blythet/deepseek-v4-pro-math-cot-1k
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/blythet/deepseek-v4-pro-math-cot-1k
下载链接
链接失效反馈官方服务:
资源简介:
DeepSeek V4 Pro Math CoT 1K 是一个小型、高质量的监督微调(SFT)数据集,专注于数学推理轨迹。数据集中的问题来自 Nemotron 数学问题集(最初来源于 StackExchange-Math 和 AoPS),由 DeepSeek V4 Pro 在高推理努力下启用思考功能回答,并由 DeepSeek V4 Flash 独立审查其正确性。病态推理轨迹(如循环、长度失控、过多的 `Wait` 式回溯)被隔离。该数据集旨在为小型/中型开放模型(如 Qwen3.5-9B)提供一个干净、紧凑的长篇数学推理微调语料库。数据集设计小巧,每一行都经过更强审查模型的单独检查。
DeepSeek V4 Pro Math CoT 1K is a small, high-signal supervised-fine-tuning (SFT) dataset of math reasoning traces. Problems were sampled from a Nemotron math problem set (originally sourced from StackExchange-Math and AoPS), answered by DeepSeek V4 Pro with thinking enabled at high reasoning effort, then independently reviewed by DeepSeek V4 Flash for correctness against the expected answer. Pathological reasoning traces (looping, run-away length, excessive `Wait`-style backtracking) were quarantined. This dataset is intended as a clean, compact corpus for fine-tuning small/mid-size open models (e.g. Qwen3.5-9B) on long-form mathematical reasoning. It is small by design: every row has been individually inspected by a stronger reviewer model.
提供机构:
blythet
搜集汇总
数据集介绍
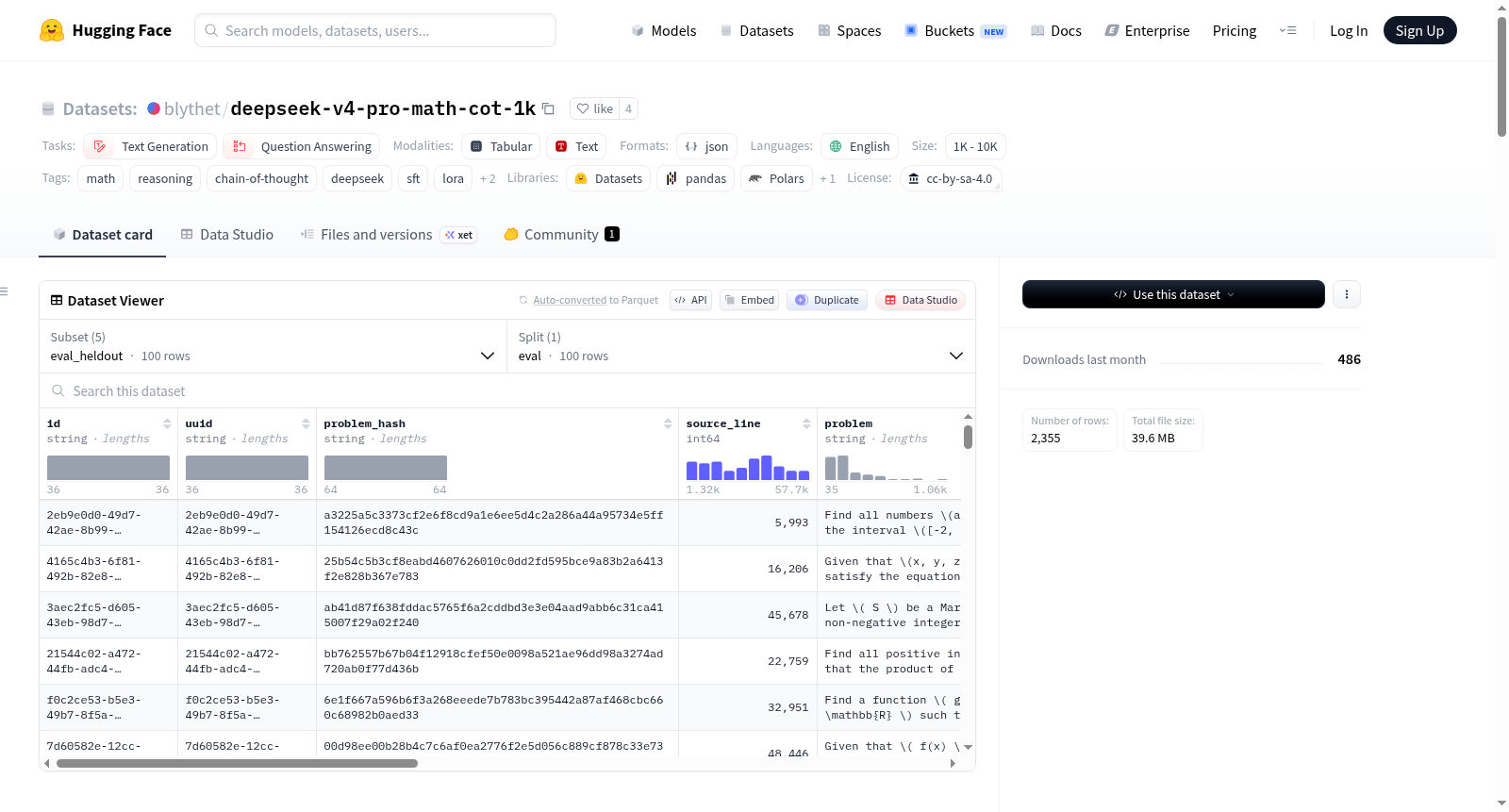
构建方式
该数据集通过一个三阶段流水线构建而成:首先从Nemotron数学问题集中采样题目,这些题目原始来源于StackExchange-Math与AoPS社区;随后调用DeepSeek V4 Pro模型在高推理努力度与思维链开启模式下生成解答轨迹;最后交由DeepSeek V4 Flash模型进行独立审查,核对生成答案与预期答案的一致性。病理性的推理轨迹,如陷入循环、无节制长度或过度使用“Wait”类回溯标记,均被隔离至单独的quarantine分片。整个流程确保了每一行数据都经过了强模型的双重校验与筛选。
特点
本数据集以精炼高信噪比著称,仅包含1008条经审查并过滤后的训练样本,每条记录均蕴含完整的数学问题、自由形式的思维链推理过程、最终答案及上游预期答案。其核心特色在于提供了多个辅助分片:train_metadata记录了每行的来源、许可证及审查判决细节;eval_heldout包含100条互斥的留出问题用于评估;而pathological_quarantine与rejects则分别保存了触发病理阈值和被审查拒绝的轨迹,为研究推理失败模式提供了可溯源的负面样本池。
