louisbrulenaudet/code-electoral
收藏Hugging Face2024-07-21 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/louisbrulenaudet/code-electoral
下载链接
链接失效反馈官方服务:
资源简介:
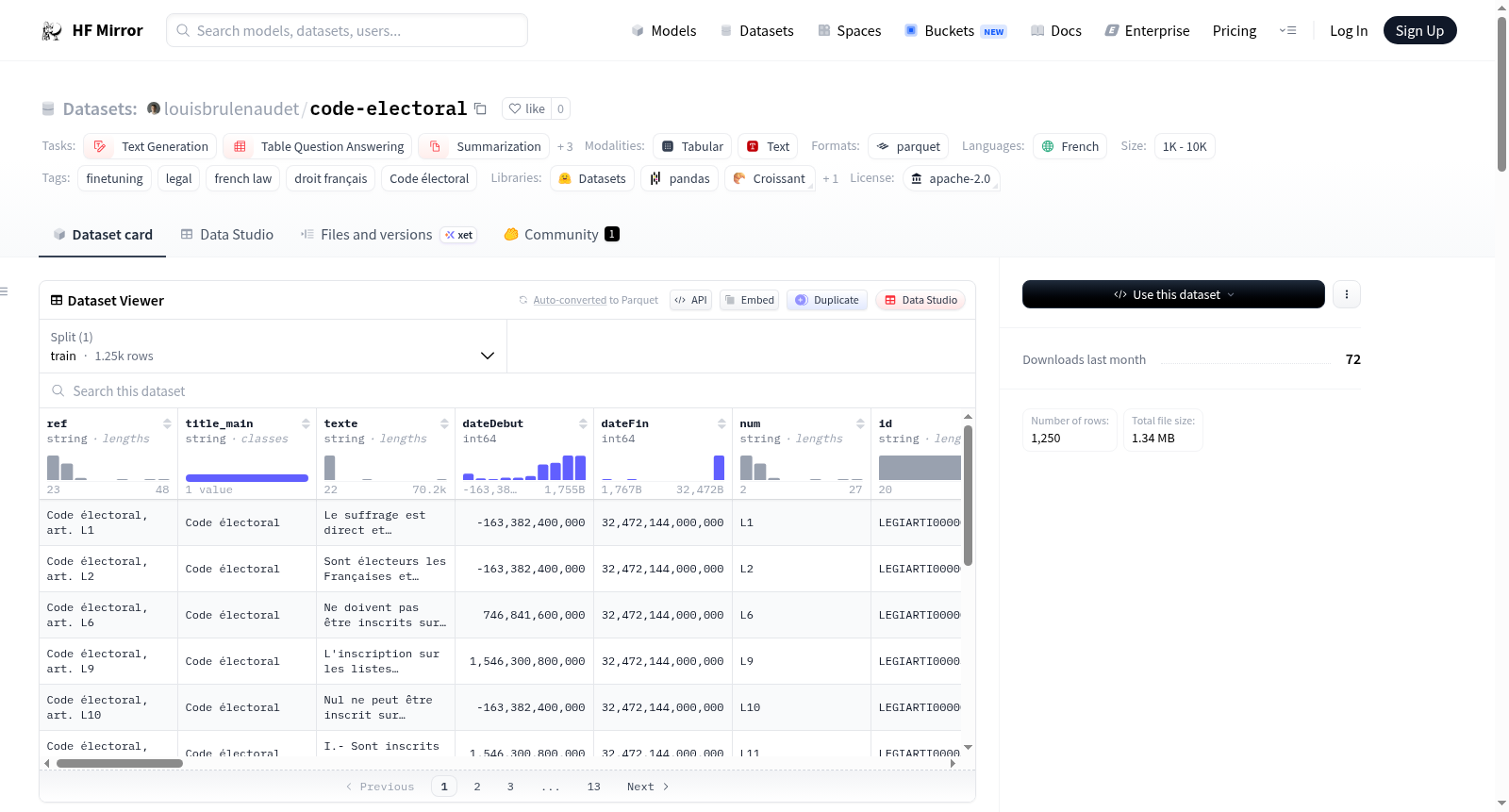
该数据集名为Code électoral,专注于通过微调预训练语言模型来创建高效且准确的法律实践模型。数据集包含与法国选举法相关的文本数据,适用于多种NLP任务,如文本生成、表格问答、摘要生成、文本检索、问答和文本分类。数据集的生成基于一系列指令,这些指令用于指导模型生成与法律条文相关的内容。数据集的结构为JSON格式,每个条目包含指令、输入、输出、生效日期、过期日期和文章编号等信息。
This dataset, named Code électoral, focuses on fine-tuning pre-trained language models to create efficient and accurate models for legal practice. It contains text data related to French electoral law and is suitable for various NLP tasks such as text generation, table question answering, summarization, text retrieval, question answering, and text classification. The dataset is generated based on a series of instructions that guide the model to produce content related to legal provisions. The dataset is structured in JSON format, with each entry containing fields such as instruction, input, output, start date, expiration date, and article number.
