SpikeProphecy benchmark (Steinmetz 2019 + IBL Repeated Site)
收藏SpikeProphecy / Steinmetz 2019(处理版)数据集概述
基本信息
- 数据集名称:SpikeProphecy / Steinmetz 2019 (processed)
- 许可证:CC-BY-4.0
- 语言:英语
- 标签:神经科学、电生理学、神经群体、尖峰预测、基准测试、Neuropixels
- 大小:1000万至1亿条记录
- 任务类型:时间序列预测
数据来源与处理
该数据集是对Steinmetz等人(2019)公开数据集的确定性预处理结果,来源于发表在Nature 576:266–273上的论文《Distributed coding of choice, action and engagement across the mouse brain》。原始数据(原始尖峰时间、行为协变量、NWB文件)保留在Figshare平台,本数据集仅分享分箱后的整数计数张量和会话元数据。
预处理流程
- 读取NWB尖峰时间数据
- 以Δt = 50毫秒进行分箱,生成整数计数向量(转换为uint8类型)
- 删除平均发放率低于0.1 Hz的近静默单元
- 输出每个会话的[n_units, n_bins]张量,以及70/15/15的训练/验证/测试时间分割边界元数据
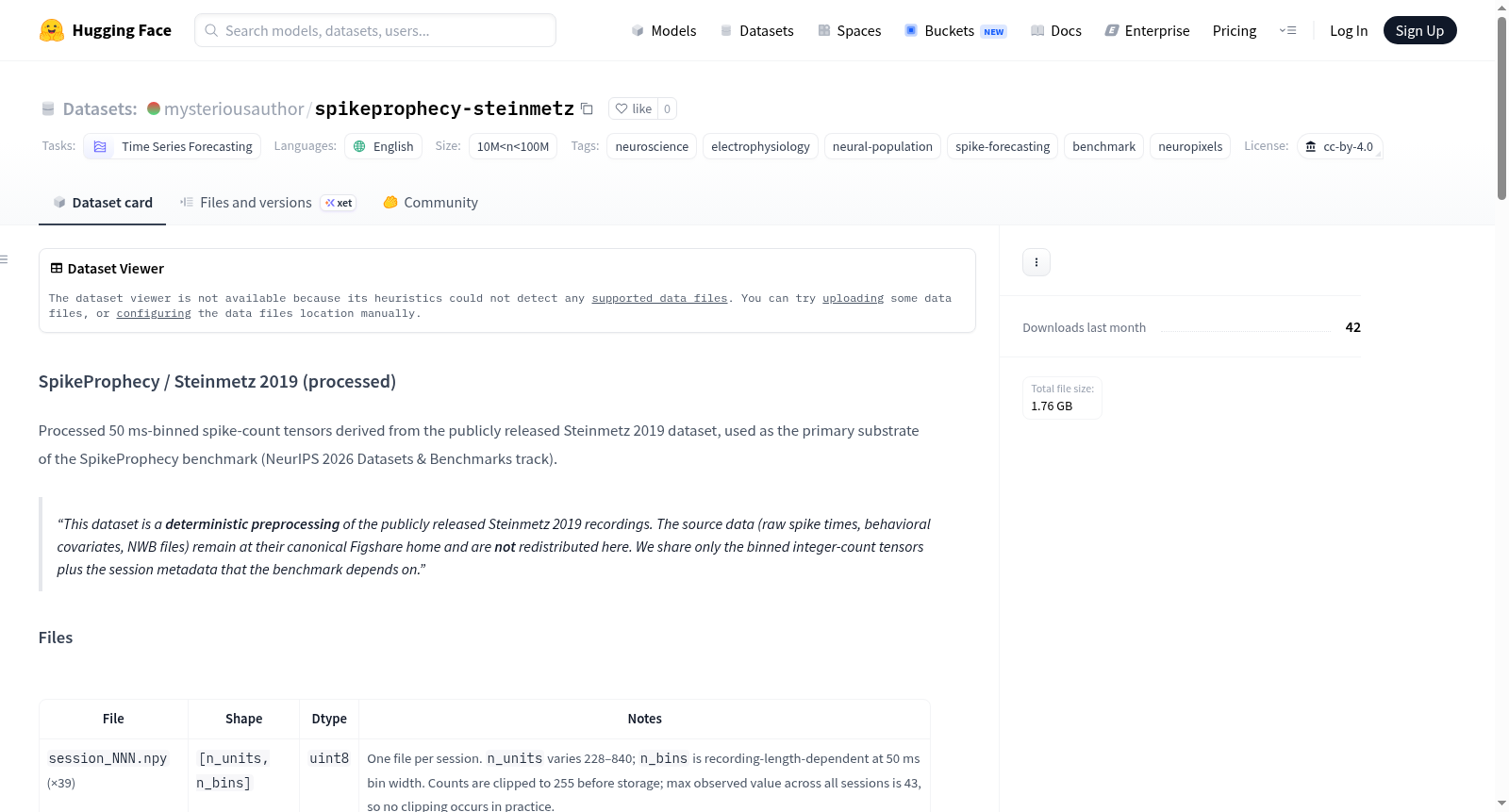
文件结构
| 文件 | 形状 | 数据类型 | 说明 |
|---|---|---|---|
session_NNN.npy(×39个) |
[n_units, n_bins] | uint8 | 每个会话一个文件。n_units范围228–840;n_bins取决于记录时长(50毫秒箱宽)。计数值截断至255之前存储,所有会话中最大观测值为43,因此实际无截断发生 |
metadata.json |
— | — | 每个会话的元数据,包含单元数量、箱数、时长、分割边界(训练结束、验证结束)以及每个单元的脑区信息(Allen CCF缩写)。顶层参数包括:m_max=1240,bin_width_ms=50,history_bins=10 |
数据划分
采用70/15/15的训练/验证/测试时间分割策略,在每个会话内部按时间顺序划分为第一段(训练)、中间段(验证)、最后段(测试)。分割边界以原始箱索引形式编码在metadata.json中,而非预分割数组。该数据集附带了14项自动化泄漏审计套件,验证五种具体泄漏向量:
- 训练/测试箱重叠
- 滑动窗口边界穿越
- 跨会话溢出
- 使用未来统计数据进行归一化
- 历史特征泄漏
使用示例
