COSMOBENCH
收藏arXiv2025-07-05 更新2025-08-15 收录
下载链接:
https://cosmobench.streamlit.app/
下载链接
链接失效反馈官方服务:
资源简介:
COSMOBENCH 是一个多尺度、多视图、多任务的宇宙学基准数据集,由先进的宇宙学模拟数据组成。该数据集包含 34,000 个点云,来自暗物质晕和星系的三种不同长度尺度的模拟,以及 25,000 个有向树,记录了两个不同时间尺度上晕的形成历史。数据集可用于多种任务,包括从点云和合并树预测宇宙学参数,从其集体位置预测单个晕和星系的速度,以及从较粗的时间尺度上重建较细的时间尺度上的合并树。数据集的创建过程涉及对模拟数据的处理和分割,以适应不同的任务和模型。COSMOBENCH 旨在推动宇宙学与几何深度学习之间的桥梁,通过利用机器学习和宇宙学模型的优势,为解决宇宙学中的关键问题提供支持。
COSMOBENCH is a multi-scale, multi-view, and multi-task cosmological benchmark dataset constructed from state-of-the-art cosmological simulation data. This dataset contains 34,000 point clouds derived from simulations of dark matter halos and galaxies across three distinct length scales, alongside 25,000 directed trees that catalog the formation histories of halos over two different timescales. The dataset supports a wide range of tasks, including predicting cosmological parameters from point clouds and merger trees, forecasting the velocities of individual halos and galaxies based on their collective positions, and reconstructing merger trees at finer timescales from coarser temporal resolutions. The creation of COSMOBENCH involves processing and partitioning simulation data to cater to diverse tasks and models. COSMOBENCH aims to bridge the gap between cosmology and geometric deep learning, leveraging the strengths of both machine learning and cosmological models to support the resolution of key open problems in cosmology.
