FullFront
收藏arXiv2025-05-23 更新2025-05-27 收录
下载链接:
https://github.com/Mikivishy/FullFront
下载链接
链接失效反馈官方服务:
资源简介:
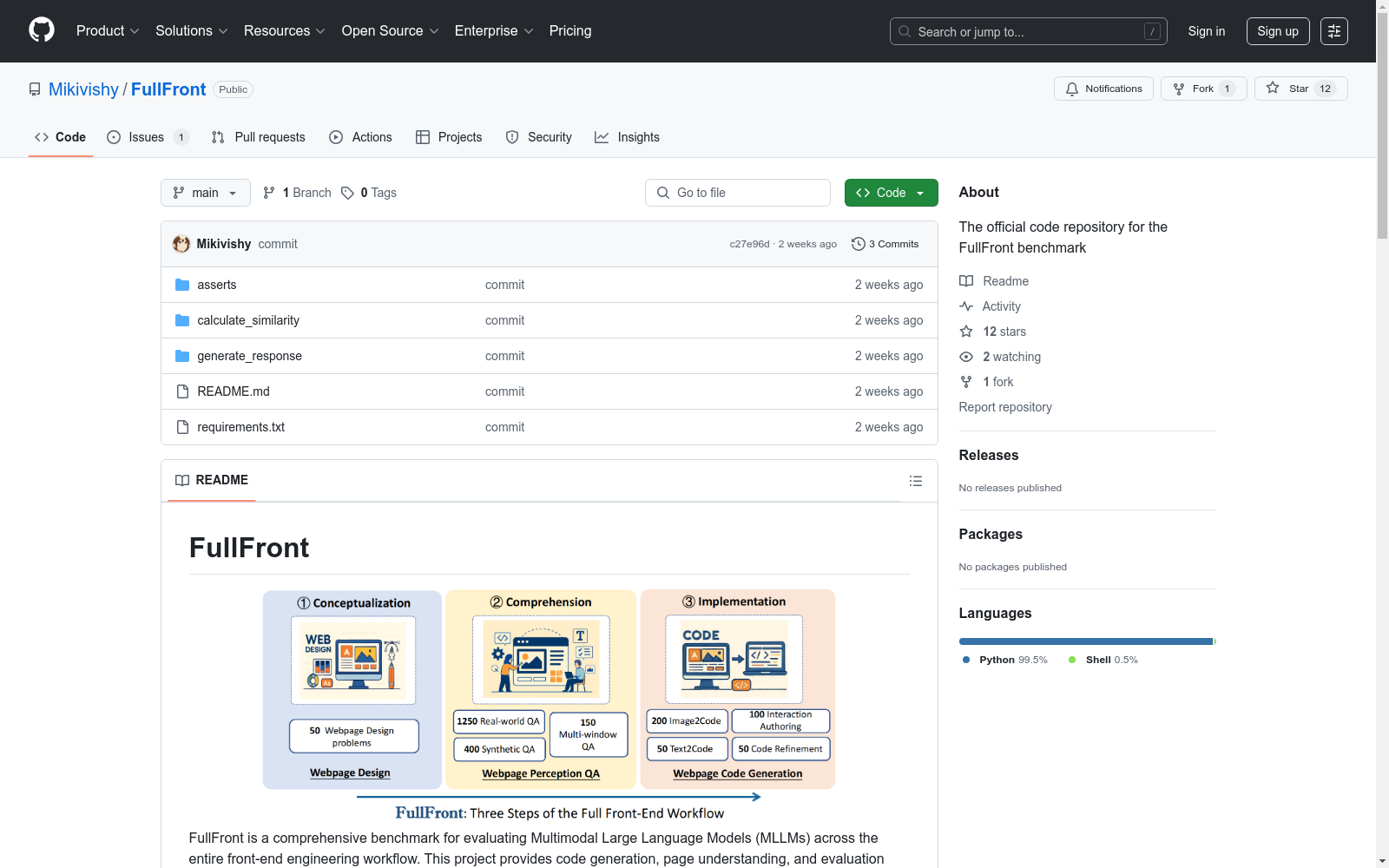
FullFront是一个全面的前端工程工作流程基准数据集,旨在评估多模态大型语言模型(MLLMs)在网页设计、网页感知问答和网页代码生成三个核心任务上的能力。数据集包含50个网页设计问题、1800个多选题以及400个代码生成问题,涵盖了前端开发的各个方面。FullFront采用两阶段流程,将现实世界的网页转换为清洁、标准化的HTML,同时保持了原始的视觉多样性。该数据集对于评估和提升MLLMs在网页开发领域的应用具有重要意义。
提供机构:
Microsoft
创建时间:
2025-05-23
搜集汇总
数据集介绍
构建方式
FullFront数据集通过创新的两阶段流程构建,首先从真实网页截图中提取元素信息,随后利用GPT-4o生成初始HTML-v1代码,再通过Claude 3.7 Sonnet优化为结构复杂且视觉保真度高的HTML-v2版本。数据涵盖网页设计、感知问答和代码生成三大任务,其中感知问答任务包含1250个真实场景问题和400个合成问题,代码生成任务则包含图像转代码、文本转代码等4个子任务。为确保数据多样性并规避版权风险,采用15类标准化图像分类策略替代原始网页图片。
特点
该数据集以前端工程全流程评估为核心特色,首次实现从概念设计到代码实现的端到端基准测试。其多模态特性体现在融合视觉截图、结构化代码和文本描述三种数据形态,并通过1800道多选题系统评估模型对网页元素位置、样式和空间关系的感知能力。数据质量方面,通过人工校验确保问答对准确性,并采用标准化HTML生成流程保证代码可复现性。相较于现有基准,FullFront在交互功能实现和代码优化等细分任务上具有显著优势。
使用方法
使用FullFront需分阶段进行:在网页设计任务中,模型需根据文本描述生成网页设计图;感知问答任务要求模型分析网页截图并回答元素定位、样式判断等问题;代码生成任务则需将视觉设计转化为可执行代码,包含静态页面重构和交互功能实现。评估时采用视觉相似度(CLIP Score、Gemini Visual Score)和代码级指标(DOM结构相似度、内容匹配度)相结合的混合度量体系。为便于快速验证,数据集提供精简版FullFront-mini,包含核心任务的代表性样本。
背景与挑战
背景概述
