Good-Sicilian-in-NLLB
收藏Hugging Face2024-07-11 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Napizia/Good-Sicilian-in-NLLB
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是从Meta AI发布的挖掘双语文本的元数据中创建的子集,包含1,057,469对经过Napizia模型评分的英西翻译对,旨在帮助NLP社区训练高质量的西西里语语言模型。
创建时间:
2024-07-10
原始信息汇总
Good Sicilian in the NLLB
数据集概述
语言和任务类别
- 语言: 英语 (en), 西西里语 (scn)
- 任务类别: 翻译
数据集名称和大小
- 名称: Good Sicilian in the NLLB
- 大小: 100K<n<1M
数据集目的
- 识别并提供高质量的西西里语翻译数据,以帮助自然语言处理(NLP)社区训练更好的西西里语语言模型。
数据集来源
- 数据集是从Meta AI发布的挖掘双语文本元数据中创建的子集。
- 包含1,057,469对从OPUS集合中评分过的英语到西西里语翻译数据。
许可证信息
- 数据集遵循ODC-BY许可协议。
相关文献
- A. Fan et al (2020). "Beyond English-Centric Multilingual Machine Translation."
- K. Hefferman et al (2022). "Bitext Mining Using Distilled Sentence Representations for Low-Resource Languages."
- NLLB Team et al (2022). "No Language Left Behind: Scaling Human-Centered Machine Translation."
- H. Schwenk et al (2021). "CCMatrix: Mining Billions of High-Quality Parallel Sentences on the Web."
- J. Tiedemann (2012). "Parallel Data, Tools and Interfaces in OPUS."
- E. Wdowiak (2021). "Sicilian Translator: A Recipe for Low-Resource NMT."
- E. Wdowiak (2022). "A Recipe for Low-Resource NMT."
搜集汇总
数据集介绍
构建方式
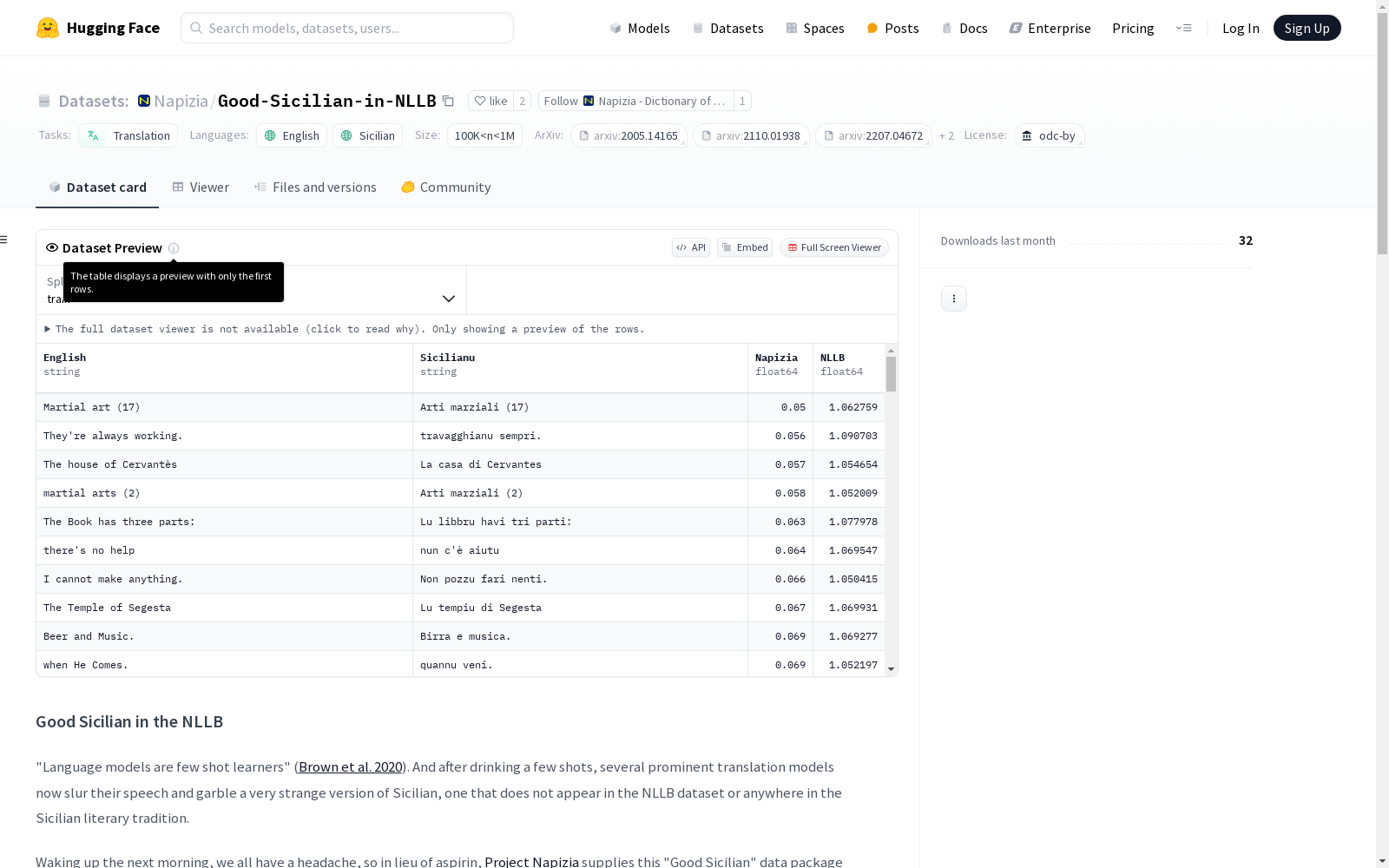
Good-Sicilian-in-NLLB数据集的构建基于Meta AI发布的NLLB-200vo项目中的双语文本数据。通过使用stopes挖掘库和LASER3编码器,原始数据包含了148种以英语为中心和1465种非英语为中心的语言对。随后,Allen AI为Hugging Face和OPUS准备了双语数据集。本数据集从中筛选出1,057,469对英语-西西里语文本,并由Project Napizia通过其翻译模型对这些文本进行评分,以识别符合“Good Sicilian”标准的翻译。
特点