提供机构:
Flatiron Institute, University of Oxford, Seoul National University, Princeton University
创建时间:
2025-07-05
搜集汇总
数据集介绍
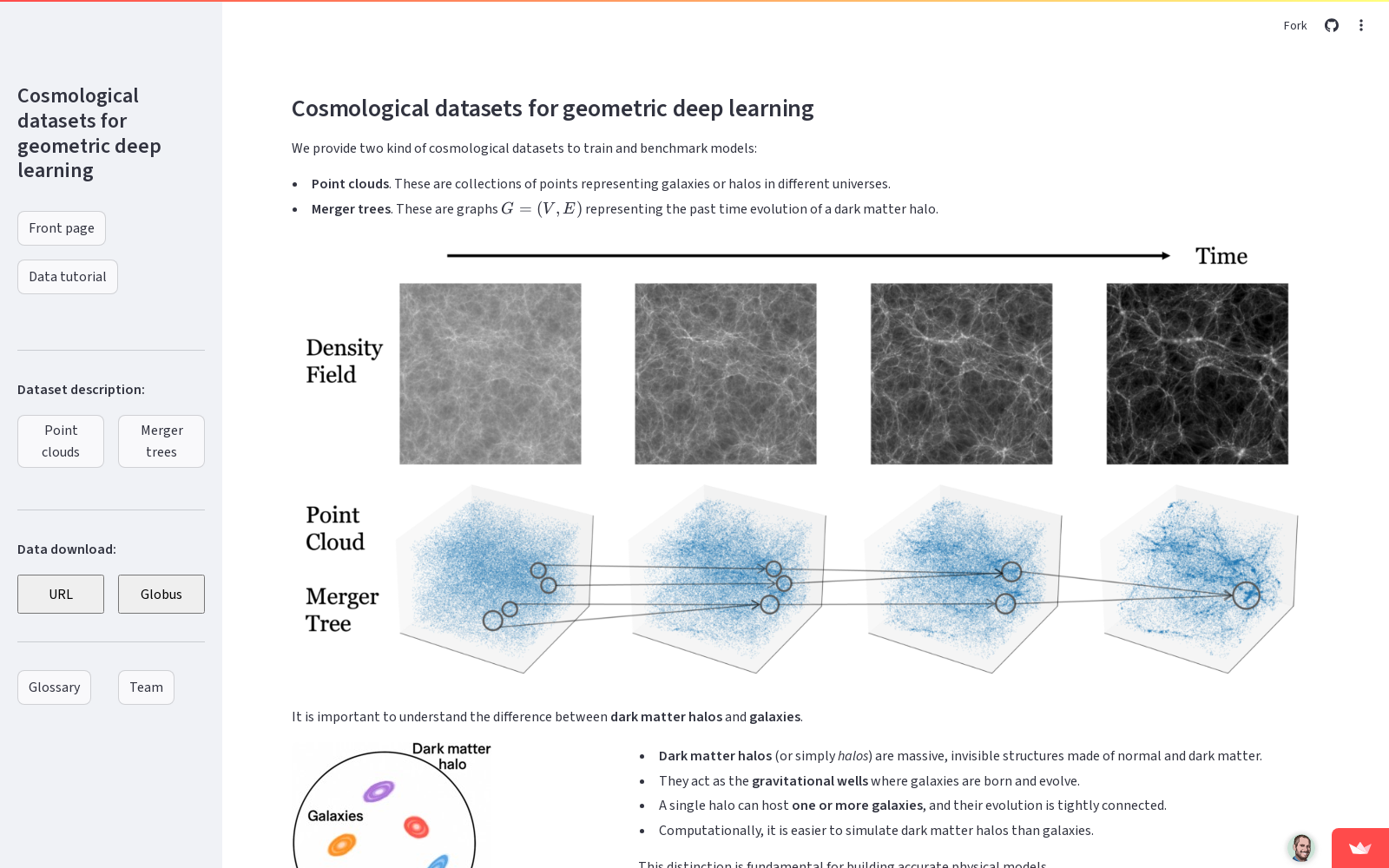
构建方式
COSMOBENCH数据集通过整合来自Quijote、CAMELS-SAM和CAMELS三个先进宇宙学模拟套件的点云和合并树数据构建而成,这些模拟总计消耗超过4100万核心小时的计算资源,生成了超过2PB的数据。点云数据提取自模拟的当前时刻(z=0)快照,包含暗物质晕和星系的三维位置与速度信息,并通过周期性边界条件保持空间连续性。合并树数据则通过Rockstar和ConsistentTrees算法从CAMELS-SAM模拟中提取,记录了暗物质晕的层级形成历史,并通过修剪和路径优化减少数据冗余。数据集按60/20/20的比例随机划分为训练集、验证集和测试集,确保任务评估的统计可靠性。
特点
COSMOBENCH作为当前规模最大的多尺度、多视角宇宙学基准数据集,包含34,000个跨越三个空间尺度的点云(分别来自1,000 cMpc/h、100 cMpc/h和25 cMpc/h的模拟盒)以及24,996个时间分辨率不同的合并树。其独特之处在于同时涵盖暗物质晕和星系实体,支持从线性到高度非线性的多尺度宇宙结构研究。点云数据标注了宇宙学参数(如Ωm和σ8),而合并树则包含晕的质量、浓度、最大速度等动态演化特征。数据模态的多样性使其能够支持宇宙参数预测、速度场重建和合并树超分辨率等跨任务研究。
使用方法
该数据集通过PyTorch接口提供统一的任务实现框架,支持三类核心任务:1)基于点云或合并树的图级回归(如从点云预测宇宙学参数);2)节点级回归(如从星系位置预测速度场);3)图超分辨率(如从粗时间分辨率合并树重建细粒度结构)。用户可通过加载预分割的数据子集,结合提供的基线模型(如线性最小二乘、图神经网络)或自定义模型进行训练与评估。对于合并树任务,需注意节点特征的层次化处理(如质量、尺度因子)以捕捉拓扑结构。数据集还包含线性理论预言等物理先验,支持跨学科方法对比。
背景与挑战
背景概述
