bluesky-five-million
收藏Hugging Face2024-11-30 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/Roronotalt/bluesky-five-million
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含从Bluesky Social的firehose API收集的500万条公开帖子,主要用于机器学习研究和社会媒体数据实验。数据集包括帖子类型、文本、创建日期、作者信息和嵌入内容等多种特征。由Roro策划,并根据MIT许可证授权。可用于研究社交媒体趋势、内容审核和对话结构。数据集可通过Hugging Face数据集库下载和加载。
创建时间:
2024-11-30
原始信息汇总
Five Million Bluesky Posts 数据集
概述
该数据集包含从Bluesky Social的firehose API收集的500万条公共帖子,旨在用于机器学习研究和社交媒体数据的实验。
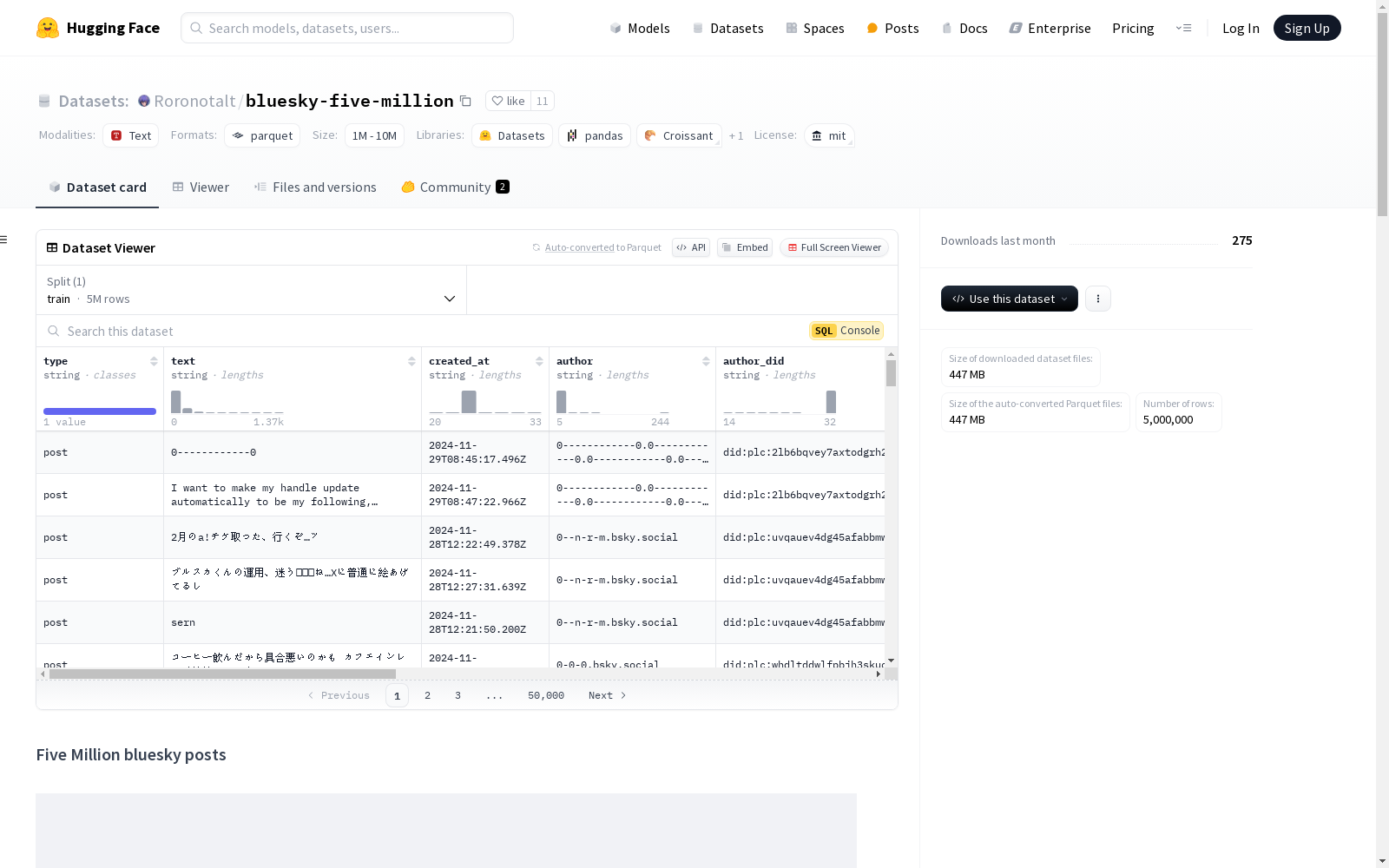
数据集结构
- 特征:
type: 字符串类型text: 字符串类型created_at: 字符串类型author: 字符串类型author_did: 字符串类型uri: 字符串类型embedded_array: 列表类型alt: 字符串类型blob: 字符串类型type: 字符串类型
langs: 字符串序列reply_to: 字符串类型
- 分割:
train: 包含500万个样本,大小为1754581344字节
- 下载大小: 740945960字节
- 数据集大小: 1754581344字节
使用场景
该数据集可用于以下研究:
- 研究社交媒体趋势
- 研究社交媒体内容审核
- 研究对话结构和回复网络
数据集加载
数据集可以通过Hugging Face的load_dataset()函数下载和加载。
数据集转换
数据集可以转换为Pandas DataFrame,并保存为CSV文件。
数据集处理
数据集未经筛选,排序或质量控制。去重是基于帖子URI进行的。数据集按作者列排序。
搜集汇总
数据集介绍
构建方式
该数据集名为‘bluesky-five-million’,由Roro精心策划,通过Bluesky Social的firehose API收集了500万条公开帖子。这一数据集的构建灵感来源于Alpindales的200万帖子数据集,但在此基础上进行了扩展,不仅包含了更多的数据,还特别收集了帖子中的图像及其元数据,这些信息对于机器学习研究具有潜在的巨大价值。数据集的构建过程中,作者还进行了去重处理,依据帖子的URI进行去重,并按作者列进行了排序。
特点
