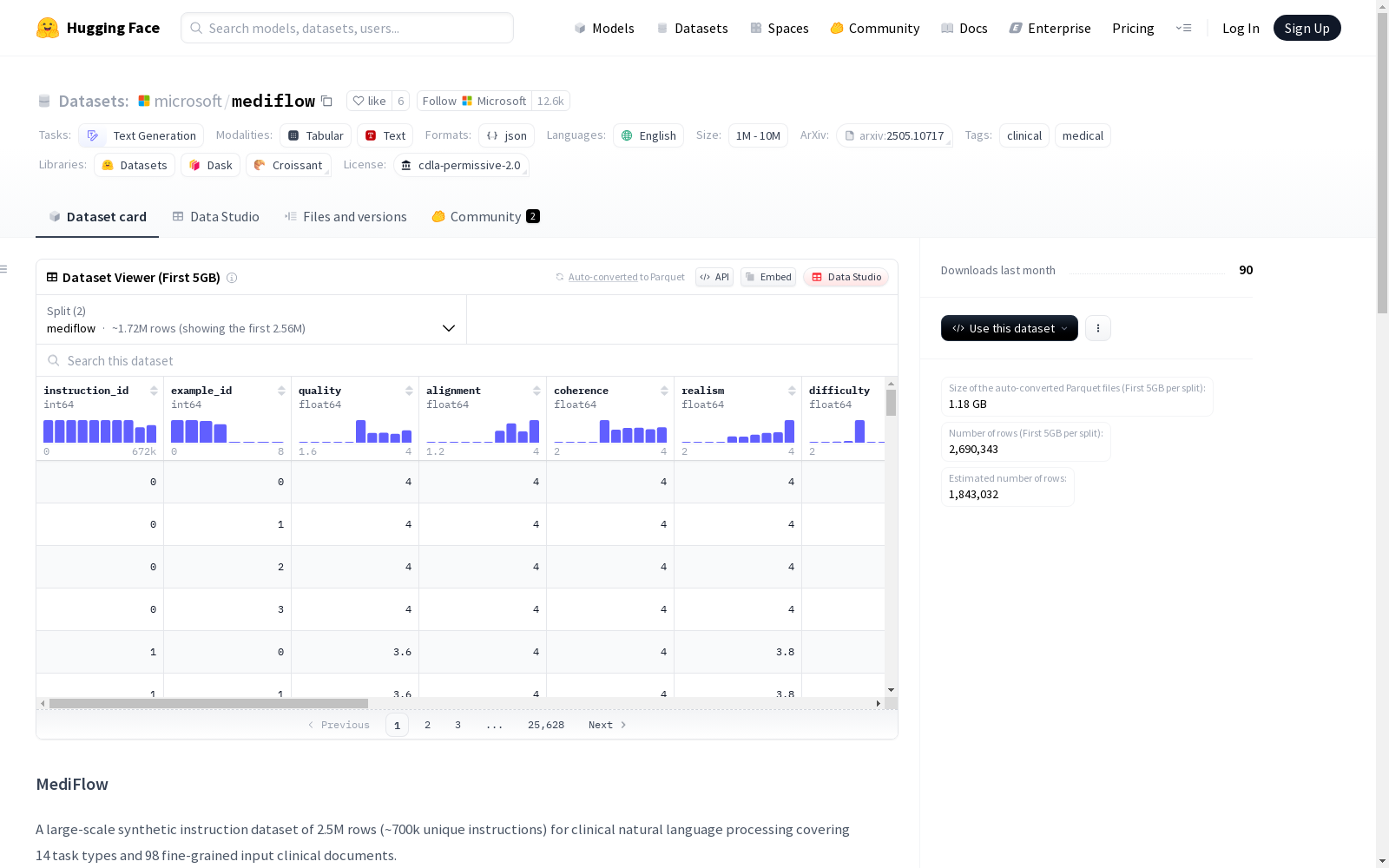
mediflow
收藏Hugging Face2025-05-30 更新2025-05-31 收录
下载链接:
https://huggingface.co/datasets/microsoft/mediflow
下载链接
链接失效反馈官方服务:
资源简介:
MediFlow是一个包含约2.5M条记录(约70万独特指令)的大规模合成指令数据集,用于临床自然语言处理。它涵盖了14种不同的任务类型和98种细粒度的临床文档输入。该数据集提供了指令、输入示例、输出示例、任务类型、输入数据类型、输出格式和难度级别等信息,并附有LLM-as-a-Judge评分,包括质量、对齐、连贯性、真实性和难度等。
提供机构:
Microsoft
创建时间:
2025-05-27
原始信息汇总
MediFlow数据集概述
基本信息
- 许可证: CDLA-Permissive-2.0
- 任务类别: 文本生成
- 语言: 英语
- 标签: 临床、医学
- 数据规模: 1M<n<10M
数据集描述
- 规模: 包含250万行数据(约70万条唯一指令)
- 覆盖范围: 临床自然语言处理,涵盖14种任务类型和98种细粒度输入临床文档
数据集划分
mediflow: 250万条指令数据,用于SFT对齐mediflow_dpo: 约13.5万条高质量指令,包含GPT-4o生成的rejected_output,用于DPO对齐
主要列字段
instruction: 任务指令input: 应用任务的输入示例output: 应用指令后期望的输出示例task_type: 14种自然语言处理相关任务类型之一input_data: 输入数据类型output_format: 输出格式(plain_text或json)difficulty_level: 六个难度级别之一,重点关注前三个最难级别rejected_output: 用于DPO的错误输出(仅mediflow_dpo)error_type: 在output中引入的错误类型以获取rejected_output(仅mediflow_dpo)
评估指标
包含LLM-as-a-Judge评分:
qualityalignmentcoherencerealismdifficulty
相关论文
引用格式
bibtex @article{corbeil2025modular, title={A Modular Approach for Clinical SLMs Driven by Synthetic Data with Pre-Instruction Tuning, Model Merging, and Clinical-Tasks Alignment}, author={Corbeil, Jean-Philippe and Dada, Amin and Attendu, Jean-Michel and Abacha, Asma Ben and Sordoni, Alessandro and Caccia, Lucas and Beaulieu, Fran{c{c}}ois and Lin, Thomas and Kleesiek, Jens and Vozila, Paul}, journal={arXiv preprint arXiv:2505.10717}, year={2025} }
搜集汇总
数据集介绍
构建方式
