New Yorker Caption Contest Dataset
收藏arXiv2024-06-15 更新2024-06-19 收录
下载链接:
https://huggingface.co/datasets/yguooo/newyorker_caption_ranking
下载链接
链接失效反馈官方服务:
资源简介:
本数据集名为‘New Yorker Caption Contest Dataset’,由威斯康星大学麦迪逊分校创建,包含超过250万条来自《纽约客》每周漫画标题竞赛的人类评分数据。数据集涵盖了过去八年的竞赛内容,总计超过2.5亿次人类评价。创建过程中,通过众包方式收集评分,使用多臂老虎机算法优化展示效果。该数据集主要用于支持大型语言模型和基于偏好的微调算法的发展,特别是在幽默标题生成领域的应用。
This dataset is named the New Yorker Caption Contest Dataset, which was created by the University of Wisconsin-Madison. It contains over 2.5 million human rating records from The New Yorker's weekly cartoon caption contests, covering contests from the past eight years and accumulating a total of more than 250 million human ratings. During the dataset construction, ratings were collected via crowdsourcing, and a multi-armed bandit algorithm was used to optimize the display of contest content. This dataset is primarily intended to support the development of large language models and preference-based fine-tuning algorithms, especially for applications in the field of humorous caption generation.
提供机构:
威斯康星大学麦迪逊分校
创建时间:
2024-06-15
搜集汇总
数据集介绍
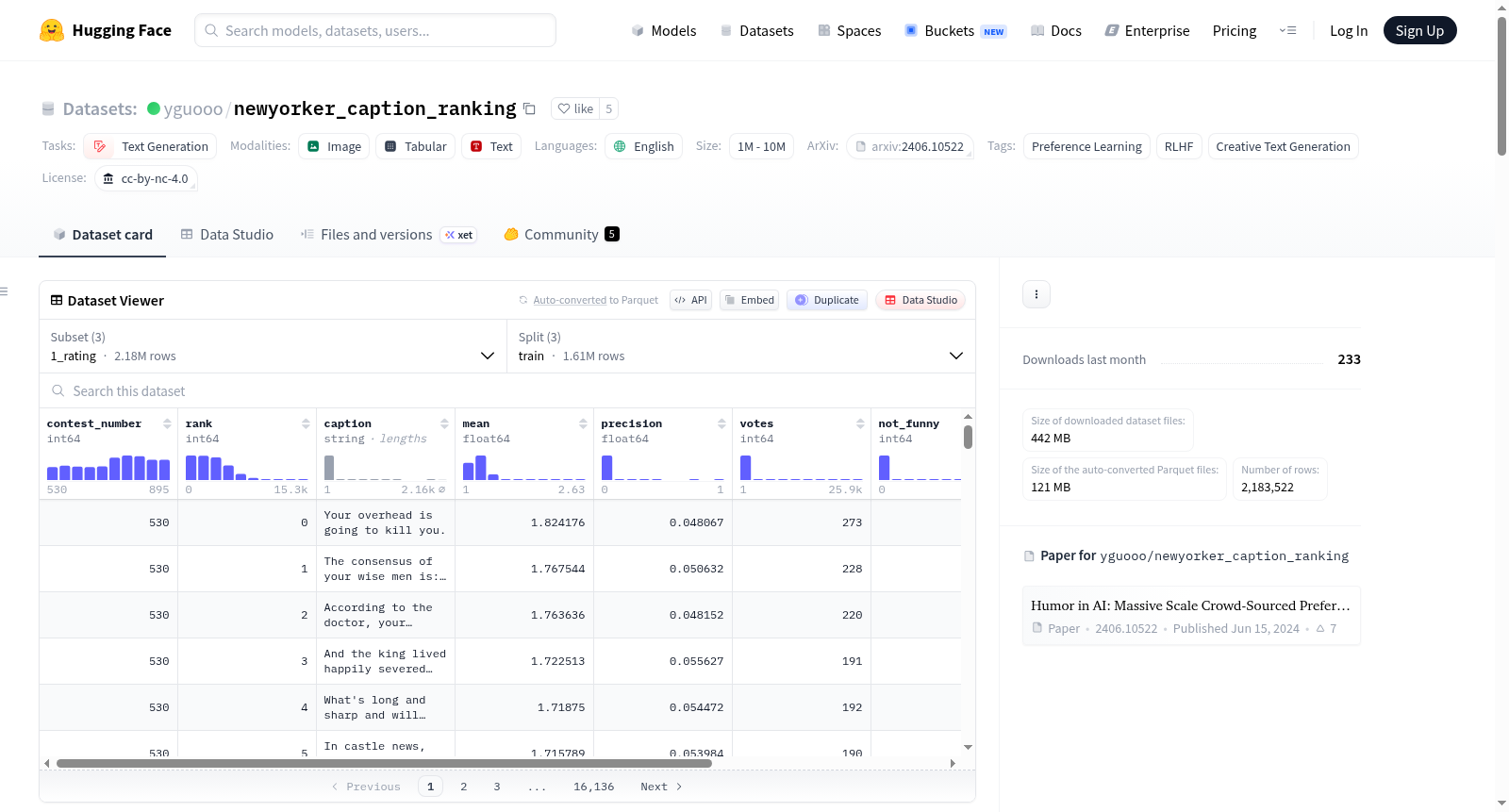
构建方式
在人工智能与幽默研究的交叉领域,New Yorker Caption Contest Dataset的构建体现了大规模众包数据采集的精密设计。该数据集源自《纽约客》杂志长达八年的每周漫画标题竞赛,通过在线众包评分系统收集了超过2.2百万条标题和2.5亿次人类评分。构建过程采用基于多臂老虎机算法的自适应评分机制,优先向用户展示表现较优的标题,从而高效识别幽默内容。所有提交的标题均经过编辑团队初步筛选,排除非幽默性、包含个人信息或冒犯性内容,确保数据质量与伦理合规性。
特点
该数据集的核心特征在于其规模宏大与标注精细。作为首个针对创意任务的大规模人类偏好数据集,它涵盖了365场竞赛的完整记录,包括漫画图像、对应标题及详细评分分布。数据集中每条标题的平均评分约为1.214,而排名前10%的标题平均评分可达1.824,清晰反映了人类对幽默内容的主观评判梯度。其独特价值在于提供了多维度比较基础,支持研究者分析不同排名区间标题的幽默特质差异,为理解幽默生成与感知的复杂性提供了前所未有的实证资源。
