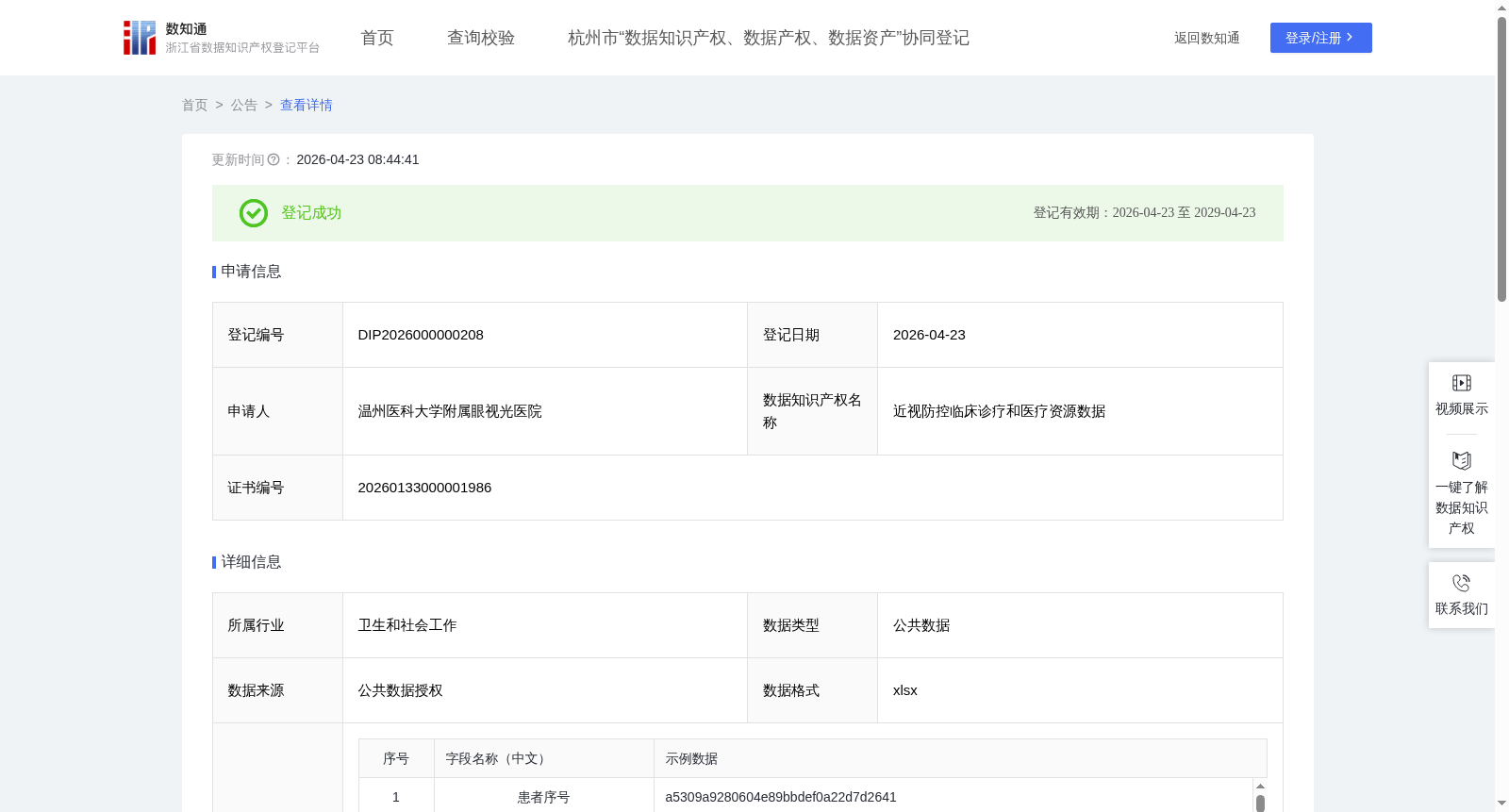
近视防控临床诊疗和医疗资源数据
收藏浙江省数据知识产权登记平台2026-04-23 更新2026-04-24 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8438582
下载链接
链接失效反馈官方服务:
资源简介:
当前,全球近视患病率高发,已成为重大公共卫生问题。<<近视防治指南(2024年版)>>显示,我国近视患病率达53.6%,高度近视患者占比显著增加,是不可逆性致盲主因之一。现有防控手段难以满足精准防控需求,相关研究缺乏对近视患者人群特征、诊疗模式、医疗资源利用的系统性刻画,标准化近视数据集的建设,正是破解上述困境的核心抓手。
本项目整合近视患者诊疗和医疗资源利用情况的数据,包含:人口学信息、就诊信息、诊断信息、病例信息、生命体征信息、眼科检查信息、药品医嘱信息、非药品医嘱信息。对繁杂无序的诊疗数据开展匿名化、标准化、结构化处理,转化为可直接用于分析的标准化数据集。基于高质量数据集,可针对疾病精准诊断、药械疗效量化评估、行业发展趋势研判等关键方向,开展科学系统的预测分析,为临床研究、公共卫生政策制定及眼视光产品开发等提供支撑。数据说明:
原始数据为公共数据,经政府授权运营,数据可用不可见。包含近视患者人口学、就诊、诊断、病历、生命体征、眼科检查、药品医嘱、非药品医嘱8类信息,覆盖基础信息、诊疗全流程记录及医疗资源使用相关数据。
处理规则:
数据处理平台为政府牵头建设的公共数据授权运营域,域内数据已根据相应脱敏规则进行匿名化、去标识化处理。
项目将不同类型数据按照对应患者序号进行关联清洗,对患者序号进行编号处理,生成自增的序号。形成包括92个字段的数据集,其中通过数据标准化处理的字段有33个(AO-AQ、AT-BA、BC-BM、BS-CC列);另有17个字段(D、Y-AN列)是利用自然语言处理、机器学习、AI大模型技术通过患者的诊断、主诉、现病史、专科检查、辅助检查得出患者结构化字段,例如是否有过敏性结膜炎等结果。
