DFA-Instruct
收藏arXiv2025-01-02 更新2025-01-06 收录
下载链接:
https://github.com/lxq1000/DFA-Instruct
下载链接
链接失效反馈官方服务:
资源简介:
DFA-Instruct数据集由马上消费金融有限公司和北京邮电大学的研究团队创建,旨在支持交互式深度伪造分析的研究。该数据集包含127,300张对齐的人脸图像和891,600个相关的问答对,涵盖了深度伪造检测、分类、伪影描述和自由对话等任务。数据集的构建过程通过GPT辅助生成,确保了数据的多样性和质量。该数据集的应用领域主要集中在信息安全、司法调查和个人隐私保护等领域,旨在通过多模态大语言模型的指令调优,提升深度伪造分析的交互性和准确性。
提供机构:
马上消费金融有限公司, 北京邮电大学
创建时间:
2025-01-02
搜集汇总
数据集介绍
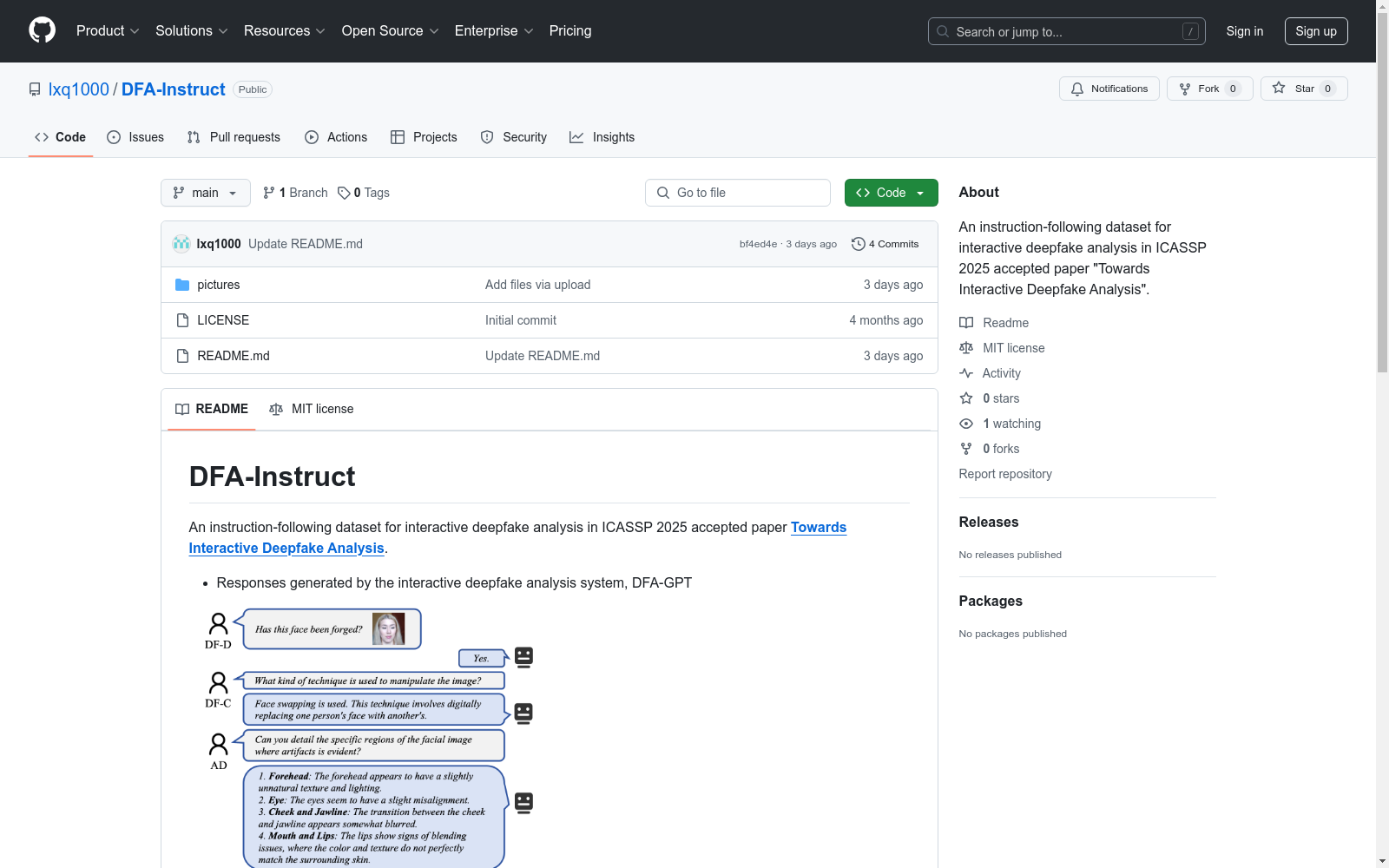
构建方式
DFA-Instruct数据集的构建过程采用了GPT辅助的数据生成方法。首先,从互联网或现有数据集中获取真实人脸图像,并通过多种深度伪造技术生成对应的伪造图像。随后,利用GPT-4o生成与这些图像相关的详细伪造痕迹描述(AD),并通过ChatGPT生成自由对话(FC)数据。最终,数据集包含127.3K对齐的人脸图像和891.6K与之相关的问题-答案对,涵盖了深度伪造检测(DF-D)、分类(DF-C)、伪造痕迹描述(AD)和自由对话(FC)四个能力。
特点
DFA-Instruct数据集的特点在于其多模态和指令跟随的设计。数据集不仅包含丰富的图像数据,还通过GPT生成的详细问题-答案对,涵盖了深度伪造检测、分类、伪造痕迹描述和自由对话等多个任务。此外,数据集的构建过程确保了数据的多样性和细粒度,特别是在伪造痕迹描述方面,提供了对图像中特定区域(如额头、眼睛、脸颊等)的详细分析,使得数据集在深度伪造分析领域具有较高的实用价值。
使用方法
DFA-Instruct数据集的使用方法主要围绕多模态大语言模型(MLLMs)的指令调优展开。研究人员可以利用该数据集对MLLMs进行训练,使其具备深度伪造检测、分类、伪造痕迹描述和自由对话的能力。具体而言,数据集中的问题-答案对可以作为训练样本,帮助模型学习如何根据输入图像生成相应的回答。此外,数据集还附带了一个名为DFA-Bench的基准测试,用于评估模型在深度伪造分析任务中的表现,特别是对伪造痕迹描述能力的评估。通过这种方式,DFA-Instruct为深度伪造分析领域的研究提供了强有力的工具。
背景与挑战
背景概述
