FremyCompany/Asclepius-Synthetic-Clinical-Notes-QA-EN
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/FremyCompany/Asclepius-Synthetic-Clinical-Notes-QA-EN
下载链接
链接失效反馈官方服务:
资源简介:
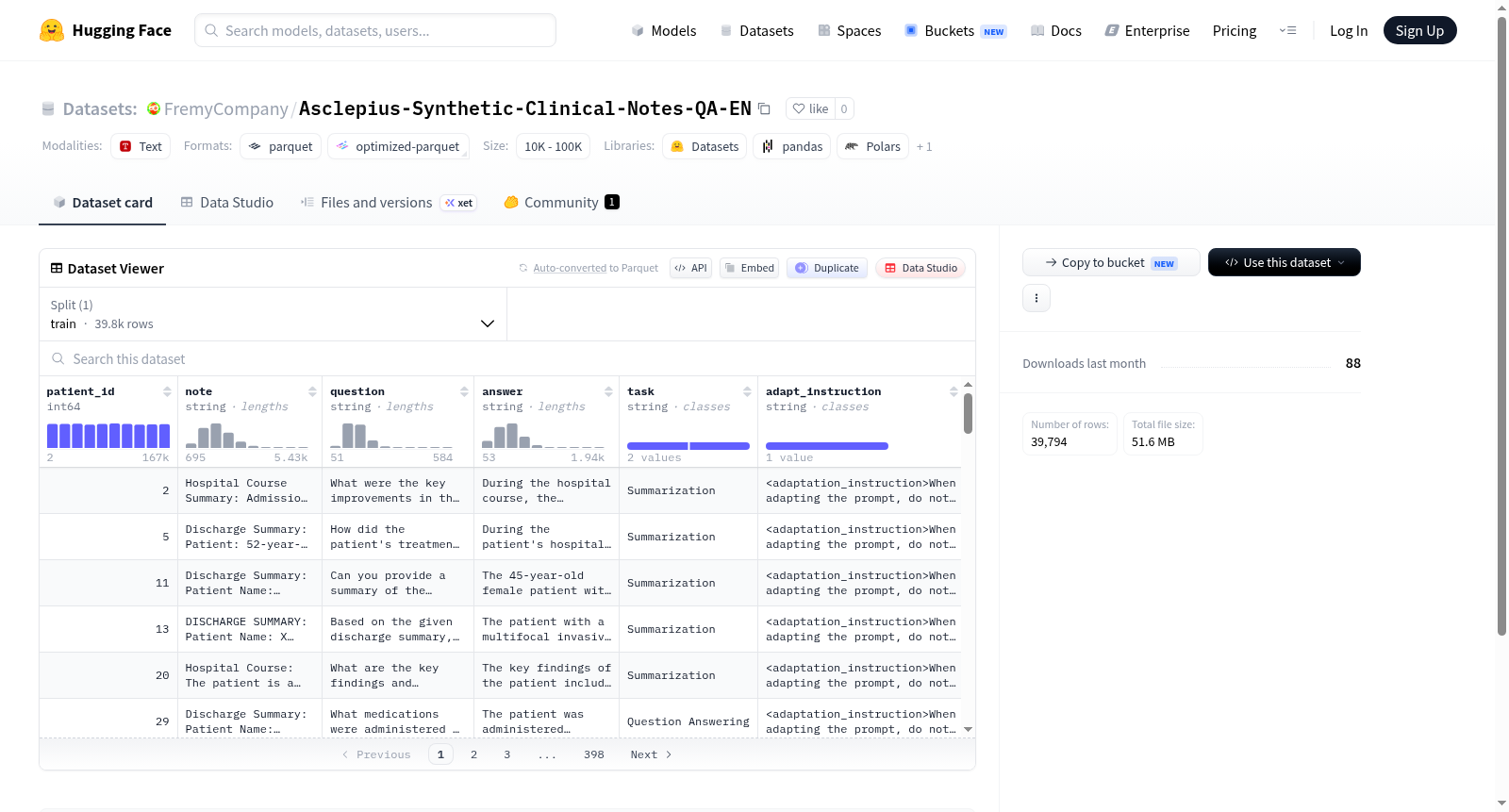
该数据集是一个医疗问答数据集,包含患者ID、医疗笔记、问题、答案、任务类型和适应指令等特征。数据仅包含训练集,共有39794个示例,用于支持自然语言处理任务,如问答和指令适应。数据集可能用于医疗领域的文本分析和模型训练。
This dataset is a medical question-answering dataset that includes features such as patient ID, medical notes, questions, answers, task types, and adaptation instructions. It contains only a training split with 39,794 examples, designed to support natural language processing tasks like question answering and instruction adaptation, potentially for healthcare text analysis and model training.
