BioVGQ
收藏arXiv2025-03-04 更新2025-03-06 收录
下载链接:
https://huggingface.co/datasets/jzyang/BioVGQ
下载链接
链接失效反馈官方服务:
资源简介:
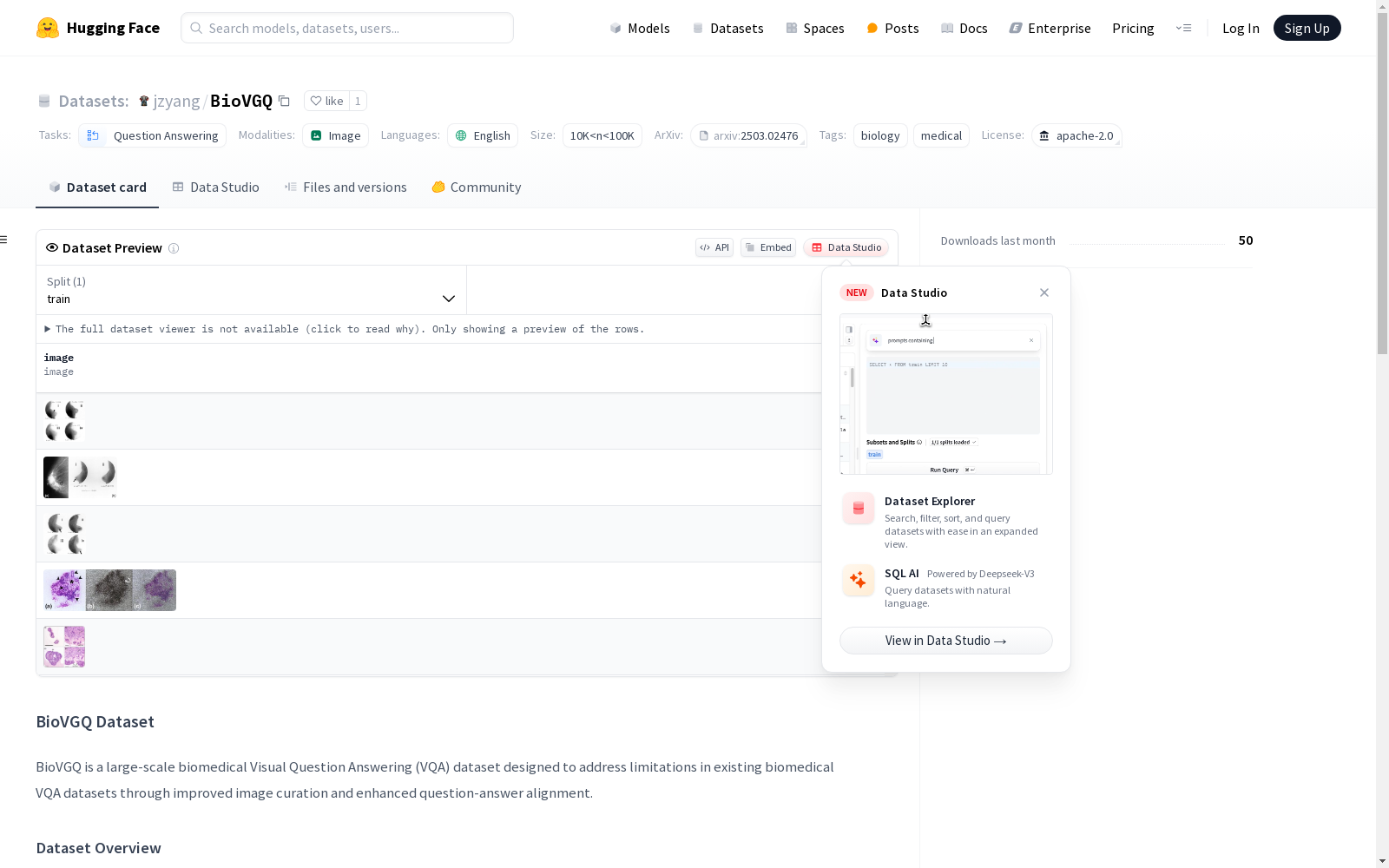
BioVGQ数据集是基于PMC-VQA数据集建立的,包含了经过筛选的77000张清洁的生物医学图像和188000个问题-答案对。该数据集通过整合多个公共数据集,并过滤掉经过显著手动处理的图像,同时利用图像和相应的说明生成问题和答案,以确保问题-答案对与图像内容的高度相关性。数据集的建立旨在解决生物医学视觉问答中的固有偏差问题,并用于训练所提出的BioD2C模型。
The BioVGQ dataset is built upon the PMC-VQA dataset, comprising 77,000 curated clean biomedical images and 188,000 question-answer pairs. This dataset is constructed by integrating multiple public datasets, filtering out images that have undergone significant manual manipulation, and generating question-answer pairs using the images and their corresponding captions to ensure high relevance between the pairs and the image content. The dataset is designed to address the inherent bias issues in biomedical visual question answering and is used for training the proposed BioD2C model.
