Vrei să fii Milionar?
收藏arXiv2025-06-06 更新2025-06-10 收录
下载链接:
https://huggingface.co/datasets/WWTBM/wwtbm
下载链接
链接失效反馈官方服务:
资源简介:
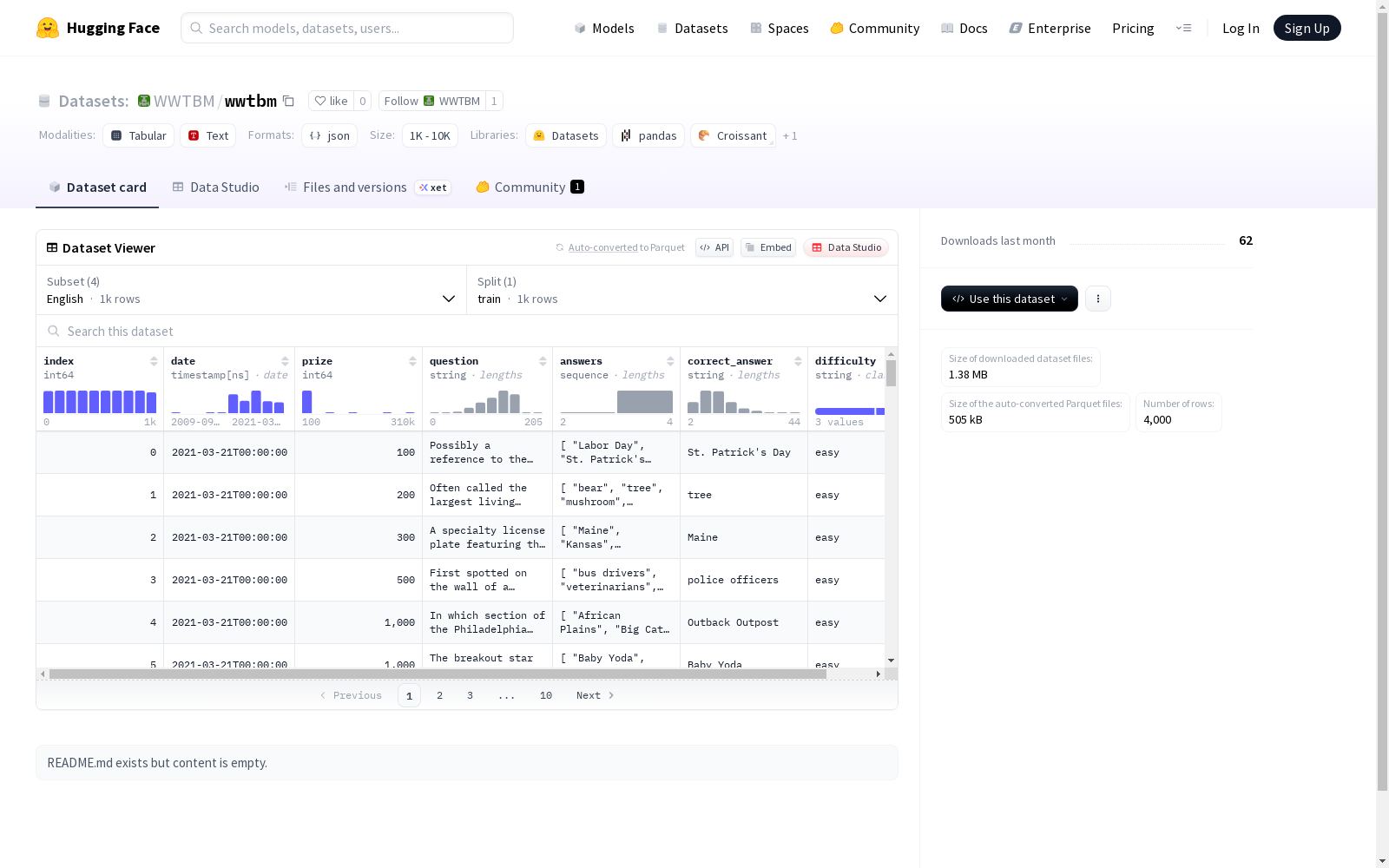
该数据集是从罗马尼亚版《谁想成为百万富翁?》电视节目视频记录中提取的多语言数据集。数据集包含1000个多项选择题,涵盖了艺术、文化、电影、美食等多个领域,并标注了文化相关性和难度等级。数据集通过光学字符识别、自动文本提取和人工验证的过程收集而来,旨在解决低资源和多元文化背景下大型语言模型(LLM)性能评估的问题。数据集公开可在Hugging Face上获取。
This multilingual dataset is extracted from video recordings of the Romanian edition of the iconic television game show *Who Wants to Be a Millionaire?*. It includes 1,000 multiple-choice questions covering diverse domains including art, culture, cinema, cuisine and others, with annotations for cultural relevance and difficulty level. The dataset was collected through optical character recognition (OCR), automated text extraction and manual verification processes, with the core goal of addressing performance evaluation challenges for large language models (LLMs) in low-resource and multicultural contexts. The dataset is publicly available on Hugging Face.
