jfleg-japanese
收藏官方服务:
资源简介:
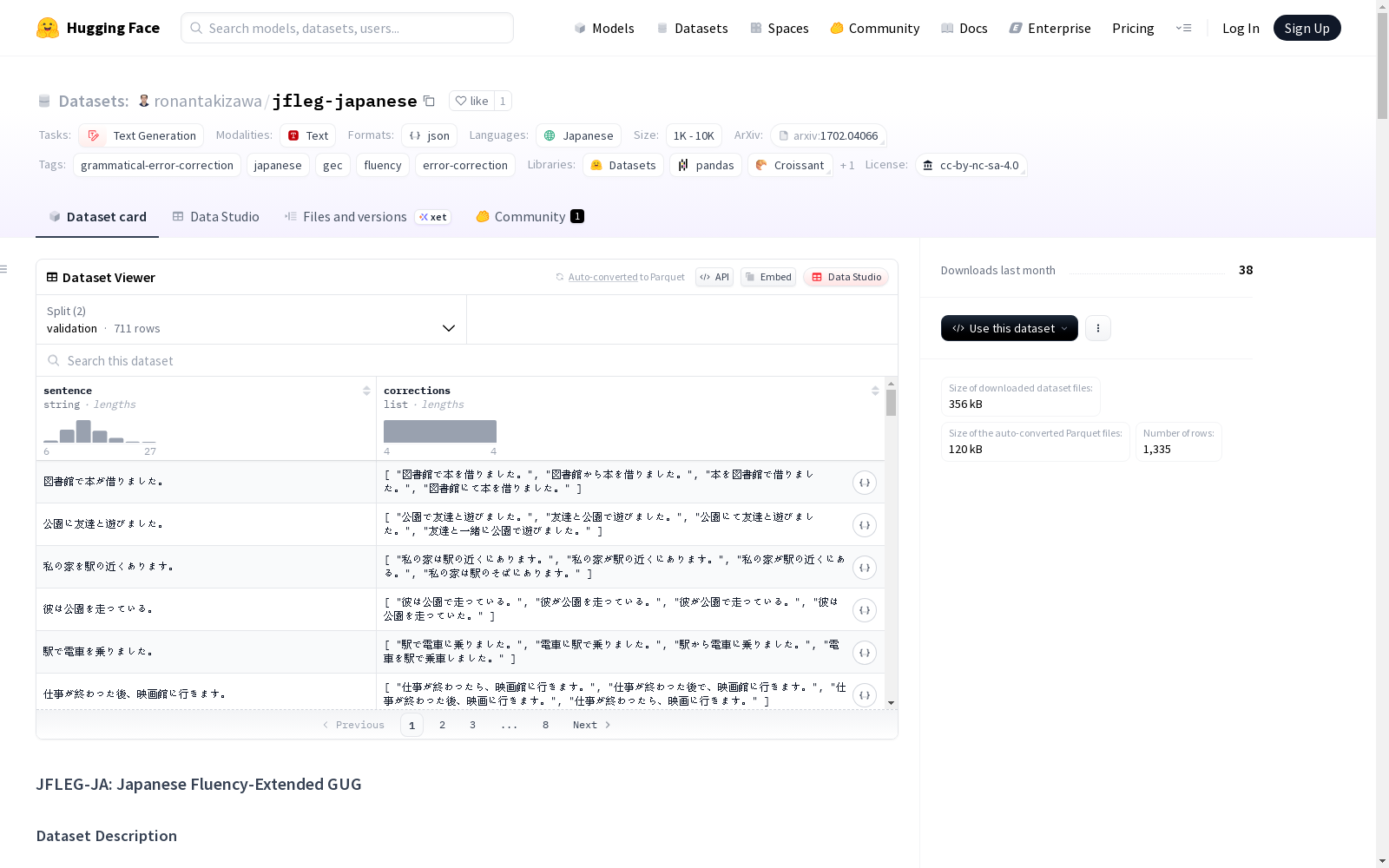
JFLEG-JA是一个受原始JFLEG数据集启发的日语语法错误修正(GEC)数据集。它包含1335个含有语法错误的日语句子,每个句子都伴有4个人工高质量修正版本,这些修正版本同时关注语法性和流畅性。
创建时间:
2025-10-24
原始信息汇总
JFLEG-JA 数据集概述
数据集基本信息
- 名称:JFLEG-JA
- 语言:日语
- 任务类型:语法错误纠正
- 许可证:CC-BY-NC-SA 4.0
- 数据规模:1K<n<10K
数据集描述
JFLEG-JA 是一个日语语法错误纠正数据集,灵感来源于原始 JFLEG 基准。包含 1,335 个带有语法错误的日语句子,每个句子配有 4 个注重语法性和流畅性的人工质量修正。
数据集结构
数据实例
每个实例包含:
sentence:带有语法错误的日语句子corrections:4 个修正版本的列表
数据字段
sentence:包含语法错误的源句子corrections:句子的四个不同修正版本
数据划分
| 划分 | 实例数量 |
|---|---|
| 验证集 | 711 |
| 测试集 | 624 |
| 总计 | 1,335 |
包含的错误类型
- 助词错误
- 常见汉字混淆
- 疑问句语法错误
- 字符大小错误
- 错误量词用法
- 错误动词用法
- 错误形容词用法
- 错误短语用法
- 指示词错误
- 错误语序
- 错误时态
- 错误拟声词
- 错误隐喻用法
数据集创建
数据来源
- AI 生成句子
- 手动编写的替换句子
数据质量
- 每个示例都有 4 个唯一修正
- 无错误句子出现在自身修正中
- 示例内无重复修正
- 划分内无重复句子
使用方式
加载数据集
python from datasets import load_dataset dataset = load_dataset("ronantakizawa/jfleg-japanese")
主要用途
- 评估语法错误纠正模型
- 少样本学习
- 错误分析
- 模型训练
评估指标
- GLEU
- BLEU
- 精确匹配准确率
- F0.5
局限性
- 合成来源
- 规模较小
- 非商业用途限制
- 仅用于评估
引用信息
bibtex @dataset{jfleg_ja_2025, title={JFLEG-JA: A Japanese Grammatical Error Correction Benchmark}, author={Takizawa, Ronan}, year={2025}, url={https://huggingface.co/datasets/ronantakizawa/jfleg-japanese}, note={Adapted from the original JFLEG dataset} }
搜集汇总
数据集介绍
构建方式
在日语语法纠错研究领域,JFLEG-JA数据集的构建采用了前沿的生成式人工智能技术。通过OpenAI的GPT-4模型批量生成包含典型语法错误的日语句子,并辅以人工撰写的替换语句进行质量增强。为确保数据可靠性,研发团队实施了多轮自动化质量验证流程,包括检测重复修正项、消除跨数据分割的句子重叠现象,最终形成包含1,335组错误-修正对的高质量语料库。