在临床自然语言处理领域,MediFlow数据集通过精心设计的合成方法构建而成,涵盖了14种任务类型和98种细粒度临床文档输入。该数据集包含250万条指令数据(约70万条独特指令),采用模块化生成策略,特别强调难度最高的三个层级。数据生成过程结合了GPT-4o模型的质量控制,为DPO对齐专门构建了包含13.5万条高质量指令的子集,每条都标注了错误类型和被拒绝的输出范例。
特点
作为临床文本处理领域的专业数据集,MediFlow以其规模宏大和任务多样性著称。该数据集不仅包含基础的指令-输入-输出三元组,还细化了任务类型、输入数据类型、输出格式等维度特征。特别值得注意的是,数据集引入了LLM-as-a-Judge评分体系,从质量、对齐度、连贯性、真实性和难度五个维度对数据进行了专业评估。通过t-SNE可视化可以清晰观察到不同任务类型在嵌入空间的聚类分布,印证了数据集的结构化设计理念。
使用方法
MediFlow数据集为临床语言模型开发提供了完整的训练框架。基础数据集mediflow适用于监督微调(SFT),而mediflow_dpo子集则专门用于直接偏好优化(DPO)训练。使用者可根据task_type字段筛选特定临床任务,或通过difficulty_level选择适合的挑战层级。输出格式字段(plain_text或json)为不同应用场景提供了灵活性。研究人员建议结合论文提出的模块化方法,包括预指令调优和模型融合技术,以充分发挥数据集在临床任务对齐方面的价值。
背景与挑战
背景概述
MediFlow数据集由Jean-Philippe Corbeil等研究人员于2025年提出,旨在推动临床自然语言处理领域的发展。该数据集由2.5百万条合成指令数据构成,覆盖14种任务类型和98种细粒度临床文档输入,为临床专用语言模型的指令微调提供了重要资源。其创新性体现在采用模块化方法整合预训练、模型融合和任务对齐技术,相关研究成果已发表于arXiv预印本平台。作为目前规模最大的临床指令数据集之一,MediFlow通过GPT-4o生成的高质量负样本,显著提升了判别式偏好优化在医疗文本生成任务中的表现。
当前挑战
在临床自然语言处理领域,MediFlow致力于解决医疗文本理解的复杂语义解析和多任务泛化难题。数据集构建面临三大核心挑战:医疗术语标准化方面需平衡专业术语准确性与模型可解释性;多模态临床文档处理要求统一结构化与非结构化数据的表征方式;指令质量把控环节需确保70万条唯一指令覆盖临床场景的完备性。技术实现上,合成数据生成需克服医疗隐私约束下的真实数据模拟困难,而DPO对齐子集的创建则涉及错误类型标注体系的设计与验证。
常用场景
经典使用场景
在临床自然语言处理领域,MediFlow数据集以其大规模合成指令数据的特性,成为训练和评估临床专用语言模型的首选资源。该数据集覆盖14种任务类型和98种细粒度临床文档,特别适用于指令微调(SFT)和直接偏好优化(DPO)等前沿技术。研究人员可利用其丰富的任务分类和难度分级,系统性地探索模型在临床文本理解、信息抽取和决策支持等方面的能力边界。
实际应用
该数据集直接服务于智能电子病历系统的开发,支持临床文档自动摘要、医学术语标准化等实际应用场景。医疗机构可基于MediFlow训练的模型实现诊疗记录的结构化处理,提升医疗信息系统的互操作性。制药企业则利用其进行大规模医学文献分析,加速药物不良反应监测和临床试验数据挖掘流程。
衍生相关工作
MediFlow已催生多项临床NLP重要研究,包括基于模型融合的领域适应框架和预指令调优技术。其衍生的临床任务对齐方法被广泛应用于生物医学问答系统优化,相关成果发表在JAMIA等顶级期刊。数据集作者团队提出的模块化SLM架构,已成为处理复杂临床语言理解任务的基准解决方案之一。
以上内容由遇见数据集搜集并总结生成


