WebSRC
收藏arXiv2021-11-08 更新2024-06-21 收录
下载链接:
https://x-lance.github.io/WebSRC/
下载链接
链接失效反馈官方服务:
资源简介:
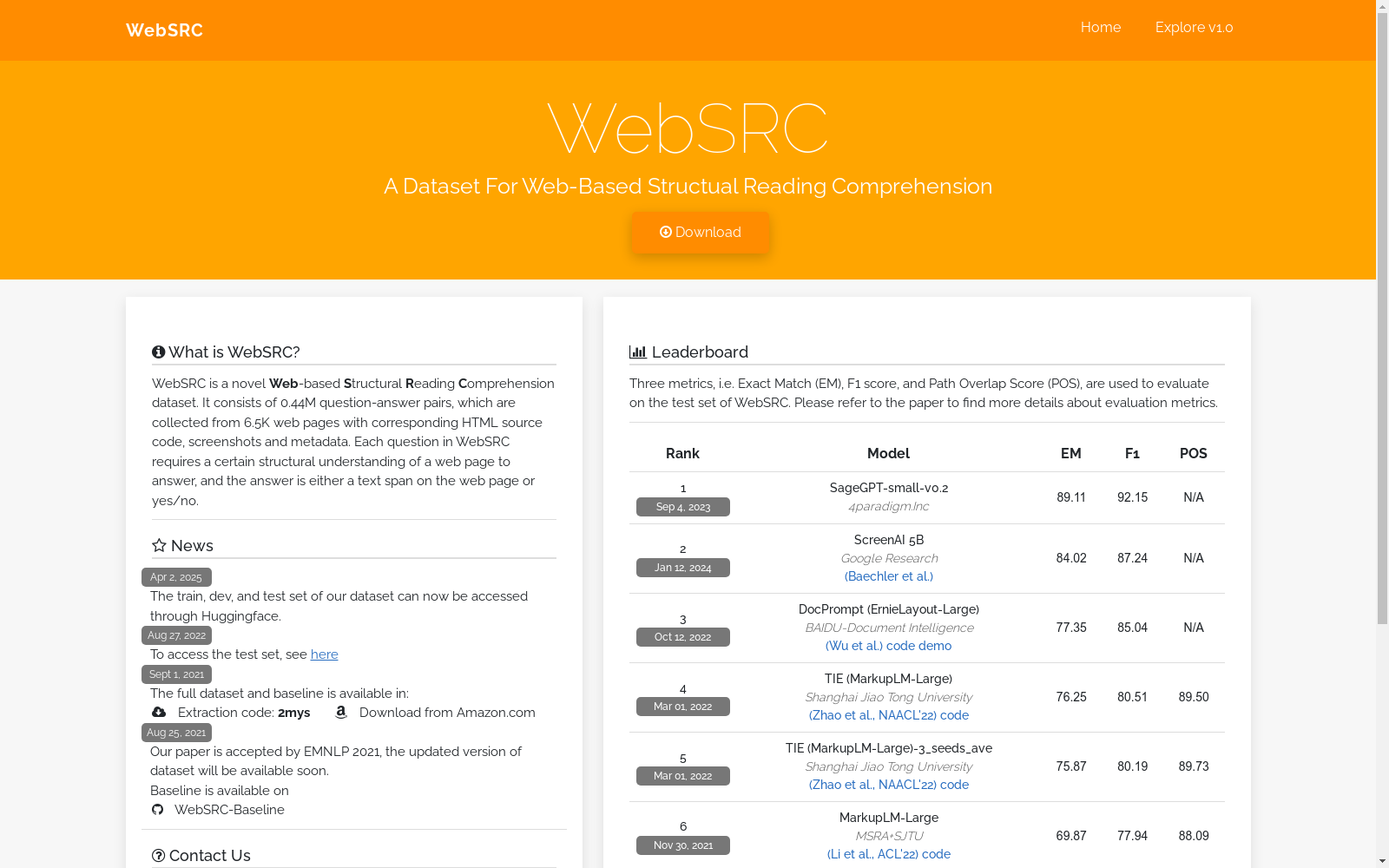
WebSRC是一个专为基于网页的结构化阅读理解任务设计的大型数据集,由上海交通大学开发。该数据集包含40万个问题-答案对,来源于6.4千个网页,每个问题都需要对网页结构有一定的理解才能回答。数据集不仅提供问题答案,还包含相应的HTML源代码、截图及元数据。WebSRC旨在推动网页阅读理解的研究,特别是在理解和利用网页的视觉和结构信息方面,以解决机器在网页内容理解上的挑战。
WebSRC is a large-scale dataset specifically designed for web-based structured reading comprehension tasks, developed by Shanghai Jiao Tong University. This dataset contains 400,000 question-answer pairs sourced from 6,400 web pages, and each question requires a certain level of understanding of web structure to answer. In addition to question-answer pairs, the dataset also provides corresponding HTML source code, screenshots and metadata. WebSRC aims to promote research on web reading comprehension, especially in understanding and leveraging the visual and structural information of web pages, so as to address the challenges faced by machines in web content understanding.