python import numpy as np import json from pathlib import Path from huggingface_hub import snapshot_download
local = snapshot_download(repo_id="mysteriousauthor/spikeprophecy-steinmetz", repo_type="dataset") local = Path(local)
meta = json.loads((local / "metadata.json").read_text()) print(meta["num_sessions"], "sessions, M_max =", meta["m_max"])
会话4(703个单元,论文图1中用作典型中值会话)
counts = np.load(local / "session_004.npy") # [703, 60887], uint8 sb = meta["sessions"][4]["split_boundaries"] train = counts[:, :sb["train_end"]] val = counts[:, sb["train_end"]:sb["val_end"]] test = counts[:, sb["val_end"]:]
引用信息
若使用本处理后的数据集,请同时引用原始Steinmetz论文和SpikeProphecy基准:
- 原始论文:Steinmetz et al. (2019), Distributed coding of choice, action and engagement across the mouse brain, Nature 576:266–273
- 基准论文:SpikeProphecy: A Large-Scale Benchmark for Autoregressive Neural Population Forecasting, NeurIPS 2026 Datasets and Benchmarks Track
其他
- 数据集根目录包含符合Croissant 1.0标准的JSON-LD元数据文件
croissant.json - 数据集许可证为CC-BY-4.0,与源数据集许可证一致
- 1SpikeProphecy: A Large-Scale Benchmark for Autoregressive Neural Population Forecasting加州大学圣克鲁兹分校·电气与计算机工程系; 加州大学圣克鲁兹分校·基因组学研究所; 加州大学圣克鲁兹分校·计算机科学与工程系; 加州大学圣克鲁兹分校·应用数学系; 加州大学圣克鲁兹分校·生物分子工程系 · 2026年


