Small Business Administrations PPP loan dataset
收藏github2023-12-11 更新2024-05-31 收录
下载链接:
https://github.com/rosehemans/Niyam-IT-PPP-Anomaly-Detection
下载链接
链接失效反馈官方服务:
资源简介:
与IT服务公司Niyam IT合作的咨询项目,使用高级异常检测建模分析小企业管理局的PPP贷款数据集,以识别潜在的欺诈行为。
A consulting project in collaboration with IT service company Niyam IT, utilizing advanced anomaly detection modeling to analyze the Small Business Administration's PPP loan dataset for the identification of potential fraudulent activities.
创建时间:
2023-11-19
原始信息汇总
数据集概述
基本信息
- 开发组织: GWU MSBA 与 Niyam IT
- 开发者:
- GWU MSBA: Rose Hemans, Bagya Maduwanthi Widanagamage, Kaixuan (Kevin) Han, Pavneet Singh
- Niyam IT: Rohit Bollineni
- 模型日期: 2023年11月
- 模型版本: 1.0
- 许可证: MIT
- 模型实现代码: Notebooks
预期用途
- 主要用途: 作为端到端异常检测建模过程的示例,用于指导当前和未来的异常检测模型。
- 主要用户: Niyam IT, Patrick Hall, GW MSBA DNSC 6317班学生
- 超出范围的使用: 任何超出教育示例的使用均不在范围内。
训练数据
- 数据字典: 包含多个变量,如LoanNumber, ProcessingMethod, BorrowerCity, BorrowerState等,用于模型训练。
模型详情
- 模型类型:
- Scikit-Learn Library Isolation Forest Model
- H2O Library Isolation Forest Model
- Pandas Average Risk Score Model
探索性数据分析
- 分析内容:
- 通用探索性数据分析
- AVR模型探索性数据分析
- scikit-learn Isolation Forest模型探索性数据分析
- H2O IF模型探索性数据分析
- 最终混合模型探索性数据分析
考虑事项和下一步
- 考虑事项:
- 伦理考虑
- 风险考虑
- 潜在的下一步: 未具体说明。
搜集汇总
数据集介绍
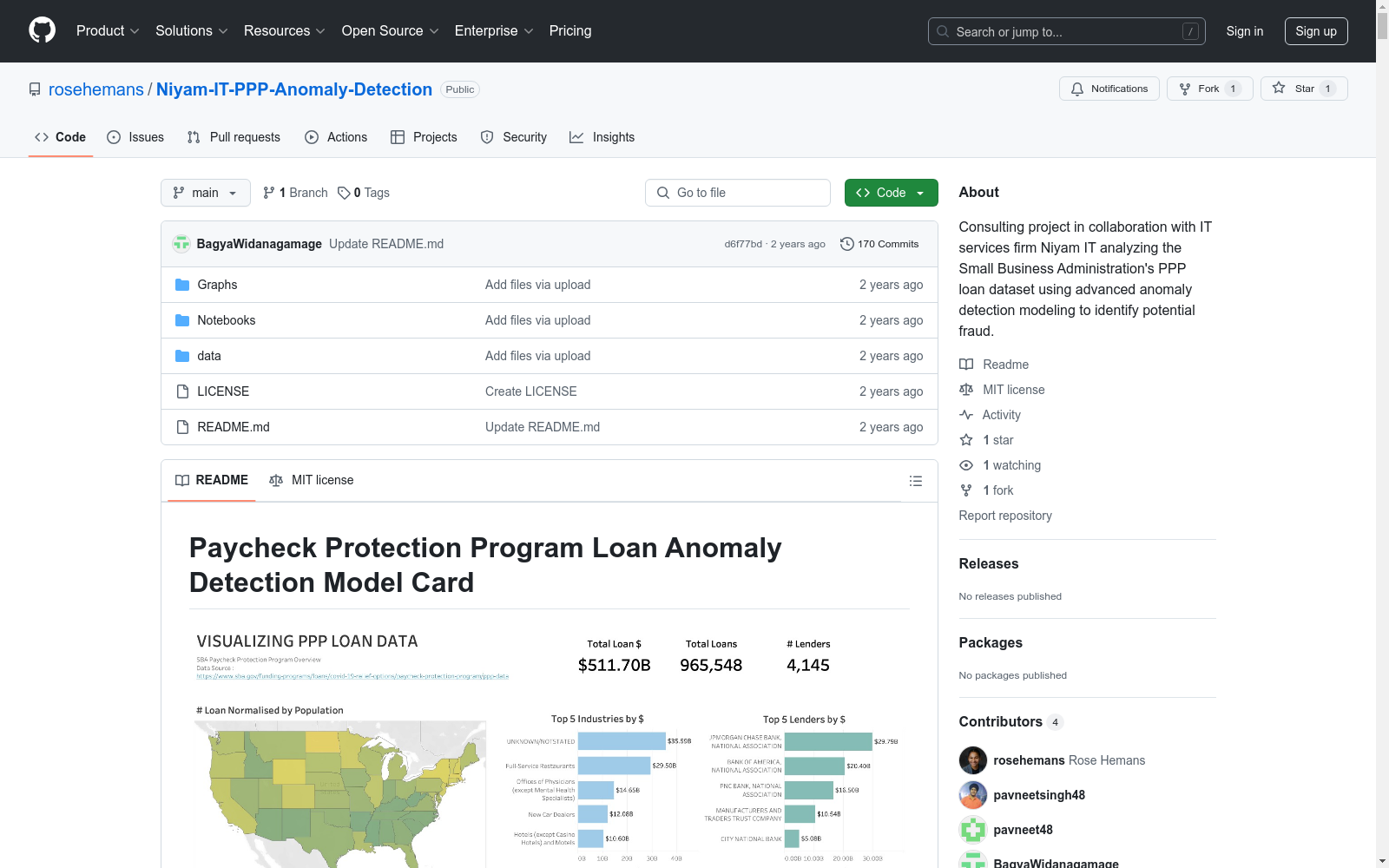
构建方式
该数据集基于美国小企业管理局(SBA)的薪资保护计划(PPP)贷款数据构建,旨在检测贷款中的异常行为。数据来源包括贷款审批记录、借款人信息、贷款用途及还款状态等多维度信息。通过数据清洗和特征工程,提取了与贷款金额、用途、借款人地理位置等相关的关键变量,并生成了多个衍生特征,如每员工贷款金额、预期收益等,以支持异常检测模型的训练。
