MedGPTEval
收藏arXiv2023-05-12 更新2024-06-21 收录
下载链接:
https://qr02.cn/DBeS9U
下载链接
链接失效反馈官方服务:
资源简介:
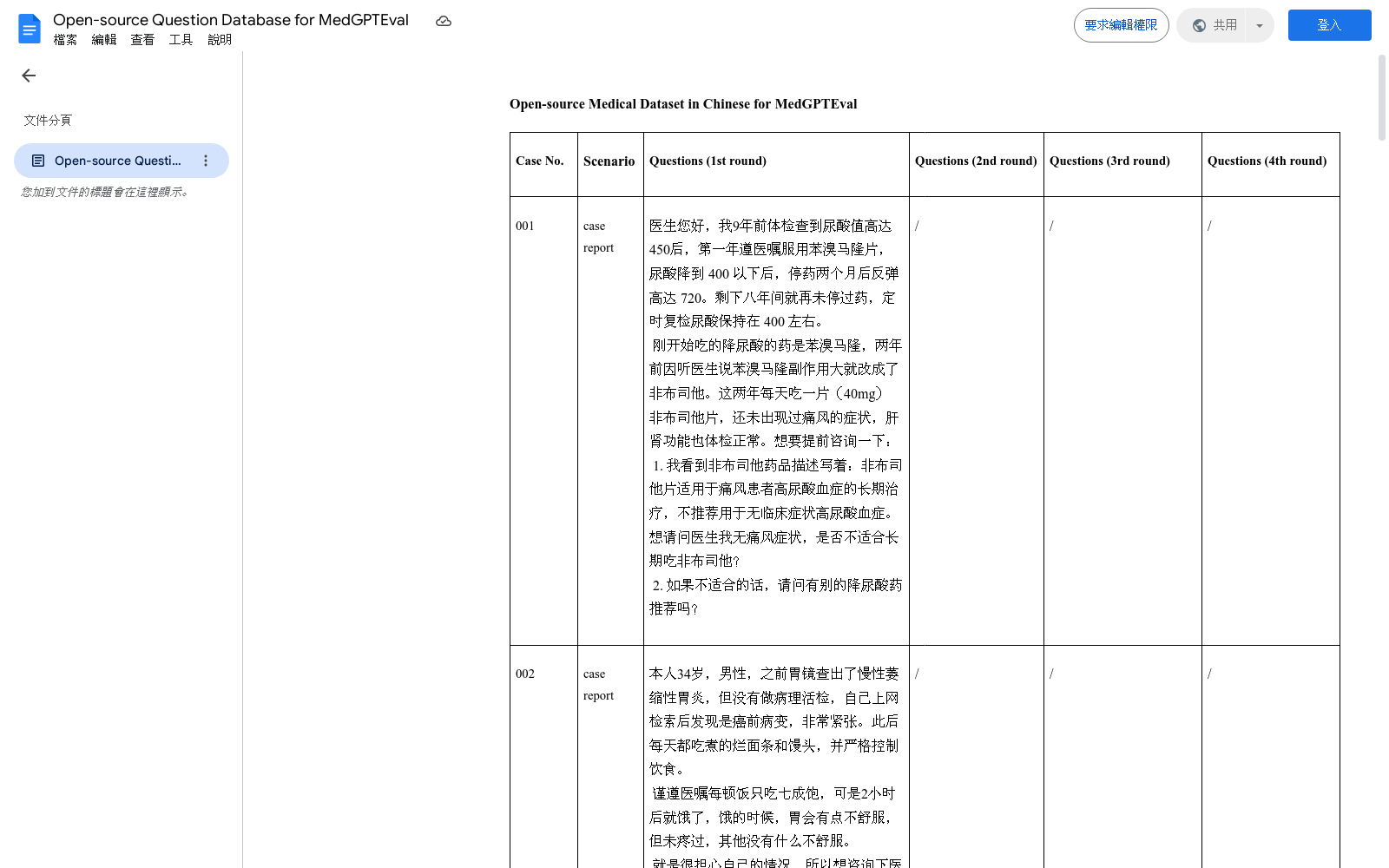
MedGPTEval是由上海人工智能实验室与多家医疗机构合作开发的中文医学数据集,包含27个多轮对话和7个病例报告,总计34个案例。数据集涵盖了14种疾病,从系统性疾病到意外伤害,旨在评估大型语言模型在医学领域的专业能力和社交综合能力。创建过程中,由临床专家设计数据集内容,确保与大型语言模型的交互质量。该数据集主要用于评估模型在医学对话和病例报告处理中的表现,解决模型在医学应用中可能产生的安全风险问题,如幻觉(不完全可靠的响应)。
MedGPTEval is a Chinese medical dataset developed by Shanghai AI Laboratory in collaboration with multiple medical institutions. It comprises 27 multi-turn dialogues and 7 case reports, totaling 34 cases. The dataset covers 14 types of diseases, ranging from systemic disorders to accidental injuries, and aims to evaluate the professional competence and comprehensive social capabilities of large language models (LLMs) in the medical field. During the development process, clinical experts designed the dataset content to ensure the quality of interactions with large language models. This dataset is primarily used to assess models' performance in medical dialogue and case report processing, and to address potential safety risks arising from medical applications of LLMs, such as hallucinations (incompletely reliable responses).
