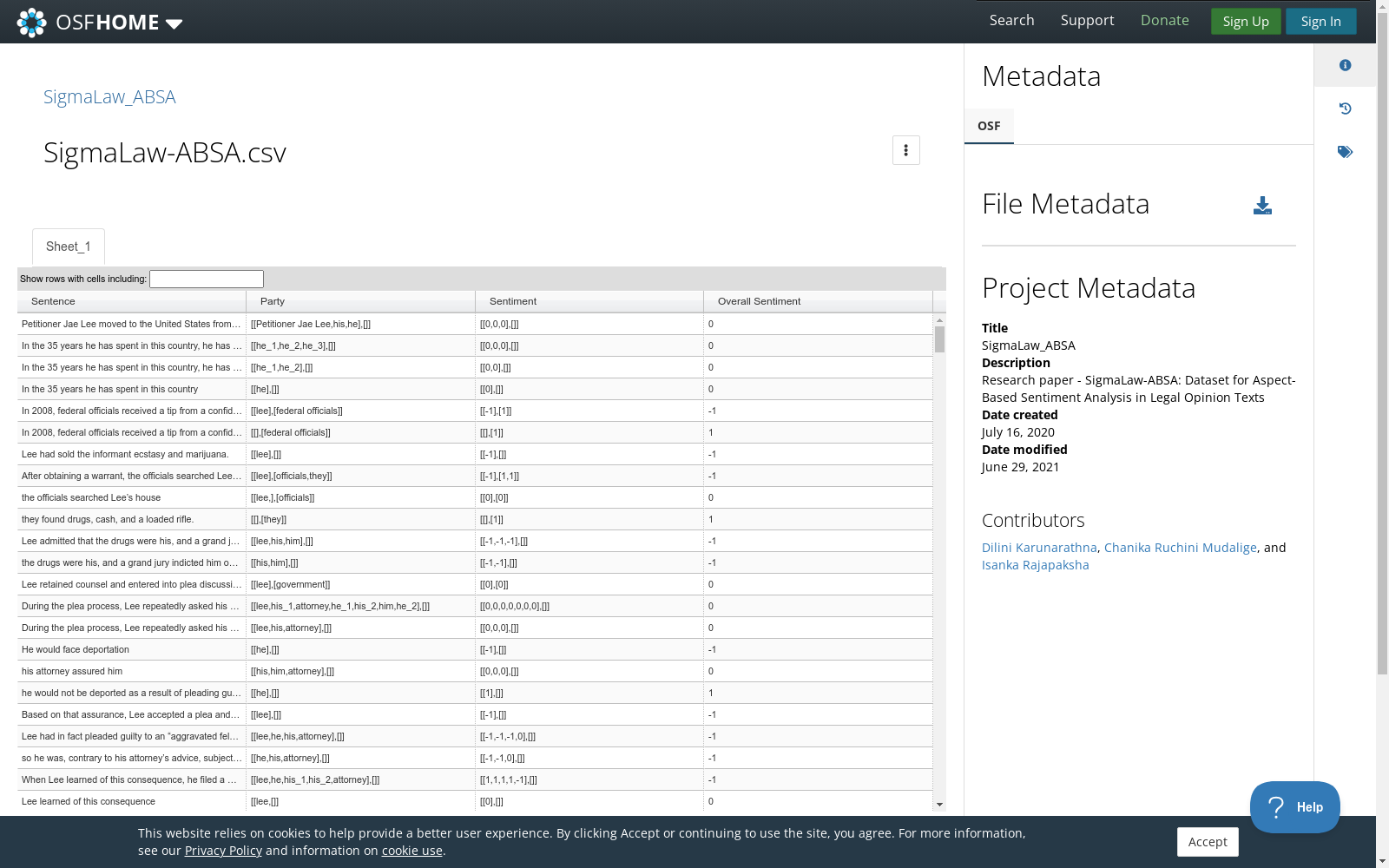
SigmaLaw-ABSA数据集的构建主要围绕法律意见文本的方面情感分析任务。数据集的构建始于从SigmaLaw-Large Legal Text Corpus and Word Embeddings数据集中收集案例,该数据集包含来自美国最高法院的大量法律案例。研究者选取了约2000个句子进行标注,其中包括完整的句子和从原句中提取的有意义的子句。为了确保标注的一致性,三位法律专业的本科生和研究生参与了标注过程,他们负责确定每个方面的类别和情感标签。标注过程中,使用Fleiss'kappa系数来评估标注者之间的一致性,结果显示标注者之间的一致性达到了中等水平。
特点
SigmaLaw-ABSA数据集的特点在于其专门针对法律领域的方面情感分析任务。数据集包含2000个句子,其中既有完整的句子也有从原句中提取的有意义的子句。这些句子覆盖了正、负、中三种情感极性。数据集的标注内容丰富,包括实体、情感极性、方面类别(原告和被告)以及类别极性等信息。数据集的设计旨在支持多任务研究,包括方面提取、极性检测、方面类别识别和方面类别极性检测等。
使用方法
使用SigmaLaw-ABSA数据集的方法主要涉及方面情感分析的核心子任务。首先,研究者可以利用数据集进行方面提取任务,识别句子中属于任何法律方面的所有人员或组织。其次,数据集支持方面术语极性任务,为从方面提取任务中提取的方面分配情感值。此外,数据集还支持方面类别提取任务,将提取的方面分类为原告或被告。最后,数据集允许进行方面类别极性任务,为句子的方面类别分配情感值。研究者可以根据这些子任务进行模型训练和评估,以研究法律文本中不同方面的情感倾向。
背景与挑战
背景概述
SigmaLaw-ABSA数据集是一项开创性的工作,专注于法律意见文本中的方面情感分析(Aspect-Based Sentiment Analysis,ABSA)。该数据集由斯里兰卡莫拉图瓦大学计算机科学与工程学院和科伦坡大学法学院的研究团队于2020年创建。这一研究旨在填补法律领域中ABSA数据集的空白,因为在此之前,尚无公开可用的数据集用于此目的。SigmaLaw-ABSA数据集由人工标注的法律意见文本组成,包含英文句子,并由法官进行标注。该数据集的核心研究问题在于如何从法律意见文本中提取出不同法律当事人(方面)的情感倾向,并对此进行分类。这一研究对于提高法律信息提取的自动化程度具有重要意义,有助于法律专业人士更高效地处理案件。该数据集的创建对法律领域的ABSA研究产生了深远影响,为后续相关研究提供了宝贵的数据资源。
