allenai/common_gen
收藏Hugging Face2024-01-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/allenai/common_gen
下载链接
链接失效反馈资源简介:
---
annotations_creators:
- crowdsourced
language_creators:
- found
- crowdsourced
language:
- en
license:
- mit
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text2text-generation
task_ids: []
paperswithcode_id: commongen
pretty_name: CommonGen
tags:
- concepts-to-text
dataset_info:
features:
- name: concept_set_idx
dtype: int32
- name: concepts
sequence: string
- name: target
dtype: string
splits:
- name: train
num_bytes: 6724166
num_examples: 67389
- name: validation
num_bytes: 408740
num_examples: 4018
- name: test
num_bytes: 77518
num_examples: 1497
download_size: 3434865
dataset_size: 7210424
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
# Dataset Card for "common_gen"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://inklab.usc.edu/CommonGen/index.html](https://inklab.usc.edu/CommonGen/index.html)
- **Repository:** https://github.com/INK-USC/CommonGen
- **Paper:** [CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning](https://arxiv.org/abs/1911.03705)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 1.85 MB
- **Size of the generated dataset:** 7.21 MB
- **Total amount of disk used:** 9.06 MB
### Dataset Summary
CommonGen is a constrained text generation task, associated with a benchmark dataset,
to explicitly test machines for the ability of generative commonsense reasoning. Given
a set of common concepts; the task is to generate a coherent sentence describing an
everyday scenario using these concepts.
CommonGen is challenging because it inherently requires 1) relational reasoning using
background commonsense knowledge, and 2) compositional generalization ability to work