提供机构:
布加勒斯特大学数学与计算机科学学院
创建时间:
2025-06-06
原始信息汇总
数据集概述
基本信息
- 数据集名称: WWTBM
- 托管平台: Hugging Face
- 数据集地址: https://huggingface.co/datasets/WWTBM/wwtbm
数据集配置
数据集包含以下四种配置:
-
Romanian
- 数据文件: Romanian.json
- 描述: 完整的原始罗马尼亚语问答数据。
-
English
- 数据文件: English.json
- 描述: 英语问答题目。
-
French
- 数据文件: French.json
- 描述: 法语问答题目。
-
Romanian_translated
- 数据文件: Romanian_translated.json
- 描述: 翻译后的罗马尼亚语数据。
搜集汇总
数据集介绍
构建方式
该数据集构建自罗马尼亚版《谁想成为百万富翁?》的公开视频录像,采用多模态技术流程进行数据采集与标注。研究团队通过帧级视频分析捕捉题目画面,结合光学字符识别(OCR)和罗马尼亚语变音符号修复模型提取文本信息,并运用嵌入向量相似度检测去除重复项。每道题目均标注了播出日期、奖金金额(作为难度指标)、12个知识领域分类(如艺术、历史等)以及文化语境标签(罗马尼亚本土或国际性知识),最终形成包含1000道多选题的语料库。
特点
作为罗马尼亚首个基于电视节目的文化增强型NLP数据集,其核心价值体现在三方面:题目深度融入本土文化元素(占28.4%),如罗马尼亚历史人物、地理知识和特色谚语;采用游戏节目天然的多级难度体系(按奖金划分简单/中等/困难);保留视频源的口语化表达特征。相较于传统文本语料,该数据集独特地融合了语言理解与文化认知的双重挑战,尤其凸显大语言模型在跨文化语境下的知识盲区。
使用方法
该数据集主要支持三种应用场景:作为基准测试工具,可评估模型对罗马尼亚语言及文化的理解能力,具体通过零样本多选问答准确率进行量化;在跨语言研究中,其英语/法语平行版本支持文化因素与语言能力的解耦分析;对于教育科技领域,可用于开发文化适配的智能辅导系统。使用时应遵循原始难度分级体系,注意文化标签的分布差异(国际性问题占71.6%),对于关键结论建议结合细分领域(如文学类题目)进行交叉验证。
背景与挑战
背景概述
数据集“Vrei să fii Milionar?”由布加勒斯特大学数学与计算机科学学院的Alexandru-Gabriel Ganea、Antonia-Adelina Popovici和Adrian-Marius Dumitran等研究人员创建,旨在解决大型语言模型(LLMs)在不同语言和文化背景下的性能差异问题。该数据集源自罗马尼亚游戏节目《谁想成为百万富翁?》的视频记录,通过结合光学字符识别(OCR)、自动化文本提取和人工验证的方法,收集了大量问答对,并丰富了包括问题领域、文化相关性和难度在内的元数据。该数据集的推出填补了罗马尼亚语等中低资源语言在自然语言处理(NLP)领域的空白,为构建更具文化意识的多语言NLP系统提供了重要资源。
当前挑战
数据集“Vrei să fii Milionar?”面临的挑战主要包括两个方面:领域问题的挑战和构建过程中的挑战。在领域问题方面,该数据集旨在评估LLMs在罗马尼亚文化和语言背景下的表现,但研究发现,LLMs在国际问题上的准确率(80-95%)显著高于罗马尼亚特定文化问题(50-75%),凸显了文化语境对模型性能的重要影响。在构建过程中,研究人员需从动态视觉格式(视频)中提取结构化数据,涉及复杂的OCR和文本提取技术,同时还需处理罗马尼亚语中的变音符号恢复和重复问题去除等技术难题。此外,数据集的规模相对较小(约1000个问题),可能影响评估的统计稳健性,尤其是在处理高难度问题和罕见主题时。
常用场景
经典使用场景
在自然语言处理领域,Vrei să fii Milionar?数据集为研究者提供了一个独特的文化丰富型评估平台。该数据集源自罗马尼亚版《谁想成为百万富翁》节目视频,通过光学字符识别和人工验证构建了包含1000个多选题的语料库,每个问题均标注了文化相关性(罗马尼亚本土与国际)和难度等级。其经典使用场景主要体现在对多语言大语言模型(LLMs)的文化适应性和语言理解能力进行基准测试,尤其适用于分析模型在罗马尼亚语及特定文化背景下的表现差异。
解决学术问题
该数据集有效解决了当前LLM评估中文化多样性缺失的关键问题。通过对比模型在罗马尼亚本土文化问题与国际通用问题上的表现差异(如Llama-3.3-70B在国际问题准确率达96.5%而本土问题仅75.8%),揭示了现有模型在文化特异性知识上的显著缺陷。其标注体系(含12个主题领域和3级难度)为量化分析模型的语言理解深度与文化知识覆盖度提供了结构化框架,弥补了中低资源语言评估工具的空白,推动了文化敏感型NLP系统的发展。
衍生相关工作
该数据集已催生多项罗马尼亚语NLP的创新研究。基于其构建的RoGemma2-9B等罗马尼亚微调模型展现了语言适应性提升(国际问题准确率提升至91.5%)。相关跨语言实验启发了类似法语文化数据集的建设,而文化分类方法被扩展至东欧语言评估基准Vorbesti Românes,te?。其问题难度预测机制更影响了后续教育类数据集的标注标准,形成文化敏感型评估的技术范式。
以上内容由遇见数据集搜集并总结生成


