RAGuard
收藏arXiv2025-02-22 更新2025-02-26 收录
下载链接:
https://huggingface.co/datasets/UCSC-IRKM/RAGuard
下载链接
链接失效反馈官方服务:
资源简介:
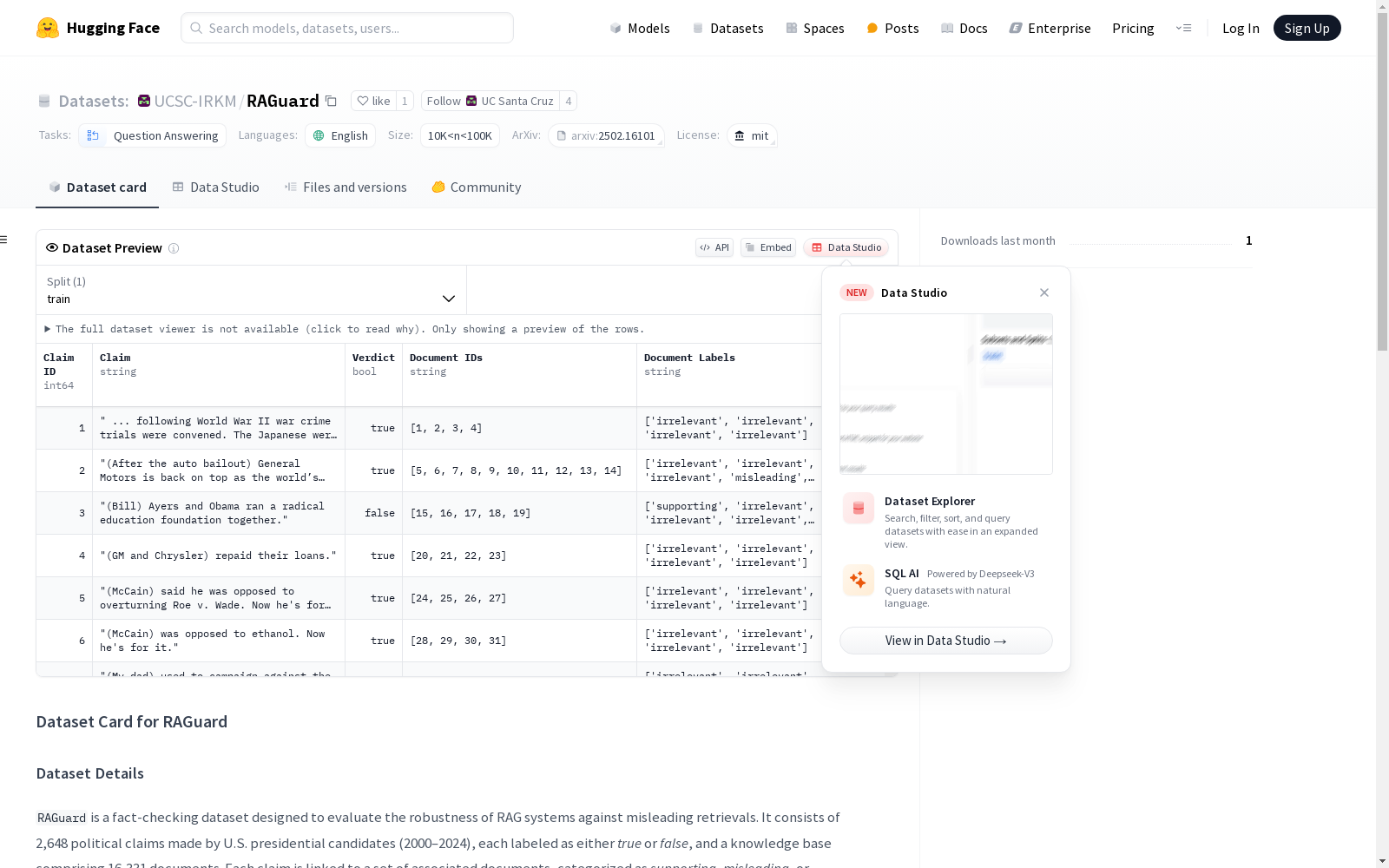
RAGuard是一个针对政治事实核查任务设计的基准数据集,由加州大学圣克鲁兹分校的研究团队创建。该数据集包含2648个政治性声明及其对应的真相核查裁决,以及16331个与之相关的文档,这些文档被标注为支持性、误导性或无关性。数据集的构建目的是为了在包含误导性信息 retrieval 的真实世界场景中,评估 retrieval-augmented generation (RAG) 系统的鲁棒性。
提供机构:
加州大学圣克鲁兹分校
创建时间:
2025-02-22
搜集汇总
数据集介绍
构建方式
RAGuard 数据集的构建方式是通过从 Reddit 讨论中检索相关文档,并使用 LLM 指导的方法对文档进行标注。首先,从 PolitiFact 收集政治声明和事实核查标签。然后,使用 GPT-4 提取每个声明的关键词,并通过 Google 搜索检索相关的 Reddit 帖子。最后,使用 LLM 指导的方法对文档进行标注,将文档分为支持、误导或无关三类,以评估 LLM 在推理过程中的实际行为。
特点
RAGuard 数据集的特点是它包含了真实的政治声明和事实核查标签,以及从 Reddit 讨论中检索到的相关文档。这些文档被标注为支持、误导或无关,以评估 LLM 在推理过程中的实际行为。此外,该数据集还包含了一个知识库,其中包含了 2,648 个政治声明和 16,331 个相关文档。
使用方法
RAGuard 数据集可用于评估 RAG 系统在处理误导性检索信息时的鲁棒性。该数据集支持三种任务配置:无上下文预测、标准 RAG 和 Oracle 检索。无上下文预测任务评估 RAG 系统在没有外部上下文信息的情况下进行事实核查的能力。标准 RAG 任务模拟实时 RAG 系统从整个数据集语料库中检索文档,并评估 RAG 系统在处理包含支持、误导或无关信息的文档时的鲁棒性。Oracle 检索任务提供每个声明的相关文档,以评估 RAG 系统在过滤掉误导性内容时的能力。
背景与挑战
背景概述