on unseen concept combinations. Our dataset, constructed through a combination of
crowd-sourcing from AMT and existing caption corpora, consists of 30k concept-sets and
50k sentences in total.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### default
- **Size of downloaded dataset files:** 1.85 MB
- **Size of the generated dataset:** 7.21 MB
- **Total amount of disk used:** 9.06 MB
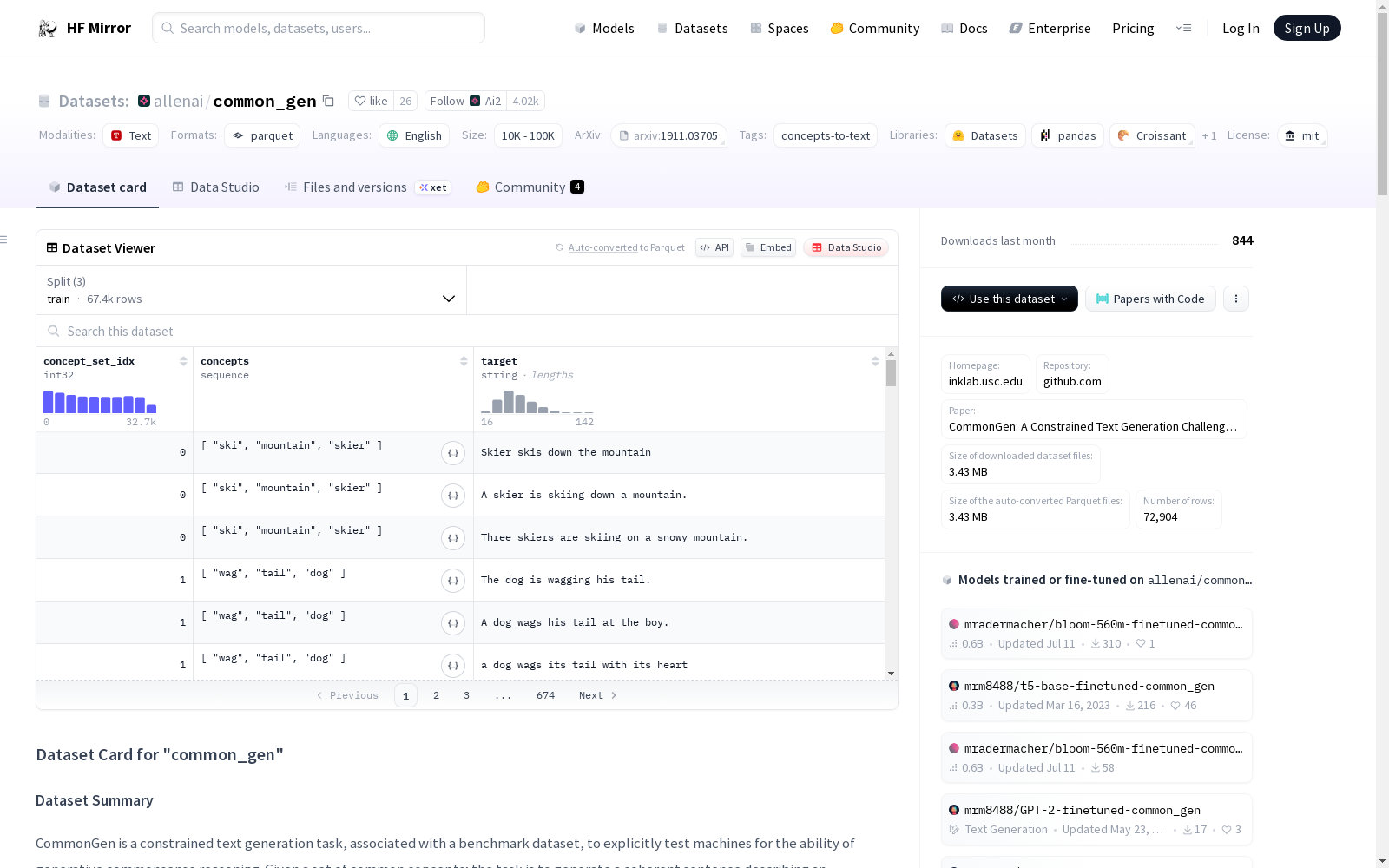
An example of 'train' looks as follows.
```
{
"concept_set_idx": 0,
"concepts": ["ski", "mountain", "skier"],
"target": "Three skiers are skiing on a snowy mountain."
}
```
### Data Fields
The data fields are the same among all splits.
#### default
- `concept_set_idx`: a `int32` feature.
- `concepts`: a `list` of `string` features.
- `target`: a `string` feature.
### Data Splits
| name |train|validation|test|
|-------|----:|---------:|---:|
|default|67389| 4018|1497|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
The dataset is licensed under [MIT License](https://github.com/INK-USC/CommonGen/blob/master/LICENSE).
### Citation Information
```bib
@inproceedings{lin-etal-2020-commongen,
title = "{C}ommon{G}en: A Constrained Text Generation Challenge for Generative Commonsense Reasoning",
author = "Lin, Bill Yuchen and
Zhou, Wangchunshu and
Shen, Ming and
Zhou, Pei and
Bhagavatula, Chandra and
Choi, Yejin and
Ren, Xiang",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.165",
doi = "10.18653/v1/2020.findings-emnlp.165",
pages = "1823--1840"
}
```
### Contributions
Thanks to [@JetRunner](https://github.com/JetRunner), [@yuchenlin](https://github.com/yuchenlin), [@thomwolf](https://github.com/thomwolf), [@lhoestq](https://github.com/lhoestq) for adding this dataset.