提供机构:
山东大学, 青岛校区, 中国
创建时间:
2025-03-04
搜集汇总
数据集介绍
构建方式
BioVGQ数据集的构建基于PMC-VQA,通过过滤手动修改的图像并校准问答对与多模态上下文,确保数据集的质量和相关性。具体而言,数据集的构建采用了多尺度特征提取、图像-文本融合机制以及文本队列损失函数等关键技术。
特点
BioVGQ数据集的特点在于:1) 采用多尺度特征提取,能够捕捉图像的不同细节层次;2) 引入图像-文本融合机制,实现特征级别的语义交互;3) 利用文本队列损失函数,进一步优化视觉特征与文本特征的语义对齐。
使用方法
使用BioVGQ数据集时,首先需要对图像进行多尺度特征提取,然后将文本特征与图像特征进行融合,通过文本队列损失函数进行训练,以实现对视觉特征和文本特征的语义对齐。
背景与挑战
背景概述
BioVGQ数据集的研究背景源于生物医学视觉问答(Biomedical Visual Question Answering, BMVQA)领域的发展需求。该数据集由Zhengyang Ji等研究人员于2025年提出,旨在解决现有BMVQA模型在处理复杂任务时存在的模态语义对齐不足的问题。BioVGQ数据集基于现有的PMC-VQA数据集,并整合了多个公开数据集,通过筛选出经过显著手动处理的图像,并利用文本队列机制生成与图像内容强相关的问题-答案对,以增强模型在生物医学视觉问答任务上的表现。该数据集的构建,对于提高BMVQA模型的准确性和泛化能力具有重要意义。
当前挑战
BioVGQ数据集面临的挑战主要包括:1)解决领域问题方面的挑战,即如何实现图像与文本在语义层面上的有效对齐,以提升模型对复杂问题的处理能力;2)构建过程中的挑战,包括如何筛选出与真实医学图像差异较大的图像,以及如何生成与图像内容紧密相关的问题-答案对。
常用场景
经典使用场景
BioVGQ数据集的经典使用场景在于生物医学视觉问答(Biomedical Visual Question Answering, VQA),特别是在辅助医疗诊断领域中。该数据集通过结合文本和图像的特征,使得模型能够理解并回答关于生物医学图像的问题。
衍生相关工作
基于BioVGQ数据集,已经衍生出了一系列相关工作,如BioD2C框架,它通过在模型和特征级别实现双层次的语义一致性约束,进一步优化了视觉问答模型的多模态语义对齐。这些工作不仅提升了模型的性能,也为医学视觉问答领域的发展提供了新的研究方向。
数据集最近研究
最新研究方向
本研究提出了BioD2C框架,一种双层级语义一致性约束的生物医学视觉问答模型。该模型在特征层面通过图像-文本融合机制实现了视觉特征与文本特征的双层级语义交互对齐,并通过基于文本队列的跨模态语义损失函数进一步优化了特征层面的多模态语义对齐。BioD2C框架在BioVGQ数据集上进行了训练,该数据集基于现有的PMC-VQA数据集,并整合了多个公共数据集,通过过滤手动处理的图像并校准问题-答案对与多模态上下文,以解决先前数据集中的内在偏差问题。研究结果表明,BioD2C在多个下游数据集上实现了最先进的性能,展示了其在生物医学视觉问答研究中的强潜力和应用价值。
相关研究论文
- 1BioD2C: A Dual-level Semantic Consistency Constraint Framework for Biomedical VQA山东大学, 青岛校区, 中国 · 2025年
以上内容由遇见数据集搜集并总结生成