使用方法
该数据集主要应用于多模态大语言模型的幽默生成能力评估与对齐策略研究。使用方法包括:将漫画图像或文本描述输入模型,要求生成幽默标题;通过分组比较策略,将模型输出与人类提交的标题组进行整体趣味性评估;利用基于GPT-4的自动化评估框架,量化模型生成标题相对于不同排名人类标题的胜率。此外,数据集支持监督微调、基于人类反馈的强化学习等多种对齐方法的实验验证,为探索创意任务中模型与人类偏好对齐机制提供了标准化测试环境。
背景与挑战
背景概述
《纽约客》漫画标题竞赛数据集作为一项开创性的大规模众包偏好数据集,由威斯康星大学麦迪逊分校、华盛顿大学西雅图分校等机构的研究团队于2024年正式发布。该数据集汇聚了过去八年中《纽约客》周刊漫画标题竞赛的众包评分数据,涵盖超过220万条标题与2.5亿条人类评分,旨在为多模态大语言模型在幽默标题生成任务中的对齐与评估提供坚实支撑。其核心研究问题聚焦于探索人工智能系统在创造性任务——尤其是幽默表达——中与人类偏好对齐的机制,通过量化人类对幽默内容的主观评判,为模型训练与评估构建了前所未有的基准。这一数据集的发布不仅推动了幽默生成领域的研究进展,也为理解多模态语境下的人类价值观对齐提供了关键实证基础。
当前挑战
该数据集所针对的幽默标题生成任务面临多重挑战。首先,幽默本身具有高度主观性与文化依赖性,使得模型生成既符合语境又能引发广泛共鸣的幽默内容极为困难;现有评估方法如RLHF与DPO在创造性任务中表现有限,突显了奖励模型对幽默敏感度捕捉的不足。其次,在数据集构建过程中,研究团队需处理大规模异步众包环境下的算法设计难题,例如采用多臂赌博机变体算法高效筛选高质量标题,并确保评分过程的参与度与数据代表性。此外,数据标注涉及海量人类主观评判,其一致性与可靠性保障亦构成显著挑战,需通过创新评估策略(如群体比较范式)以提升评判信度。
常用场景
经典使用场景
在人工智能与幽默研究的交叉领域,New Yorker Caption Contest Dataset 作为一项开创性的多模态偏好数据集,其经典使用场景聚焦于评估和优化大型语言模型在幽默生成任务中的表现。该数据集通过收集过去八年《纽约客》漫画标题竞赛中超过2.5亿条人类评分,构建了一个包含220万条标题的庞大语料库。研究者利用这一资源,系统性地测试模型在理解漫画视觉语境、生成契合情境且引人发笑的标题方面的能力,从而推动创意内容生成技术的边界。
实际应用
在实际应用层面,New Yorker Caption Contest Dataset 为开发具备幽默感知能力的人工智能系统提供了关键训练与评估资源。该数据集可直接应用于增强聊天机器人、内容创作助手及娱乐应用的人机交互体验,使模型能够生成更自然、更具吸引力的幽默回应。此外,其构建的评估框架可扩展至其他创意生成任务,如广告文案设计、社交媒体内容优化等,推动人工智能在文化创意产业的落地应用。
衍生相关工作
围绕该数据集衍生的经典研究工作包括 Hessel 等人于 ACL 2023 发表的获奖论文,该研究构建了幽默理解基准,探索模型在标题匹配、质量排序和解释生成等任务上的表现。此外,多项研究利用数据集中的编辑评分数据,分析标题长度、困惑度等特征与幽默效果的相关性。在算法层面,该数据集促进了多臂赌博机算法在众包评分系统中的优化应用,并为在线学习与自适应数据收集系统的开发提供了实践场景。
以上内容由遇见数据集搜集并总结生成


