UKPLab/TexPrax
收藏Hugging Face2023-01-11 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/UKPLab/TexPrax
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-4.0
---
# Dataset Card for TexPrax
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage: https://texprax.de/**
- **Repository: https://github.com/UKPLab/TexPrax**
- **Paper: https://arxiv.org/abs/2208.07846**
- **Leaderboard: n/a**
- **Point of Contact: Ji-Ung Lee (http://www.ukp.tu-darmstadt.de/)**
### Dataset Summary
This dataset contains dialogues collected from German factory workers at the _Center for industrial productivity_ ([CiP](https://www.prozesslernfabrik.de/)). The dialogues mostly concern issues workers encounter during their daily work, such as machines breaking down, material missing, etc. The dialogues are further expert-annotated on a sentence level (problem, cause, solution, other) for sentence classification and on a token level for named entity recognition using a BIO tagging scheme. Note, that the dataset was collected in three rounds, each around one year apart. Here, we provide the data only split into train and test data where the test data was collected at the last round (July 2022). Additionally, the data from the first round is split into two subdomains, industry 4.0 (industrie) and machining (zerspanung). The splits were made according to the respective groups of people working at different assembly lines in the factory.
### Supported Tasks and Leaderboards
This dataset supports the following tasks:
* Sentence classification
* Named entity recognition (will be updated soon with the new indexing)
* Dialog generation (so far not evaluated)
### Languages
German
## Dataset Structure
### Data Instances
On sentence level, each instance consists of the dialog-id, turn-id, sentence-id, the sentence (raw), the label, the domain, and the subsplit.
```
{"185";"562";993";"wie kriege ich die Dichtung raus?";"P";"n/a";"3"}
```
On token level, each instance consists of a unique identifier, a list of tokens containing the whole dialog, the list of labels (bio-tagged entities), and the subsplit.
```
{"178_0";"['Hi', 'wie', 'kriege', 'ich', 'die', 'Dichtung', 'raus', '?', 'in', 'der', 'Schublade', 'gibt', 'es', 'einen', 'Dichtungszieher']";"['O', 'O', 'O', 'O', 'O', 'B-PRE', 'O', 'O', 'O', 'O', 'B-LOC', 'O', 'O', 'O', 'B-PE']";"Batch 3"}
```
### Data Fields
Sentence level:
* dialog-id: unique identifier for the dialog
* turn-id: unique identifier for the turn
* sentence-id: unique identifier for the dialog
* sentence: the respective sentence
* label: the label (_P_ for Problem, _C_ for Cause, _S_ for solution, and _O_ for Other)
* domain: the subdomains where the data was collected from. Domains are industry, machining, or n/a (for batch 2 and batch 3).
* subsplit: the respective subsplit of the data (see below)
Token level:
* id: the identifier
* tokens: a list of tokens (i.e., the tokenized dialogue)
* entities: the named entity in a BIO scheme (_B-X_, _I-X_, or O).
* subsplit: the respective subsplit of the data (see below)
### Data Splits
The dataset is split into train and test splits, but contains further subsplits (subsplit column). Note, that the splits are collected at different times with some turnaround in the workforce. Hence, later data (especially the data from batch 2) contains more turns (due to increased search for a cause) as more inexperienced workers who newly joined were employed in the factory.
Train:
* Batch 1 industrie: data collected in October 2020 from workers in the industry 4.0 assembly line
* Batch 1 zerspanung: data collected in October 2020 from workers in the machining assembly line
* Batch 2: data collected in-between October 2021-June 2022 from all workers
Test:
* Batch 3: data collected in July 2022 together with the system usability study run
Sentence level statistics:
| Batch | Dialogues | Turns | Sentences |
|---|---|---|---|
| 1 | 81 | 246 | 553 |
| 2 | 97 | 309 | 432 |
| 3 | 24 | 36 | 42 |
| Overall | 202 | 591 | 1,027 |
Token level statistics:
[Needs to be added]
## Dataset Creation
### Curation Rationale
This dataset provides task-oriented dialogues that solve a very domain specific problem.
### Source Data
#### Initial Data Collection and Normalization
The data was generated by workers at the [CiP](https://www.prozesslernfabrik.de/). The data was collected in three rounds (October 2020, October 2021-June 2022, July 2022). As the dialogues occurred during their daily work, one distinct property of the dataset is that all dialogues are very informal 'ne', contain abbreviations 'vll', and filler words such as 'ah'. For a detailed description please see the [paper](https://arxiv.org/abs/2208.07846).