DFA-Instruct数据集是由Mashang Consumer Finance Co., Ltd与北京邮电大学的研究团队于2025年提出的,旨在推动交互式深度伪造分析(Interactive Deepfake Analysis, DFA)的研究。随着人工智能生成内容(AIGC)的快速发展,深度伪造技术对社会安全、个人隐私和司法调查等领域构成了严重威胁。现有的深度伪造分析方法主要依赖于判别模型,限制了其应用场景。DFA-Instruct通过指令调优多模态大语言模型(MLLMs),探索了深度伪造检测、分类、伪造痕迹描述及自由对话等能力,为深度伪造分析提供了新的研究方向。该数据集的构建基于GPT辅助的数据生成过程,包含127.3K对齐的人脸图像和891.6K问答对,涵盖了深度伪造检测、分类、伪造痕迹描述和自由对话等多个任务。
当前挑战
DFA-Instruct数据集的构建与应用面临多重挑战。首先,深度伪造分析领域缺乏适合的指令跟随数据集,现有数据集通常仅包含深度伪造检测和分类的标签,而手动标注大规模、细粒度的伪造痕迹描述或自由对话数据既耗时又昂贵。其次,伪造痕迹描述任务尚未明确定义,缺乏相应的评估指标,难以量化模型的性能。此外,多模态大语言模型(MLLMs)通常包含数十亿参数,全模型微调的计算成本极高,限制了其在实际应用中的部署。为解决这些问题,研究团队提出了GPT辅助的数据生成过程,并通过低秩适应(LoRA)模块降低计算成本,但仍需进一步优化模型效率与泛化能力。
常用场景
经典使用场景
DFA-Instruct数据集在深度伪造分析领域中被广泛用于训练和评估多模态大语言模型(MLLMs)。通过指令调优,该数据集能够帮助模型在深度伪造检测、分类以及伪造痕迹描述等任务中表现出色。其经典使用场景包括对伪造图像进行多层次的交互式分析,例如判断图像是否被伪造、识别伪造技术类型,并详细描述伪造痕迹的具体区域。
实际应用
在实际应用中,DFA-Instruct数据集被广泛用于构建交互式深度伪造分析系统,例如DFA-GPT。这些系统在社交媒体安全、个人隐私保护和司法调查等领域发挥了重要作用。通过实时分析伪造图像并提供详细的伪造痕迹描述,这些系统能够帮助人类专家快速识别潜在的伪造内容,从而提高工作效率并减少误判。此外,DFA-Instruct还为开发更智能的伪造检测工具提供了数据支持。
衍生相关工作
DFA-Instruct数据集的发布催生了多项相关研究工作。例如,基于该数据集构建的DFA-GPT系统成为了交互式深度伪造分析的基准模型。此外,DFA-Instruct还启发了其他研究者开发类似的指令调优数据集,以支持更多领域的多模态任务。在深度伪造检测领域,DFA-Instruct的引入推动了基于MLLM的伪造分析技术的发展,并为未来的研究提供了新的方向。
以上内容由遇见数据集搜集并总结生成