提供机构:
上海人工智能实验室
创建时间:
2023-05-12
搜集汇总
数据集介绍
构建方式
MedGPTEval数据集的构建基于对现有医疗领域评估标准的深入文献综述,通过专家的德尔菲法对候选标准进行优化,并设计了包含27个医疗对话和7个病例报告的中文医疗数据集,用于与大型语言模型进行交互。这些数据集涵盖了14种疾病类型,包括常见和危急疾病,如糖尿病、胃炎和心力衰竭。为了评估大型语言模型在医疗领域的表现,数据集被用于基准测试,其中ChatGPT、ERNIE Bot和Doctor PuJiang三个聊天机器人基于生成的回答被五位有执照的医疗专家进行了盲评。
特点
MedGPTEval数据集的特点在于其全面性,它不仅包括医疗专业能力,还包括社会综合能力、语境能力和计算鲁棒性。数据集包含了16个详细的指标,用于评估大型语言模型在医疗领域的表现。此外,数据集还包含了中文医疗对话和病例报告,这些数据集旨在评估大型语言模型在处理医疗场景中的对话和病例报告时的能力。数据集的另一个特点是它采用了盲评方式,以确保评估结果的客观性和公正性。
使用方法
MedGPTEval数据集的使用方法包括以下步骤:首先,根据文献综述和专家意见,设计一套评估标准;其次,创建中文医疗数据集,包括医疗对话和病例报告;然后,基于数据集进行基准测试,记录聊天机器人的回答;最后,由五位有执照的医疗专家对聊天机器人的回答进行盲评。评估结果将用于评估聊天机器人在医疗领域的表现,并根据评估标准对聊天机器人进行排名。此外,数据集还包含了14种疾病类型,包括常见和危急疾病,如糖尿病、胃炎和心力衰竭,这为评估聊天机器人在处理各种医疗场景时的能力提供了便利。
背景与挑战
背景概述
随着大型语言模型(LLMs)在自然语言处理任务中的显著进步,其在医疗领域的应用潜力也逐渐显现。然而,LLMs在医疗领域生成幻觉(不可靠的响应)的风险使得患者安全面临严重威胁。为了评估LLMs在医疗领域的表现并构建系统性的评估体系,MedGPTEval数据集应运而生。该数据集由上海人工智能实验室、新华医院、四川大学华西医院等多家机构的研究人员共同开发,旨在为医疗领域LLMs的评估提供一套全面的评价标准和数据集。MedGPTEval数据集的创建时间尚未明确提及,但根据论文发表时间为2023年5月12日,可以推测其创建时间应早于此。
当前挑战
MedGPTEval数据集面临的主要挑战包括:1)LLMs缺乏鲁棒性,其性能对提示高度敏感,需要进行深入的研究来评估其鲁棒性;2)LLMs的评价标准至关重要,现有的自动指标(如BLEU、ROUGE、准确率)不足以应对医疗领域中的实际场景,需要考虑其他因素,如响应的逻辑一致性、社交特征和上下文理解能力等;3)医疗数据集的规模有限,需要扩大数据集规模以构建更全面的评估体系;4)LLMs的开发需要严格的监督以确保医疗专业性,同时需要考虑人文关怀在医患沟通中的重要性;5)LLMs的模型输出可能受到不同提示的影响,需要评估不同的提示策略以选择适合医疗场景的策略。
常用场景
经典使用场景
MedGPTEval数据集主要被用于评估大型语言模型(LLM)在医学领域的响应能力。该数据集通过设计一套全面的评估标准,包括医学专业能力、社交综合能力、上下文能力和计算鲁棒性等16个详细指标,为研究人员提供了一个系统性的评估框架。此外,该数据集包含了27个中文医疗对话和7个病例报告,为LLM的交互提供了丰富的场景。通过MedGPTEval数据集,研究人员可以全面评估LLM在医疗场景下的表现,从而提高LLM在医学领域的可靠性和安全性。
衍生相关工作
MedGPTEval数据集衍生了许多相关的研究工作。例如,基于MedGPTEval数据集,研究人员可以开发新的评估方法,以更全面地评估LLM在医疗场景下的表现。此外,研究人员还可以基于MedGPTEval数据集,开发新的医学应用程序,以提高医学服务的质量和效率。例如,研究人员可以开发基于LLM的智能医疗咨询系统,以提供更准确、更全面的医疗建议。
数据集最近研究
最新研究方向
在医学领域,大型语言模型(LLMs)的响应评估是一个关键的前沿研究方向。MedGPTEval数据集为评估LLMs在医学领域的响应提供了一个全面的标准和基准。该数据集包含27个中文医疗对话和7个病例报告,旨在评估LLMs在医疗专业能力、社交综合能力、语境能力和计算鲁棒性方面的表现。研究结果表明,针对医学领域进行微调的LLM,如Doctor PuJiang(Dr. PJ),在多轮医疗对话和病例报告场景中优于ChatGPT和ERNIE Bot。这一发现突显了针对特定领域进行模型微调的重要性,以及评估LLMs在实际医疗场景中表现的需求。此外,研究还强调了评估系统的局限性和LLMs发展的挑战,例如主观评分、数据集规模限制以及模型鲁棒性问题。未来的研究将致力于结合自动化模型评估,扩大评估数据集,并探索更复杂的模型参数以提升模型性能。
相关研究论文
- 1MedGPTEval: A Dataset and Benchmark to Evaluate Responses of Large Language Models in Medicine上海人工智能实验室 · 2023年
以上内容由遇见数据集搜集并总结生成