#### Who are the source language producers?
German factory workers working at the [CiP](https://www.prozesslernfabrik.de/)
### Annotations
#### Annotation process
**Token level.** Token level annotation was done by researchers who are responsible for supervising and teaching workers at the CiP. The data was first split into three parts, each annotated by one researcher. Next, each researcher cross-examined the other researchers' annotations. If there were disagreements, all three researchers discussed the final label.
**Sentence level.** Sentence level annotations were collected from the factory workers who also generated the dialogues. For details about the data collection, please see the [TexPrax demo paper](https://arxiv.org/abs/2208.07846).
#### Who are the annotators?
**Token level.** Researchers working at the CiP.
**Sentence level.** The factory workers themselves.
### Personal and Sensitive Information
This dataset is fully anonymized. All occurrences of names have been manually checked during annotation and replaced with a random token.
## Considerations for Using the Data
### Social Impact of Dataset
Informal language especially used in short messages, however, seldom considered in existing NLP datasets. This dataset could serve as an interesting evaluation task for transferring language models to low-resource, but highly specific domains. Moreover, we note that despite all abbreviations, typos, and local dialects used in the messages, all workers were able to understand the questions as well as replies. This should be a standard future NLP models should be able to uphold.
### Discussion of Biases
The dialogues are very much on a professional level. The workers were informed (and gave their consent) in advance that their messages are being recorded and processed, which may have influenced them to hold only professional conversations, hence, all dialogues concern inanimate objects (i.e., machines).
### Other Known Limitations
[More Information Needed]
## Additional Information
You can download the data via:
```
from datasets import load_dataset