特点
该数据集以覆盖日语语法错误的多样性著称,系统囊括了助词误用、汉字混淆、动词形态错误等十五类典型语言现象。每个错误句子均配备四组经过人工校验的修正版本,既注重语法准确性又兼顾表达流畅度。其独特的评估导向设计体现在严格划分的验证集与测试集结构上,且所有修正文本均通过本族语者校验,确保了语言的地道性与规范性。
使用方法
研究者可通过HuggingFace数据集库直接加载该资源,利用其多参考修正特性进行语法纠错模型的基准测试。建议采用GLEU、BLEU等多参考评估指标,结合精确匹配准确率与F0.5分数进行全面性能衡量。在符合非商业许可的前提下,该数据集支持少样本学习、错误模式分析等研究场景,为日语自然语言处理领域提供重要的评估基准。
背景与挑战
背景概述
日语语法纠错研究作为自然语言处理的重要分支,其发展长期受限于高质量标注资源的稀缺。JFLEG-JA数据集于2025年由研究者Ronan Takizawa基于约翰霍普金斯大学开发的JFLEG基准架构创建,专攻日语语法与流畅度双重修正任务。该数据集通过融合GPT-4生成与人工校验的双重机制,构建了1,335组包含四重人工修正的平行语料,有效填补了日语语法纠错领域标准化评测资源的空白,为日语自然语言处理模型的精细化评估提供了关键基础设施。
当前挑战
在解决日语语法纠错问题时,需应对助词混用、汉字误写、动词形态异常等十余类复杂语言现象的多维度建模挑战。数据集构建过程中,研发团队需克服AI生成文本与自然语言偏差的固有局限,通过自动化脚本与人工质检的协同机制,严格保证四组修正结果的独立性与自然度,同时规避跨数据分割的样本污染风险,最终在非商业许可框架下实现了对原始JFLEG基准88.8%的规模复现。
常用场景
经典使用场景
在日语语法纠错研究领域,JFLEG-JA数据集作为评估基准,其经典应用体现在对自动纠错系统性能的全面评测。该数据集通过提供包含助词误用、汉字混淆、动词形态错误等多样化语法问题的句子,并配备四组人工修正参考,使得研究者能够系统衡量模型在语法准确性与语言流畅度两方面的表现。这种多参考评估机制特别适用于比较不同纠错算法在复杂语言现象处理上的优劣。
衍生相关工作
受该数据集启发,学界涌现出多项创新研究。部分工作聚焦于改进评估指标,提出了针对日语特性的加权GLEU算法;另有研究通过数据增强技术扩展了错误类型覆盖范围。值得关注的是,基于跨语言迁移学习的方法尝试将英语JFLEG的知识迁移至日语场景,这种思路为低资源语种的语法纠错研究开辟了新路径。
数据集最近研究
最新研究方向
在日语语法纠错领域,JFLEG-JA数据集正推动着多维度研究范式的革新。基于其包含助词误用、汉字混淆、时态错误等14类典型语法现象的特性,当前研究聚焦于构建融合语言学规则的神经符号模型,通过引入对比学习机制增强模型对近义表达的分辨能力。随着大语言模型在日语处理中的普及,该数据集已成为评估提示工程优化策略与少样本学习性能的关键基准,特别是在处理比喻用法和拟声词等文化负载错误类型方面展现出独特价值。其多参考修正特性进一步促进了基于图神经网络的语义一致性评估框架发展,为构建具备语言流畅性与文化适配性的智能纠错系统提供了重要支撑。
以上内容由遇见数据集搜集并总结生成