当前挑战
SigmaLaw-ABSA数据集面临着一些挑战。首先,法律意见文本通常较长,语义结构复杂,这使得数据标注过程变得较为困难。其次,法律领域中的术语和表达方式具有特定性,需要标注者具备一定的法律知识背景。此外,法律意见文本中可能存在多个法律当事人,且每个当事人的情感倾向可能不尽相同,这增加了ABSA任务的复杂性。最后,由于法律意见文本的公开性受限,获取大量标注数据存在一定难度。为了应对这些挑战,研究团队采取了人工标注的方式,并利用了斯坦福CoreNLP库中的依存句法分析器来生成有意义的子句子。同时,研究团队还引入了多项式卡方系数来评估标注者之间的可靠性。通过这些方法,SigmaLaw-ABSA数据集成功地解决了法律领域ABSA研究中的一些关键问题,为后续研究提供了重要的数据基础。
常用场景
经典使用场景
在法律领域,情感分析(SA)的应用尚不广泛,但其在法律意见文本中的应用具有显著的重要性。SigmaLaw-ABSA数据集是一个为Aspect-Based Sentiment Analysis(ABSA)任务而创建的公开数据集,它包含了由人类法官标注的英语法律意见文本。该数据集旨在帮助研究人员在法律领域进行ABSA任务,包括方面提取、极性检测、方面类别识别和方面类别极性检测。该数据集包含了2000个句子,包括1007个完整句子和993个子句子,涵盖了正、负和中性情感。SigmaLaw-ABSA数据集为研究人员提供了一个在法律领域进行ABSA任务的平台,并有助于推动法律文本信息提取的自动化进程。
实际应用
SigmaLaw-ABSA数据集在实际应用中具有广泛的应用前景。首先,该数据集可以帮助法律专业人士快速准确地识别法律文本中各个当事人的情感,从而更有效地处理法律案件。其次,该数据集还可以用于开发法律领域的自然语言处理(NLP)工具,如法律文本自动摘要、法律意见文本分类等。此外,SigmaLaw-ABSA数据集还可以为法律教育提供支持,帮助学生更好地理解和分析法律文本。
衍生相关工作
SigmaLaw-ABSA数据集的创建为法律领域的ABSA研究开辟了新的方向。基于该数据集,研究人员可以开发更精确的ABSA模型,以提高法律文本信息提取的准确性。此外,SigmaLaw-ABSA数据集还可以与其他领域的ABSA数据集进行比较,以探究不同领域ABSA任务的异同。此外,该数据集还可以用于开发新的NLP任务,如法律文本中的实体识别、关系抽取等。
以上内容由遇见数据集搜集并总结生成