annotations_creators:
- 众包
language_creators:
- 公开获取
- 众包
language:
- 英语(en)
license:
- MIT许可证(MIT License)
multilinguality:
- 单语言
size_categories:
- 10000 < 样本量 < 100000
source_datasets:
- 原创数据集
task_categories:
- 文本到文本生成(text2text-generation)
task_ids: []
paperswithcode_id: commongen
pretty_name: CommonGen
tags:
- 概念到文本生成(concepts-to-text)
dataset_info:
features:
- name: 概念集索引
dtype: int32
- name: 概念列表
sequence: 字符串
- name: 目标文本
dtype: 字符串
splits:
- name: 训练集
num_bytes: 6724166
num_examples: 67389
- name: 验证集
num_bytes: 408740
num_examples: 4018
- name: 测试集
num_bytes: 77518
num_examples: 1497
download_size: 3434865
dataset_size: 7210424
configs:
- config_name: 默认配置
data_files:
- split: 训练集
path: data/train-*
- split: 验证集
path: data/validation-*
- split: 测试集
path: data/test-*
# 「common_gen」数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集概述](#dataset-summary)
- [支持任务与基准榜单](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建逻辑](#curation-rationale)
- [源数据](#source-data)
- [标注](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集策展人](#dataset-curators)
- [许可证信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献致谢](#contributions)
## 数据集描述
- **主页:** [https://inklab.usc.edu/CommonGen/index.html](https://inklab.usc.edu/CommonGen/index.html)
- **代码仓库:** https://github.com/INK-USC/CommonGen
- **相关论文:** [CommonGen:面向生成式常识推理的约束文本生成挑战(CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning)](https://arxiv.org/abs/1911.03705)
- **联络方式:** [需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **下载数据集文件大小:** 1.85 MB
- **生成后数据集大小:** 7.21 MB
- **总磁盘占用空间:** 9.06 MB
### 数据集概述
CommonGen是一项约束文本生成任务,配套有基准数据集,旨在专门测试机器的**生成式常识推理(Generative Commonsense Reasoning)**能力。给定一组日常概念,任务目标为利用这些概念生成一段描述日常场景的连贯语句。
该任务具有一定挑战性,因为其本质上需要两点能力:一是基于背景常识知识的关系推理能力,二是针对未见概念组合的组合泛化能力。本数据集结合了亚马逊机械 Turk(AMT,Amazon Mechanical Turk)众包数据与现有图像字幕语料库构建而成,总计包含3万个概念集与5万条语句。
### 支持任务与基准榜单
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 语言
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集结构
### 数据实例
#### 默认配置
- **下载数据集文件大小:** 1.85 MB
- **生成后数据集大小:** 7.21 MB
- **总磁盘占用空间:** 9.06 MB
训练集的一个示例如下:
{
"概念集索引": 0,
"概念列表": ["滑雪", "山地", "滑雪者"],
"目标文本": "三名滑雪者正在积雪的山地滑雪。"
}
### 数据字段
所有划分的数据字段均保持一致。
#### 默认配置
- `概念集索引`:类型为`int32`的特征。
- `概念列表`:字符串类型的列表特征。
- `目标文本`:字符串类型的特征。
### 数据划分
| 划分名称 | 训练集 | 验证集 | 测试集 |
|---------|-------:|-------:|-------:|
| 默认配置 | 67389 | 4018 | 1497 |
## 数据集构建
### 构建逻辑
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 源数据
#### 初始数据收集与标准化
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 源语言生产者是谁?
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 标注
#### 标注流程
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 标注人员是谁?
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 个人与敏感信息
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集使用注意事项
### 数据集的社会影响
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 偏差讨论
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 其他已知局限性
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 附加信息
### 数据集策展人
[需补充更多信息](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 许可证信息