‘bluesky-five-million’数据集的显著特点在于其庞大的数据量和丰富的内容类型。该数据集不仅包含了文本信息,还涵盖了图像及其描述,这为多模态学习提供了可能。此外,数据集的结构设计合理,包含了帖子类型、创建时间、作者信息、URI等关键字段,使得数据集在研究社交媒体趋势、内容审核及对话结构等方面具有广泛的应用潜力。
使用方法
该数据集可通过HuggingFace的load_dataset()函数进行下载和加载,支持直接作为迭代流处理,以节省内存,或转换为Pandas DataFrame进行进一步分析。用户需安装pandas、pyarrow、datasets和huggingface_hub库。此外,数据集的Parquet文件格式也支持转换为CSV格式,便于不同需求下的数据处理和分析。
背景与挑战
背景概述
在社交媒体数据分析领域,Bluesky Five Million数据集的诞生标志着对大规模社交平台内容研究的进一步深化。该数据集由Roro精心策划,收录了从Bluesky Social的firehose API中提取的500万条公开帖子,旨在为机器学习研究者提供丰富的社交数据资源。这一数据集的创建灵感源自Alpindales的200万帖子数据集,但在此基础上进行了扩展,不仅包含了更多的数据,还增加了作者信息、图像URL及元数据等关键内容。这些数据的整合为研究社交趋势、内容审核及对话结构提供了宝贵的资源。
当前挑战
尽管Bluesky Five Million数据集为社交数据研究提供了丰富的资源,但其构建与应用过程中仍面临诸多挑战。首先,数据集的原始格式中,图像引用字节尚未解析为可直接使用的图像或blob URL,这为后续的图像处理和分析带来了技术难题。其次,数据集的未过滤状态意味着研究者在使用前需自行进行质量筛选和内容审核,这增加了数据预处理的复杂性。此外,如何高效地处理和分析如此大规模的数据,尤其是在内存有限的情况下,也是研究者需要克服的技术挑战。
常用场景
经典使用场景
bluesky-five-million数据集的经典使用场景主要集中在社交媒体数据的机器学习研究中。研究者可以利用该数据集进行社交网络趋势分析、内容审核模型训练以及对话结构和回复网络的研究。通过分析大规模的公开帖子,研究者能够深入理解社交媒体上的用户行为模式和内容传播机制,从而为相关领域的研究提供丰富的数据支持。
解决学术问题
该数据集解决了社交媒体研究中常见的数据稀缺问题,尤其是在大规模数据收集和处理方面。通过提供五百万条公开帖子,研究者可以进行更广泛的数据驱动研究,如社交网络中的内容传播、用户互动模式以及内容审核策略的有效性评估。这不仅推动了社交媒体分析领域的学术进展,还为相关政策制定提供了科学依据。
衍生相关工作
基于bluesky-five-million数据集,研究者已开展了多项相关工作,包括社交媒体内容生成模型的训练、用户行为预测算法的优化以及社交网络结构分析。这些工作不仅丰富了社交媒体数据分析的理论框架,还为实际应用提供了技术支持。例如,有研究利用该数据集训练了能够自动生成社交媒体内容的模型,进一步推动了自然语言处理技术在社交媒体领域的应用。
以上内容由遇见数据集搜集并总结生成