检索增强生成(RAG)技术在缓解大型语言模型(LLM)的幻觉问题方面展现出卓越能力。然而,LLM在处理误导性检索时却力不从心,往往无法在遭遇冲突或选择性框架的证据时保持自身的推理能力,这使得它们易受现实世界中的虚假信息的影响。特别是在政治领域,证据常常被选择性框架、不完整或两极分化,而现有的RAG基准测试主要假设一个干净的检索环境,模型通过从黄金标准文档中准确地检索和生成答案来取得成功。这种假设与现实世界的条件不符,导致对RAG系统性能的过高估计。为了弥合这一差距,我们引入了RAGuard,这是一个事实检查数据集,旨在评估RAG系统在面对误导性检索时的鲁棒性。与之前依赖合成噪声的基准测试不同,我们的数据集从Reddit讨论中构建检索语料库,捕捉自然发生的虚假信息。它将检索到的证据分为三类:支持性、误导性和不相关性,为评估RAG系统在不同检索信息中导航的能力提供了一个现实和具有挑战性的测试平台。我们的基准测试实验表明,当暴露于误导性检索时,所有测试的LLM驱动的RAG系统的表现都劣于它们的零样本基线(即根本没有检索),突出了它们在噪声环境中的易受攻击性。据我们所知,RAGuard是第一个系统地评估RAG对误导性证据的鲁棒性的基准测试。我们期望这个基准测试将推动未来研究朝着在理想化数据集之外改进RAG系统的方向发展,使它们更适合现实世界的应用。
当前挑战
RAGuard数据集的挑战主要在于评估RAG系统在面对误导性检索时的鲁棒性。具体挑战包括:1) RAG系统在处理现实世界中的误导性和冲突性信息时的表现;2) 构建过程中如何从Reddit讨论中获取相关但可能误导性的文档,并对其进行分类。此外,现有的RAG基准测试主要假设一个干净的检索环境,这导致对RAG系统性能的过高估计。因此,RAGuard数据集的引入旨在提供一个更贴近现实世界的测试平台,以评估RAG系统在处理误导性和冲突性信息时的鲁棒性。
常用场景
经典使用场景
RAGuard 数据集主要被用于评估检索增强生成(RAG)系统在面对误导性检索内容时的鲁棒性。该数据集收集了真实世界中的政治言论和相关事实核查结果,并通过 Reddit 讨论中的自然发生的信息构建了检索语料库。RAGuard 将检索到的证据分为三类:支持性、误导性和无关性,为评估 RAG 系统如何在不同检索信息中导航提供了现实且具有挑战性的测试环境。
解决学术问题
RAGuard 数据集解决了现有 RAG 基准测试大多假设一个干净的检索设置的问题,这些模型通过从黄金标准文档中准确检索和生成答案来取得成功。然而,这种假设与现实世界条件不符,导致了对 RAG 系统性能的过高估计。RAGuard 通过引入自然发生的误导性信息,为评估 RAG 系统在面对现实世界中的冲突和误导性证据时的表现提供了基础。
衍生相关工作
RAGuard 数据集的引入推动了未来研究向改进 RAG 系统的方向发展,使其能够在现实世界的应用中更加可靠。此外,RAGuard 还促进了对抗性检索训练、不确定性感知检索、多步推理和跨文档一致性检查等技术的发展,这些技术可以帮助模型更好地处理误导性内容,并提高其准确性。
以上内容由遇见数据集搜集并总结生成