提供机构:
FremyCompany
搜集汇总
数据集介绍
构建方式
在临床自然语言处理领域,高质量标注语料的稀缺性始终是制约模型性能提升的核心瓶颈。为此,Asclepius-Synthetic-Clinical-Notes-QA-EN数据集应运而生,其构建以合成数据生成技术为基石,通过模拟真实临床场景中的医患互动,从电子健康记录中抽取结构化信息,并自动生成与之对应的问答对。每个样本包含患者标识符、临床笔记文本、自然语言问题、专家级答案、任务类型以及适应性指令字段,最终形成近四万条具有高度领域相关性的训练实例,为下游模型提供了丰富的语义对齐基础。
特点
该数据集呈现出鲜明的领域专精与结构严谨两大特征。首先,所有数据均以英文临床笔记为源文本,覆盖诊断、治疗方案、检验结果解读等多类医疗任务,确保了医学语义的深度与广度;其次,每一条记录均附有适配指令字段,使得数据天然适用于指令微调范式,能够引导模型理解并执行特定医疗提问任务。此外,数据集的容量控制在约123MB,兼具可负担的存储成本与充足的样本多样性,为研究人员在资源受限场景下进行模型迭代提供了便利。
使用方法
使用Asclepius-Synthetic-Clinical-Notes-QA-EN数据集时,推荐采用标准的序列到序列训练框架。研究者可直接加载默认配置下的训练分割,利用其提供的patient_id进行样本去重与关联,并依据task字段筛选所需子任务数据。在模型输入阶段,可将adapt_instruction与question拼接作为提示前缀,以answer作为监督标签,从而高效实现临床问答系统的指令微调。该数据集亦可作为评估基准,用于测试预训练语言模型在零样本或少样本设定下的医学推理能力。
背景与挑战
背景概述
Asclepius-Synthetic-Clinical-Notes-QA-EN数据集诞生于医疗人工智能快速发展的背景下,由致力于临床自然语言处理的研究团队构建,旨在解决真实临床数据获取困难与隐私保护之间的核心矛盾。该数据集通过合成技术生成英文临床笔记及其对应的问答对,涵盖多种医疗任务类型,如诊断推理、治疗方案查询等,为大规模预训练语言模型在医疗领域的微调与评估提供了高质量的训练资源。其创建时间虽未明确标注,但依托于开源社区HuggingFace的发布,迅速成为连接合成临床数据与智能医疗问答系统的重要桥梁,推动了医学文本理解与生成任务的研究进展。
当前挑战
该数据集面临的挑战主要集中在两方面。首先,在领域层面,临床问答任务要求模型具备高度的医学专业性与推理能力,而合成数据可能无法完全模拟真实临床场景中的噪声、歧义及罕见病例,导致模型泛化至实际应用时性能受限。其次,构建过程中,合成临床笔记需平衡医学真实性与患者隐私保护,确保生成的文本既符合临床逻辑又不泄露任何个人健康信息。此外,数据覆盖的疾病种类、治疗策略和问诊模式的多样性也需精心设计,以避免引入偏见或遗漏关键医疗情境,这对合成算法的全面性与质量控制提出了严苛要求。
常用场景
经典使用场景
在临床自然语言处理与医学人工智能的交叉领域,问答系统始终是评估模型对非结构化临床文本理解能力的核心任务。Asclepius-Synthetic-Clinical-Notes-QA-EN数据集专为此类场景设计,其包含近四万条由合成临床笔记生成的问答对,覆盖了病历摘要、诊断推理、治疗方案解读等经典临床信息抽取与推理任务。研究者可借此构建与评估面向电子健康记录的自动问答模型,推动医学语言模型在信息检索、病情摘要生成和临床决策支持中的基准测试。
实际应用
在实际临床场景中,该数据集驱动的问答模型可辅助医疗工作者快速定位病历中的关键信息,例如患者既往病史、药物使用细节或检验检查结果。基于此类模型,医院能够开发智能病历检索工具,减少医生翻阅冗长文档的耗时;同时,模型还能支持自动化的医疗质量控制,通过比对病历记录与诊疗指南,识别潜在的遗漏或错误,进而提升诊疗效率与患者安全。
衍生相关工作
围绕该数据集,学术界已涌现若干衍生研究方向。其中最具代表性的是将医学问答任务与指令微调范式相结合的工作,研究者通过adapt_instruction字段提供的指令模板,对大型语言模型进行领域特定的对齐训练,显著提升了模型在临床语境下的指令遵循能力。此外,该数据集也被用于评测多模态医学模型的文本理解模块,以及作为预训练-微调策略中下游任务的基准,推动了医学自然语言处理领域从通用模型向专科化、可交互系统的演进。
以上内容由遇见数据集搜集并总结生成