COSMOBENCH是由Flatiron Institute、普林斯顿大学等机构的研究团队于2025年推出的多尺度、多视角、多任务宇宙学基准数据集,旨在推动几何深度学习在宇宙学领域的应用。该数据集基于Quijote、CAMELS-SAM和CAMELS等前沿宇宙学模拟,累计消耗超过4100万核心小时计算资源,生成超过2PB数据,包含3.4万个暗物质晕与星系点云及2.5万棵合并树。其核心研究问题聚焦于通过点云与合并树预测宇宙学参数、推断天体速度场及重建精细合并树,为理解宇宙物质分布、结构形成历史及基本物理规律提供了全新研究范式。作为当前规模最大的多模态宇宙学基准,COSMOBENCH通过统一PyTorch接口整合了传统宇宙学方法与机器学习模型,显著促进了宇宙学与几何深度学习的交叉创新。
当前挑战
该数据集面临三重核心挑战:在科学问题层面,宇宙学参数预测需克服非线性尺度下信息提取的复杂性,如小尺度模拟中σ8参数预测性能显著下降(CAMELS数据集R²仅0.24±0.06);数据构建层面,处理PB级模拟数据时面临存储约束与时间分辨率平衡问题,如合并树重构任务需从100个时间步长压缩至50步;方法论层面,传统两点相关函数在非高斯区域表现受限(Quijote数据集Ωm预测R²=0.85),而图神经网络虽能捕捉高阶特征但计算成本激增(训练耗时可达24GPU小时)。此外,跨尺度泛化难题在1,000cMpc/h至25cMpc/h的箱体尺寸跨度中尤为突出,简单线性模型在CAMELS-SAM速度预测任务中R²仅0.21,暴露了小尺度动力学的建模瓶颈。
常用场景
经典使用场景
COSMOBENCH数据集在宇宙学研究中扮演着关键角色,特别是在几何深度学习领域。该数据集通过整合来自Quijote、CAMELS-SAM和CAMELS等先进宇宙学模拟的点云和定向树数据,为研究者提供了一个多尺度、多视角、多任务的基准测试平台。其经典使用场景包括从点云预测宇宙学参数(如Ωm和σ8)、从位置数据预测星系或暗物质晕的速度场,以及从粗粒度时间尺度的合并树重建细粒度时间尺度的合并树。这些任务不仅验证了机器学习模型在宇宙学数据上的表现,还为理解宇宙大尺度结构形成提供了新的视角。
实际应用
在实际应用方面,COSMOBENCH数据集为未来宇宙学观测项目(如Euclid和LSST)提供了重要的预研工具。通过该数据集训练的模型可直接应用于观测数据分析,例如从星系巡天数据中推断宇宙学参数,或预测无法直接观测的星系速度场以改进宇宙膨胀率的测量。此外,数据集中的合并树重建任务为降低计算成本提供了可能——通过预测高时间分辨率的合并树来减少模拟所需的存储和计算资源。这些应用将显著提升下一代宇宙学调查的科学产出效率。
衍生相关工作
围绕COSMOBENCH数据集已衍生出多项经典研究工作。在方法论层面,数据集推动了图神经网络(GNNs)在宇宙学点云分析中的创新应用,如基于高阶图结构的消息传递模型。同时,研究发现了简单线性模型与对称性约束特征的组合有时能超越复杂深度学习架构的现象,这激发了物理启发式机器学习的新方向。在应用层面,数据集被用于验证场级推断技术、开发半解析模型加速方法,以及构建生成式模型模拟暗物质晕形成历史。这些工作共同推动了宇宙学与几何深度学习的深度融合。
以上内容由遇见数据集搜集并总结生成