dataset = load_dataset("UKPLab/TexPrax") # default config is sentence classification
dataset = load_dataset("UKPLab/TexPrax", "ner") # use the ner tag for named entity recognition
```
Please find more information about the code and how the data was collected on [GitHub](https://github.com/UKPLab/TexPrax).
### Dataset Curators
Curation is managed by our [data manager](https://www.informatik.tu-darmstadt.de/ukp/research_ukp/ukp_research_data_and_software/ukp_data_and_software.en.jsp) at UKP.
### Licensing Information
[CC-by-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/)
### Citation Information
Please cite this data using:
```
@article{stangier2022texprax,
title={TexPrax: A Messaging Application for Ethical, Real-time Data Collection and Annotation},
author={Stangier, Lorenz and Lee, Ji-Ung and Wang, Yuxi and M{\"u}ller, Marvin and Frick, Nicholas and Metternich, Joachim and Gurevych, Iryna},
journal={arXiv preprint arXiv:2208.07846},
year={2022}
}
```
### Contributions
Thanks to [@Wuhn](https://github.com/Wuhn) for adding this dataset.
## Tags
annotations_creators:
- expert-generated
language:
- de
language_creators:
- expert-generated
license:
- cc-by-nc-4.0
multilinguality:
- monolingual
pretty_name: TexPrax-Conversations
size_categories:
- n<1K
- 1K<n<10K
source_datasets:
- original
tags:
- dialog
- expert to expert conversations
- task-oriented
task_categories:
- token-classification
- text-classification
task_ids:
- named-entity-recognition
- multi-class-classification
提供机构:
UKPLab
原始信息汇总
数据集概述
数据集名称
TexPrax
数据集描述
TexPrax数据集包含从德国工厂工人收集的对话,主要涉及日常工作中遇到的问题,如机器故障、材料缺失等。对话经过专家在句子级别(问题、原因、解决方案、其他)进行标注,以及在令牌级别使用BIO标记方案进行命名实体识别。
支持的任务
- 句子分类
- 命名实体识别
- 对话生成(尚未评估)
语言
德语
数据集结构
数据实例
- 句子级别:每个实例包括对话ID、轮次ID、句子ID、句子内容、标签、领域和子分割。
- 令牌级别:每个实例包括唯一标识符、令牌列表、标签列表(BIO标记实体)和子分割。
数据字段
- 句子级别:对话ID、轮次ID、句子ID、句子、标签、领域、子分割。
- 令牌级别:标识符、令牌列表、实体、子分割。
数据分割
数据集分为训练和测试集,包含进一步的子分割。训练数据来自2020年10月和2021年10月至2022年6月,测试数据来自2022年7月。
数据集创建
来源数据
数据由CiP的工厂工人产生,分三轮收集。
标注过程
- 令牌级别:由CiP的研究人员进行,经过交叉检查和讨论确定最终标签。
- 句子级别:由工厂工人进行。
个人和敏感信息
数据集已完全匿名化,所有名称已被替换为随机令牌。
使用数据的考虑
社会影响
该数据集可用于评估语言模型在低资源但高度特定领域的转移能力。
偏见讨论
对话主要涉及专业层面,可能受限于仅讨论机器等非生物对象。
其他已知限制