本数据集采用[MIT许可证(MIT License)](https://github.com/INK-USC/CommonGen/blob/master/LICENSE)进行授权。
### 引用信息
bib
@inproceedings{lin-etal-2020-commongen,
title = "{C}ommon{G}en: A Constrained Text Generation Challenge for Generative Commonsense Reasoning",
author = "Lin, Bill Yuchen and
Zhou, Wangchunshu and
Shen, Ming and
Zhou, Pei and
Bhagavatula, Chandra and
Choi, Yejin and
Ren, Xiang",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.165",
doi = "10.18653/v1/2020.findings-emnlp.165",
pages = "1823--1840"
}
### 贡献致谢
感谢 [@JetRunner](https://github.com/JetRunner)、[@yuchenlin](https://github.com/yuchenlin)、[@thomwolf](https://github.com/thomwolf)、[@lhoestq](https://github.com/lhoestq) 为本数据集的收录提供支持。
提供机构:
allenai
原始信息汇总
数据集概述
数据集名称
- 名称: CommonGen
- 别名: commongen
数据集属性
- 语言: 英语 (en)
- 许可证: MIT
- 多语言性: 单语
- 大小: 10K<n<100K
- 源数据集: 原始
- 任务类别: 文本到文本生成 (text2text-generation)
- 标签: 概念到文本 (concepts-to-text)
数据集结构
- 特征:
concept_set_idx: int32类型concepts: 字符串序列target: 字符串类型
- 分割:
- 训练集: 67389个样本,6724166字节
- 验证集: 4018个样本,408740字节
- 测试集: 1497个样本,77518字节
- 下载大小: 3434865字节
- 数据集大小: 7210424字节
数据集创建
- 语言创建者: 发现和众包
- 注释创建者: 众包
- 数据集信息:
- 构建方式: 通过结合AMT众包和现有标题语料库构建,包含30k概念集和50k句子。
使用考虑
- 许可证信息: 数据集根据MIT许可证授权。
- 引用信息: bib @inproceedings{lin-etal-2020-commongen, title = "{C}ommon{G}en: A Constrained Text Generation Challenge for Generative Commonsense Reasoning", author = "Lin, Bill Yuchen and Zhou, Wangchunshu and Shen, Ming and Zhou, Pei and Bhagavatula, Chandra and Choi, Yejin and Ren, Xiang", booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020", month = nov, year = "2020", address = "Online", publisher = "Association for Computational Linguistics", url = "https://www.aclweb.org/anthology/2020.findings-emnlp.165", doi = "10.18653/v1/2020.findings-emnlp.165", pages = "1823--1840" }
搜集汇总
数据集介绍
构建方式
CommonGen数据集的构建采用了一种结合众包方法和现有标题语料库的策略,旨在创建一个包含30k概念集和50k句子的文本生成任务数据集。该数据集通过精心设计的众包流程,从亚马逊土耳其机器人(AMT)获取,并辅以现有的标题语料库,确保了数据的多样性和覆盖面,以满足生成常识推理的测试需求。
特点
CommonGen数据集的特点在于其创新性地提出了一个受限文本生成任务,专注于测试机器在生成常识推理方面的能力。数据集包含了多个日常场景的概念组合,要求生成描述这些概念的连贯句子,这不仅需要关系推理和背景常识知识,还要求具备组合泛化能力,以处理未见过的概念组合。
使用方法
使用CommonGen数据集时,用户可以访问其提供的三个数据分割:训练集、验证集和测试集。每个数据实例都包括一个概念集索引、一组概念和一个目标句子。用户需根据提供 concepts 生成符合目标(target)的句子,以此训练和评估文本生成模型在常识推理任务上的性能。
背景与挑战
背景概述
CommonGen数据集,由美国南加州大学的研究团队于2020年创建,旨在通过文本生成任务来测试机器的生成常识推理能力。该数据集包含30,000个概念集和50,000个句子,通过众包的方式从Amazon Mechanical Turk及现有字幕语料库构建而成。CommonGen的核心研究问题是如何让机器在给定的概念集合下生成描述日常情景的连贯句子,这对机器的背景常识知识和组合泛化能力提出了挑战。CommonGen数据集的创建对自然语言处理领域,尤其是在文本生成和常识推理方面产生了显著影响。
当前挑战
CommonGen数据集面临的挑战主要在于两个方面:一是如何有效地进行关系推理,运用背景常识知识生成合理句子;二是如何处理未见过概念组合的生成任务,即组合泛化能力。构建过程中的挑战包括众包数据的质量控制、概念与句子之间的匹配度确保,以及数据标注的一致性和准确性。此外,数据集可能存在的偏差和局限性也是使用时需要考虑的问题。
常用场景
经典使用场景
在自然语言处理领域,CommonGen数据集的经典使用场景是作为文本生成任务的基准,它要求模型根据给定的一组常见概念生成一个描述日常情景的连贯句子。这种能力对于测试机器在生成常识推理方面的性能至关重要。
解决学术问题
CommonGen数据集解决了在文本生成任务中,如何有效评估模型对背景常识知识的运用和组合泛化能力的问题。它为研究者提供了一个标准化的测试平台,有助于推动生成性常识推理技术的发展。
衍生相关工作
基于CommonGen数据集,研究者们衍生出了一系列相关工作,如进一步探索生成性常识推理的算法、构建更加复杂的概念组合生成任务,以及针对特定领域常识的文本生成研究。
以上内容由遇见数据集搜集并总结生成