技术实施流程核心分为两部分:
第一部分:需标准化的字段,针对每一个字段根据实际数据情况制定标准化的规则,如身高,对原始数据中的厘米、米、cm、m统一为m;
第二部分:从文本中结构化字段,分两步。一是文本预处理,对临床文本进行去噪、分词、词性标注及实体识别,筛选出与眼部症状、体征相关的核心词汇,如“瘙痒”“畏光”等;二是结构化推理与输出,依托已训练完成的模型,结合NLP(自然语言处理技术)的语义关联分析能力及AI大模型(适用于医学领域的自研大模型,在中文医学AI大模型领域公开评测中多次位列第一)对临床文本上下文语义的精准捕捉能力,有效规避歧义文本干扰,直接通过模型推理判断各目标字段的“是/否”属性,最终形成标准化的结构化数据。
示例:针对“是否有过敏性结膜炎”字段的提取。模型首先从临床文本中识别关键线索,若主诉包含“眼部瘙痒、反复发作”,现病史提及“接触花粉后症状加重”,专科检查记录“眼睑结膜滤泡增生、结膜充血”,辅助检查提示“血清IgE升高”,结合NLP语义关联分析,AI大模型可精准匹配过敏性结膜炎的典型特征,最终输出该字段结果为“是”;若文本中无上述相关特征,且未提及过敏性结膜炎相关诊断,则输出“否”。
数据内容:
转换后形成标准化结构化数据集,标准化涵盖统一眼轴长度、散光轴向等指标单位与范围,结构化则将非结构化的病例主诉、现病史等文本信息拆解为可统计分析的字段,最终包含患者基线特征、合并症状、用药情况、眼科检查结果、治疗方式等核心内容,为后续场景应用提供高质量数据支持。
提供机构:
温州医科大学附属眼视光医院
创建时间:
2026-01-14
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集整合了近视患者的临床诊疗与医疗资源利用数据,涵盖人口学、就诊、诊断、病历、眼科检查及药品/非药品医嘱等92个字段、共10000条记录。数据经匿名化、标准化和结构化处理,并利用NLP与AI大模型技术从非结构化文本中提取关键症状信息,可用于近视精准诊断、药械疗效量化评估及公共卫生政策制定等研究场景。
以上内容由遇见数据集搜集并总结生成