提供机构:
上海交通大学
创建时间:
2021-01-23
搜集汇总
数据集介绍
构建方式
WebSRC数据集的构建分为五个阶段:网页选择、网页收集、问题标注、数据增强和最终审查。首先,从SWDE数据集的网站列表中选取了70个结构复杂且信息丰富的网站。接着,针对每种类型的网页(KV、比较、表格),手动编写提取代码来爬取网页片段。然后,招募标注员对每个网页片段进行问题标注,并鼓励标注员提出实际用户可能会问的问题。为了增强问题的多样性,还进行了问题重写任务。最后,将收集到的问题自动应用于所有同构网页,并通过替换答案生成新的QA对。整个构建过程确保了数据集的质量和多样性。
使用方法
使用WebSRC数据集时,首先需要根据任务需求选择合适的问题类型和答案类型。然后,利用数据集中的HTML代码、截图和元数据,结合问题文本,训练或评估机器阅读理解模型。在训练过程中,可以使用预训练的语言模型,如BERT或ELECTRA,来处理文本内容。对于包含HTML标签和视觉信息的问题,可以采用H-PLM或V-PLM模型进行训练。最后,通过评估指标(如EM、F1和POS)来衡量模型在数据集上的表现,并进行模型优化和调整。WebSRC数据集的多样化问题和丰富的结构信息,为网络结构阅读理解任务的研究提供了有力的支持。
背景与挑战
背景概述
网络搜索是人类获取信息的重要方式,然而对于机器而言,理解网页内容仍然是一个巨大的挑战。为了解决这一问题,上海交通大学X-LANCE实验室的研究人员提出了WebSRC数据集,旨在推动网络结构阅读理解的研究。WebSRC是一个基于网络的结构阅读理解数据集,包含来自6.4K个网页的400K个问答对,以及相应的HTML源代码、截图和元数据。每个问题都需要对网页进行一定的结构理解才能回答,答案可以是网页上的文本跨度或yes/no。该数据集的创建于2021年,由X-LANCE实验室的陈星宇、赵子涵等研究人员共同完成。WebSRC数据集的提出,为网络结构阅读理解的研究提供了重要的数据支持,推动了相关领域的发展。
当前挑战
WebSRC数据集面临的挑战主要包括:1)所解决的领域问题是网络结构阅读理解,这要求系统不仅要理解文本的语义,还要理解网页的结构;2)构建过程中遇到的挑战包括网页结构的多样性和复杂性,以及如何有效地利用结构信息来提高模型的理解能力。此外,WebSRC数据集还面临着如何将视觉信息与文本信息相结合,以及如何处理网页中的噪声信息等问题。
常用场景
经典使用场景
WebSRC数据集在自然语言处理领域,尤其是在结构化阅读理解任务中,具有广泛的应用。该数据集包含了大量的网页问答对,以及对应的HTML源代码、截图和元数据。通过使用WebSRC数据集,研究人员可以训练和评估模型,使其能够理解网页的结构和语义,从而准确回答关于网页内容的问题。WebSRC数据集的经典使用场景包括网页问答系统、信息抽取、知识图谱构建等。
解决学术问题
WebSRC数据集解决了机器阅读理解中网页内容理解的问题。传统的阅读理解模型主要针对文本内容,而WebSRC数据集则引入了HTML结构信息和视觉特征,使得模型能够更好地理解网页的结构和布局,从而提高问答的准确性。此外,WebSRC数据集还提供了多种类型的网页,包括键值对、对比和表格,使得模型能够适应不同类型的网页结构,提高其泛化能力。
实际应用
WebSRC数据集在实际应用中,可以用于构建智能的网页问答系统,帮助用户快速找到所需的信息。此外,WebSRC数据集还可以用于信息抽取任务,自动从网页中提取结构化信息,例如产品信息、新闻事件等。在知识图谱构建方面,WebSRC数据集可以帮助模型理解网页中的实体关系,从而构建更准确的知识图谱。
数据集最近研究
最新研究方向
WebSRC数据集的发布标志着网络结构阅读理解(SRC)任务在机器阅读理解领域的兴起。该数据集包含了400K问答对和6.4K网页片段,旨在促进对网页结构信息的理解和利用。WebSRC的引入,要求模型不仅理解文本的语义,还要理解网页的结构。该数据集为研究多模态机器阅读理解提供了宝贵的资源,并为网页问答系统的发展提供了新的方向。
相关研究论文
- 1WebSRC: A Dataset for Web-Based Structural Reading Comprehension上海交通大学 · 2021年
以上内容由遇见数据集搜集并总结生成