FullFront是由同济大学、华盛顿大学、中山大学、微软研究院和香港中文大学的研究团队于2025年联合推出的多模态大语言模型(MLLMs)评估基准。该数据集聚焦前端工程全流程,涵盖从概念设计到代码实现的完整工作流,包含网页设计(50项)、网页感知问答(1800项)和网页代码生成(400项)三大核心任务。通过两阶段数据构建流程,将真实网页转化为标准化HTML的同时保留视觉多样性,解决了现有基准仅关注单一环节(如视觉转代码)的局限性,为评估MLLMs在前端工程领域的综合能力提供了首个端到端测试框架。
当前挑战
FullFront面临双重挑战:在领域问题层面,需解决MLLMs对网页元素精细感知(如对齐、间距、尺寸判断)准确率不足(最佳模型Claude 3.7平均精度仅55%)、复杂布局代码生成(特别是图像处理和交互实现)的可靠性问题;在构建层面,需平衡版权合规性与数据真实性,通过创新性类别化图像处理策略(15类标准图像URL)解决传统方法中图像占位符导致的评估失真,并设计多粒度评估指标(视觉相似度、代码结构分数)以量化模型在语义理解与像素级还原间的差距。
常用场景
经典使用场景
FullFront数据集作为多模态大语言模型(MLLMs)在前端工程全流程中的评估基准,其经典使用场景主要集中在三个核心任务上:网页设计(Webpage Design)、网页感知问答(Webpage Perception QA)以及网页代码生成(Webpage Code Generation)。这些任务分别对应前端工程中的概念化、视觉理解和代码实现阶段,为研究者提供了一个系统化的评估框架,用以检验MLLMs在从设计到代码的完整工作流中的能力。
实际应用
在实际应用中,FullFront数据集可助力开发智能化的前端工程辅助工具。例如,基于其评估结果优化的MLLMs能够自动将设计草图转化为代码原型,或通过问答系统辅助开发者快速理解现有网页的视觉结构。数据集中的交互实现任务(Interaction Authoring)尤其适用于低代码平台,可加速动态网页组件的开发流程。此外,代码优化任务(Code Refinement)为自动化代码质量提升提供了测试场景。
衍生相关工作
FullFront的发布推动了多项相关研究的发展。在基准扩展方面,后续工作如WebCode2M和Design2Code借鉴了其多阶段评估范式;在模型优化领域,Claude 3.7和Gemini 2.5等模型通过该数据集发现了视觉感知与代码生成的关联性缺陷,进而改进了跨模态对齐模块。数据集构建方法也启发了OmniParser等工具的开发,用于更精准的网页元素解析。这些衍生工作共同促进了前端工程智能化研究的纵深发展。
以上内容由遇见数据集搜集并总结生成