特点
该数据集涵盖了丰富的贷款相关信息,包括贷款金额、借款人地理位置、贷款用途、还款状态等。其独特之处在于通过衍生特征(如每员工贷款金额、预期收益等)增强了数据的分析能力。此外,数据集还包含了多个异常检测模型所需的输入特征,如风险评分、偏差值等,为异常检测提供了多维度的支持。数据集的结构清晰,特征定义明确,适合用于机器学习模型的训练与评估。
使用方法
该数据集主要用于异常检测模型的训练与评估。用户可以通过加载数据集,结合Scikit-Learn、H2O等机器学习库,构建并优化异常检测模型。数据集中提供的特征可直接用于模型输入,用户还可根据需求进一步扩展特征工程。通过探索性数据分析(EDA),用户可以深入了解数据分布与异常模式,从而优化模型性能。此外,数据集还可用于教育目的,帮助学习者理解异常检测模型的构建流程。
背景与挑战
背景概述
Small Business Administrations PPP loan dataset 是由乔治华盛顿大学(GWU)MSBA项目与Niyam IT合作开发的数据集,旨在支持薪资保护计划(PPP)贷款异常检测模型的构建。该数据集于2023年11月发布,主要研究人员包括Rose Hemans、Bagya Maduwanthi Widanagamage、Kaixuan (Kevin) Han、Pavneet Singh以及Rohit Bollineni。数据集的核心研究问题是通过分析PPP贷款数据,识别潜在的异常行为,从而帮助监管机构和企业更好地管理贷款风险。该数据集在金融科技和公共政策领域具有重要影响力,为异常检测算法的开发提供了宝贵的数据支持。
当前挑战
该数据集在解决PPP贷款异常检测问题时面临多重挑战。首先,贷款数据的复杂性和多样性使得异常行为的定义和识别变得困难,尤其是在涉及多维度特征(如贷款金额、用途、借款人信息等)时。其次,数据集中存在大量缺失值和不一致信息,这增加了数据清洗和预处理的难度。此外,构建过程中还需考虑数据的隐私性和敏感性,确保在分析过程中不泄露个人或企业的敏感信息。最后,模型的泛化能力也是一个关键挑战,如何在不同的贷款场景中保持高精度的异常检测能力,仍需进一步研究和优化。
常用场景
经典使用场景
Small Business Administrations PPP loan dataset 主要用于检测薪资保护计划(PPP)贷款中的异常行为。该数据集通过分析贷款审批金额、借款人信息、贷款用途等关键变量,帮助识别潜在的欺诈行为或数据异常。其经典使用场景包括利用机器学习模型(如孤立森林模型)对贷款数据进行异常检测,从而为政府机构和金融机构提供决策支持。
解决学术问题
该数据集解决了金融领域中贷款数据异常检测的学术研究问题。通过提供详细的贷款信息和借款人背景数据,研究人员能够开发出高效的异常检测算法,识别出不符合常规模式的贷款申请。这不仅有助于提升贷款审批的透明度和公平性,还为金融风险管理提供了新的研究视角和方法论支持。
衍生相关工作
基于该数据集,衍生了一系列经典研究工作,包括孤立森林模型、H2O库的异常检测模型以及基于Pandas的风险评分模型。这些研究不仅推动了异常检测算法的发展,还为金融领域的风险管理提供了新的工具和方法。此外,相关研究还促进了数据可视化技术的进步,使得贷款数据的分析更加直观和高效。
以上内容由遇见数据集搜集并总结生成