提供机构:
louisbrulenaudet
原始信息汇总
数据集概述
名称: Code électoral
许可证: Apache-2.0
语言: 法语
多语言性: 单语种
标签:
- 微调
- 法律
- 法国法律
- 法国选举法
任务类别:
- 文本生成
- 表格问答
- 摘要
- 文本检索
- 问答
- 文本分类
规模: 1K<n<10K
数据集生成:
- 数据集由一系列JSON格式文件组成,每个文件包含多个字典,字典包含以下字段:
instruction: 字符串,与元素相关的指令。input: 字符串,元素的输入细节。output: 字符串,元素的输出信息。start: 字符串,文章生效日期。expiration: 字符串,文章失效日期。num: 字符串,文章ID。
生成指令:
- 用于生成数据集的指令包括多种形式,主要涉及文章全文的撰写和内容描述。
搜集汇总
数据集介绍
构建方式
在法国法律文本数字化进程中,该数据集通过自动化采集与结构化处理构建而成。其核心来源为法国官方法律数据库,每日进行动态更新,确保条文时效性。构建流程采用标准化解析技术,将原始法律条文转化为机器可读的JSON格式,并嵌入丰富的元数据字段,如条文生效日期、法律状态及版本历史等。同时,通过RAGoon工具链实现多法典数据的并行加载与整合,为后续研究提供一致的数据接口。
使用方法
研究者可通过Hugging Face平台直接加载该数据集,或利用配套的RAGoon工具进行批量获取与多法典合并。数据适用于文本生成、问答系统、分类与检索等多种自然语言处理任务,尤其适合用于法律领域微调语言模型。使用时可依据`ref`、`dateDebut`等字段进行筛选,结合`sectionParentTitre`等层级信息构建知识图谱。为保障应用效果,建议结合法律领域预训练模型进行迁移学习。
背景与挑战
背景概述
在数字化法律文献与自然语言处理技术融合的背景下,louisbrulenaudet/code-electoral数据集应运而生,由研究者Louis Brulenaudet于2025年构建。该数据集专注于法国《选举法典》的文本资源,旨在为研究人员、法律从业者及学生提供结构化、实时更新的法律条文访问途径。其核心研究问题在于如何将复杂的法律文本转化为机器可读的格式,以支持法律信息检索、文本生成及问答系统等任务,从而推动法律人工智能在法语社区的发展,并为欧洲一体化项目中的法律数据整合提供基础支撑。
当前挑战
该数据集致力于解决法律文本处理领域的多重挑战,包括法律语言的精确性要求、条文间的复杂关联性解析,以及动态法律修订的追踪难题。在构建过程中,挑战主要体现在法律文本的异构性整合,需从原始资料中提取并标准化大量元数据字段,如条文生效日期、法律状态及版本历史;同时,确保数据每日更新的时效性与一致性,并维护HTML与纯文本格式的并行处理,以支持多样化的下游任务,这对数据管道的鲁棒性与自动化水平提出了较高要求。
常用场景
经典使用场景
在法国法律信息学领域,该数据集为研究者提供了结构化的选举法典文本,其经典应用场景聚焦于自然语言处理任务。通过整合条文内容、生效日期、法律状态等元数据,该数据集支持对法律条文进行自动解析与语义理解,常用于训练法律文本生成模型或构建智能问答系统,以模拟法律专业人士对选举法规的检索与解释过程。
解决学术问题
该数据集有效应对了法律文本数字化中的若干学术挑战,特别是解决了法语法律条文因版本更迭频繁而导致的时效性缺失问题。通过提供每日更新的条文及其历史版本,数据集支持法律演变追踪研究,并为法律信息检索、自动摘要及跨条文关联分析等任务奠定数据基础,推动了计算法学在选举法细分领域的发展。
实际应用
在实际应用层面,该数据集可被集成至法律科技平台,辅助律师、政府机构及公民快速查询选举法规。例如,基于该数据集构建的智能助手能够解答关于候选人资格、选举程序或竞选资金规定的具体问题,提升法律服务的可及性与效率。同时,其结构化格式也便于与欧盟法律数据库对接,支持跨国法律合规性分析。
数据集最近研究
最新研究方向
在法国法律文本数字化与自然语言处理交叉领域,louisbrulenaudet/code-electoral数据集作为《选举法典》的结构化资源,正推动法律智能的前沿探索。该数据集凭借其每日更新的动态特性与丰富的元数据架构,为法律文本的时序分析、版本追踪及跨条文关联研究提供了坚实基础。当前研究热点聚焦于利用该数据集训练领域专用大语言模型,以支持法律问答、条文摘要、跨法典信息检索等任务,同时其与欧洲立法标识符(ELI)的集成,促进了跨国法律数据的互操作性与比较法研究。这一进展不仅提升了法律从业者的信息处理效率,也为政策模拟、合规自动化等应用开辟了新路径,彰显了开放数据在法律科技生态中的核心价值。
以上内容由遇见数据集搜集并总结生成