使用方法
数据集专为小型至中型开源模型(如Qwen3.5-9B)的数学推理微调而设计,支持LoRA或全参数SFT范式。使用时需注意,训练目标应为reasoning字段后接answer字段,切勿将expected_answer引入训练提示。对于采用自动注入思考片段的聊天模板,建议将reasoning包裹在<think>标记内再与answer拼接,或绕过模板直接训练。此外,eval_heldout可提供独立的评估信号,而病理与拒绝分片则可用于分析长思维链中的常见陷阱与质量边界。
背景与挑战
背景概述
近年来,大规模语言模型在数学推理任务中展现出巨大潜力,然而高质量、经过验证的思维链(Chain-of-Thought)训练数据仍然稀缺。在此背景下,DeepSeek团队于2024年构建了DeepSeek V4 Pro Math CoT 1K数据集,旨在为小型及中型开源模型(如Qwen3.5-9B)提供干净、高信号的有监督微调(SFT)语料。该数据集从Nemotron数学问题集中采样,涵盖StackExchange-Math和AoPS两大来源,由DeepSeek V4 Pro以高推理努力生成推理轨迹,并通过DeepSeek V4 Flash进行独立审查与过滤,确保每条数据均经过严格质量控制。作为数学推理领域的精细化资源,该数据集推动了长链推理能力在有限参数量模型上的迁移与提升。
当前挑战
该数据集所解决的领域问题在于,当前数学推理数据集常混杂冗长、循环或逻辑断裂的病理推理轨迹,严重制约模型对正确推理模式的学习效果。为此,构建过程面临多重挑战:首先,需要从海量生成结果中区分高质量与低质量推理,通过设定推理token数(≤50,000)、Wait标志计数(<50)、循环标记总数(<75)及生成延迟(<1,200秒)等阈值进行病理隔离,但阈值选择需平衡召回与精度。其次,单一生成模型(DeepSeek V4 Pro)引入的风格偏差可能限制模型的泛化性,需要审查模型(V4 Flash)进行逐条校验并处理可能存在的答案一致但推理存疑的边界案例。此外,约5%的样本推理内容超过21,000 token,对微调时的上下文窗口提出更高要求。
常用场景
经典使用场景
在数学推理领域,尤其是面向中小规模开源语言模型(如Qwen3.5-9B)的监督微调(SFT)与低秩适配(LoRA)任务中,DeepSeek V4 Pro Math CoT 1K数据集扮演着精炼语料库的角色。该数据集精选了来自StackExchange-Math与AoPS的高质量数学问题,并由DeepSeek V4 Pro生成详尽的链式思维(Chain-of-Thought)推理轨迹,再经过DeepSeek V4 Flash的独立审查与病理性剔除,确保每条样本均具备高信噪比。研究者可借助这个紧凑而干净的语料,对模型进行长形式数学推理能力的定向强化,尤其适合在资源有限条件下探索推理能力的涌现机制。
衍生相关工作
该数据集的诞生催生了多个方向的相关研究。其一,围绕病态推理轨迹的定量分析,研究人员可利用其标注好的quarantine和rejects样本,建立预测推理质量自动评估模型或早停策略,从而提升长链推理系统的鲁棒性。其二,基于其高信噪比的traincore子集,学术界涌现出关于“知识蒸馏”与“跨模型推理迁移”的探索,即探究从DeepSeek V4 Pro这类强模型生成的推理轨迹中蒸馏推理能力到小模型上的最佳实践。其三,该数据集的元数据结构(如per-row许可证、工具使用标记等)启发了一系列关于负责任AI的数据溯源研究,推动了数据集治理与合规性讨论的深入。
数据集最近研究
最新研究方向
该数据集聚焦于利用高推理强度的思维链技术优化数学推理的微调流程,尤其关注长链推理中病理模式的识别与隔离策略。当前前沿方向围绕构建高信号、低噪声的数学推理训练语料,通过强评审模型对生成轨迹进行质量筛选,剔除循环、过长的递归回溯等有害路径。这一方法呼应了大语言模型在复杂数学推理中可解释性与鲁棒性的追求,为小规模开放模型在资源受限场景下实现高质量推理能力迁移提供了经过严格校验的数据基石。
以上内容由遇见数据集搜集并总结生成