[需要更多信息]
附加信息
数据集可通过datasets库加载,详细信息请参阅GitHub仓库。
许可证
CC-by-NC 4.0
引用信息
@article{stangier2022texprax, title={TexPrax: A Messaging Application for Ethical, Real-time Data Collection and Annotation}, author={Stangier, Lorenz and Lee, Ji-Ung and Wang, Yuxi and M{"u}ller, Marvin and Frick, Nicholas and Metternich, Joachim and Gurevych, Iryna}, journal={arXiv preprint arXiv:2208.07846}, year={2022} }
搜集汇总
数据集介绍
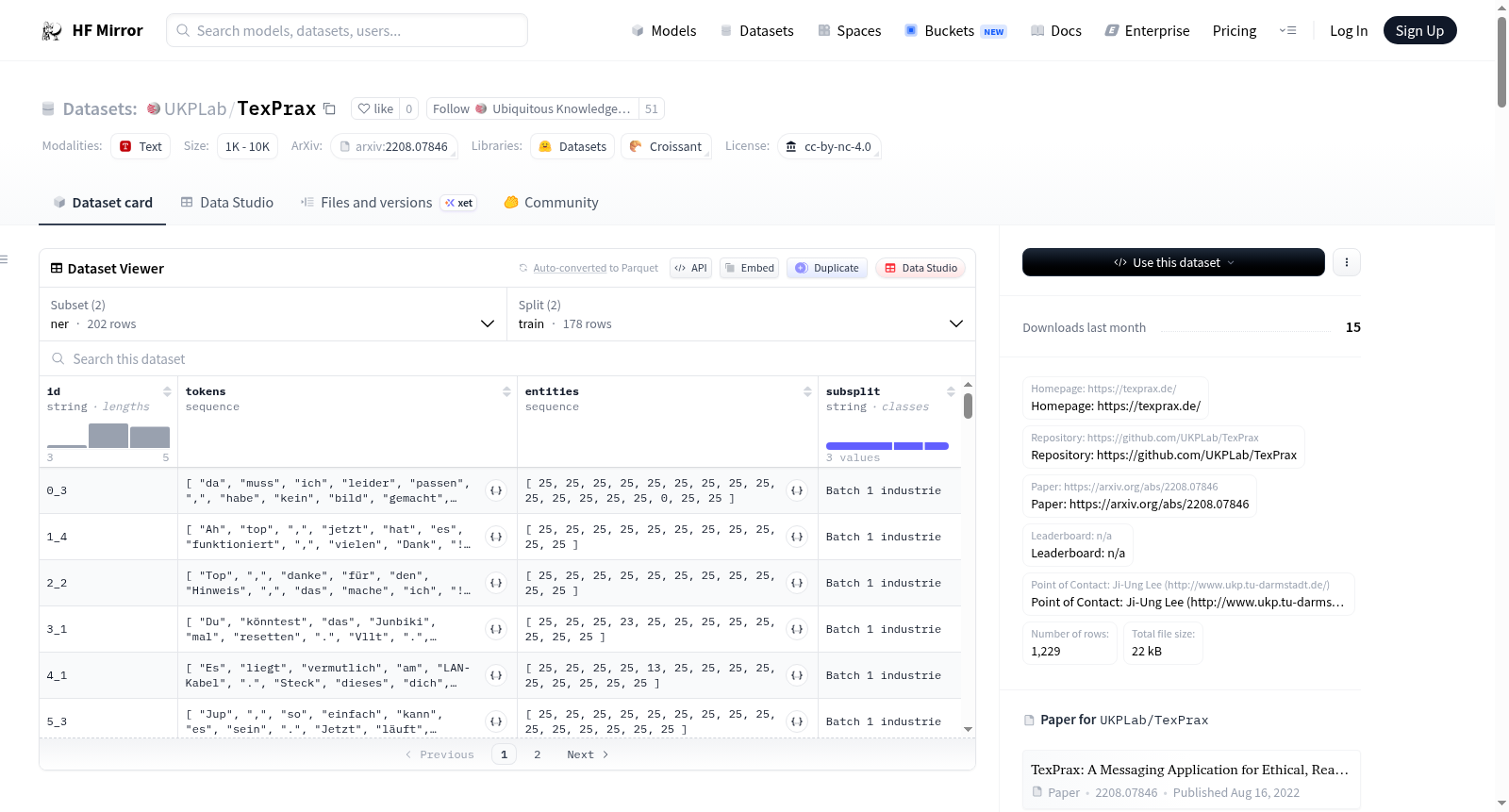
构建方式
在工业生产力中心的实际生产环境中,TexPrax数据集通过精心设计的消息应用,系统性地采集了德国工厂工人在日常工作中遇到设备故障、物料缺失等问题时的对话记录。数据收集过程分为三个批次,分别于2020年10月、2021年10月至2022年6月以及2022年7月进行,确保了时间跨度和场景多样性。句子级标注由工人自身完成,涵盖问题、原因、解决方案等类别;词元级命名实体识别则由研究中心的研究人员采用交叉验证方式标注,保证了标注的一致性与可靠性。
特点
TexPrax数据集展现了工业领域对话的独特语言特征,其文本包含大量非正式表达、缩写词及填充词,真实反映了工厂环境中的口语化交流模式。数据集结构上,除了常规的训练与测试划分,还依据产线领域(工业4.0与机械加工)及收集批次细分子集,为领域适应性与时序演变研究提供了丰富维度。标注层面兼具句子分类与命名实体识别双重任务,且所有对话均经过匿名化处理,兼顾了数据实用性与隐私保护。
使用方法
研究者可通过Hugging Face的datasets库便捷加载TexPrax数据集,默认配置支持句子分类任务,指定'ner'参数则可切换至命名实体识别任务。数据以结构化JSON格式提供,包含对话标识、语句内容、标注标签及领域信息等字段。该数据集适用于低资源领域语言模型迁移、任务导向对话系统开发等研究方向,其多批次、多领域的划分方式也为模型鲁棒性与泛化能力评估提供了天然实验框架。
背景与挑战
背景概述
在工业智能与自然语言处理交叉领域,专业领域对话数据的稀缺性长期制约着任务导向型对话系统的发展。由德国达姆施塔特工业大学Ubiquitous Knowledge Processing Lab(UKP Lab)主导构建的TexPrax数据集,于2022年正式发布,其核心研究聚焦于工业制造场景下的实际问题解决对话。该数据集采集自德国工业生产力中心(CiP)一线工人的真实工作交流,旨在为低资源、高专业性的德语工业领域,提供兼具句子级分类与命名实体识别标注的对话语料,以推动领域自适应语言模型与专业对话系统的研究。
当前挑战
TexPrax数据集旨在应对工业领域任务导向对话理解的核心挑战,即如何精准识别非正式、富含专业术语与口语化表达的对话中隐含的问题、原因与解决方案等语义结构。在构建过程中,研究团队面临多重现实困难:其一,数据采集需在真实工厂环境中进行,需平衡伦理合规性与数据自然性,工人知情可能影响对话的随意性;其二,标注工作极具专业性,需由熟悉生产流程的研究者与生成对话的工人共同完成,跨角色标注的一致性与质量保障构成显著挑战;其三,数据随时间分批次收集,期间工厂人员流动导致对话模式与经验水平发生变化,为模型在动态环境下的泛化能力评估带来复杂性。
常用场景
经典使用场景
在工业制造领域,TexPrax数据集为任务导向型对话系统研究提供了珍贵资源。该数据集源自德国工厂工人的实际工作交流,聚焦于设备故障、物料缺失等日常问题,其句子级分类与命名实体识别标注为模型训练奠定了坚实基础。研究者可借此探索工业场景下自然语言处理的独特挑战,如非正式表达、专业术语及方言混杂现象,从而推动领域自适应方法的发展。
解决学术问题
TexPrax有效解决了低资源领域自然语言处理模型的迁移与适应问题。该数据集填补了工业制造场景中非正式专业对话语料的空白,为研究领域特定语言现象提供了实证基础。其多层次标注机制支持句子分类与命名实体识别任务的联合优化,有助于突破传统模型在专业术语理解、缩写解析等方面的局限,为跨领域语言理解研究开辟了新路径。
衍生相关工作
TexPrax催生了多项聚焦工业对话理解的前沿研究。相关成果包括基于领域自适应的预训练语言模型优化方法、多任务学习框架下的问题分类与实体抽取联合模型,以及面向非规范文本的鲁棒性对话系统设计。这些工作进一步拓展至跨语言工业知识迁移、低资源场景增量学习等方向,形成了制造领域自然语言处理的技术生态。
以上内容由遇见数据集搜集并总结生成