该数据集的特点在于其专注于西西里语的文学传统,而非方言或地方发音。通过Project Napizia的翻译模型评分,数据集筛选出符合“Good Sicilian”标准的文本,这些文本反映了西西里语800年的文学传统。数据集还提供了两种评分标准:Napizia的负对数概率评分和Facebook的句子相似度评分,帮助研究人员更好地评估翻译质量。
使用方法
该数据集的使用方法主要包括通过提供的评分标准筛选高质量的英语-西西里语翻译对。研究人员可以利用这些数据训练更精确的西西里语语言模型。数据集以CSV格式提供,包含50,000对评分最高的翻译对,便于研究人员快速获取高质量数据。此外,数据集的使用需遵循ODC-BY许可,并遵守原始数据源的条款和许可。
背景与挑战
背景概述
Good-Sicilian-in-NLLB数据集由Project Napizia于2022年推出,旨在为自然语言处理(NLP)社区提供高质量的西西里语翻译数据。该数据集的创建源于Meta AI的No Language Left Behind(NLLB)项目,该项目致力于为低资源语言提供机器翻译支持。然而,NLLB项目在西西里语数据收集过程中遇到了标准化问题,导致数据质量不佳。Project Napizia通过与Arba Sicula合作,利用其自1979年以来积累的西西里语文学翻译资源,构建了这一数据集,以弥补NLLB项目在西西里语翻译中的不足。该数据集不仅为西西里语的机器翻译提供了高质量的训练数据,还推动了低资源语言在NLP领域的研究与应用。
当前挑战
Good-Sicilian-in-NLLB数据集面临的主要挑战包括两个方面。首先,西西里语作为一种低资源语言,其标准化程度较低,尤其是在拼写和语法方面存在显著的区域差异。NLLB项目在数据收集过程中依赖了2017年提出的新拼写方案,这与历史上广泛使用的西西里语文本存在较大差异,导致数据质量下降。其次,数据集的构建过程中需要从大量混杂的方言和文学语言中筛选出符合“Good Sicilian”标准的文本,这对语言模型的训练提出了更高的要求。此外,如何有效评估和验证翻译模型在西西里语上的表现,也是一个亟待解决的问题。这些挑战不仅影响了数据集的构建,也对后续的模型训练和应用提出了更高的技术要求。
常用场景
经典使用场景
在自然语言处理领域,Good-Sicilian-in-NLLB数据集主要用于提升西西里语与英语之间的机器翻译质量。该数据集通过筛选和评分NLLB数据集中的西西里语翻译对,帮助研究人员训练出更准确的西西里语语言模型。特别是在处理低资源语言时,该数据集为模型提供了高质量的翻译样本,使其能够更好地捕捉西西里语的文学传统和语言特征。
解决学术问题
Good-Sicilian-in-NLLB数据集解决了低资源语言机器翻译中的关键问题,尤其是在西西里语这种缺乏标准化数据的语言上。通过提供高质量的翻译对,该数据集弥补了NLLB项目中西西里语数据的不足,帮助模型避免因数据质量低下而导致的翻译错误。此外,该数据集还为研究低资源语言的翻译模型提供了宝贵的实验数据,推动了多语言机器翻译领域的发展。
衍生相关工作
Good-Sicilian-in-NLLB数据集的发布催生了一系列相关研究,特别是在低资源语言机器翻译领域。例如,基于该数据集的研究工作进一步优化了西西里语的翻译模型,并探索了如何将类似方法应用于其他低资源语言。此外,该数据集还启发了对多语言翻译模型的评估方法研究,推动了NLP领域对低资源语言处理技术的深入探索。
以上内容由遇见数据集搜集并总结生成


