Chinese-QA-Agriculture_Forestry_Animal_Husbandry_Fishery
收藏Hugging Face2025-04-24 更新2025-04-25 收录
下载链接:
https://huggingface.co/datasets/Mxode/Chinese-QA-Agriculture_Forestry_Animal_Husbandry_Fishery
下载链接
链接失效反馈官方服务:
资源简介:
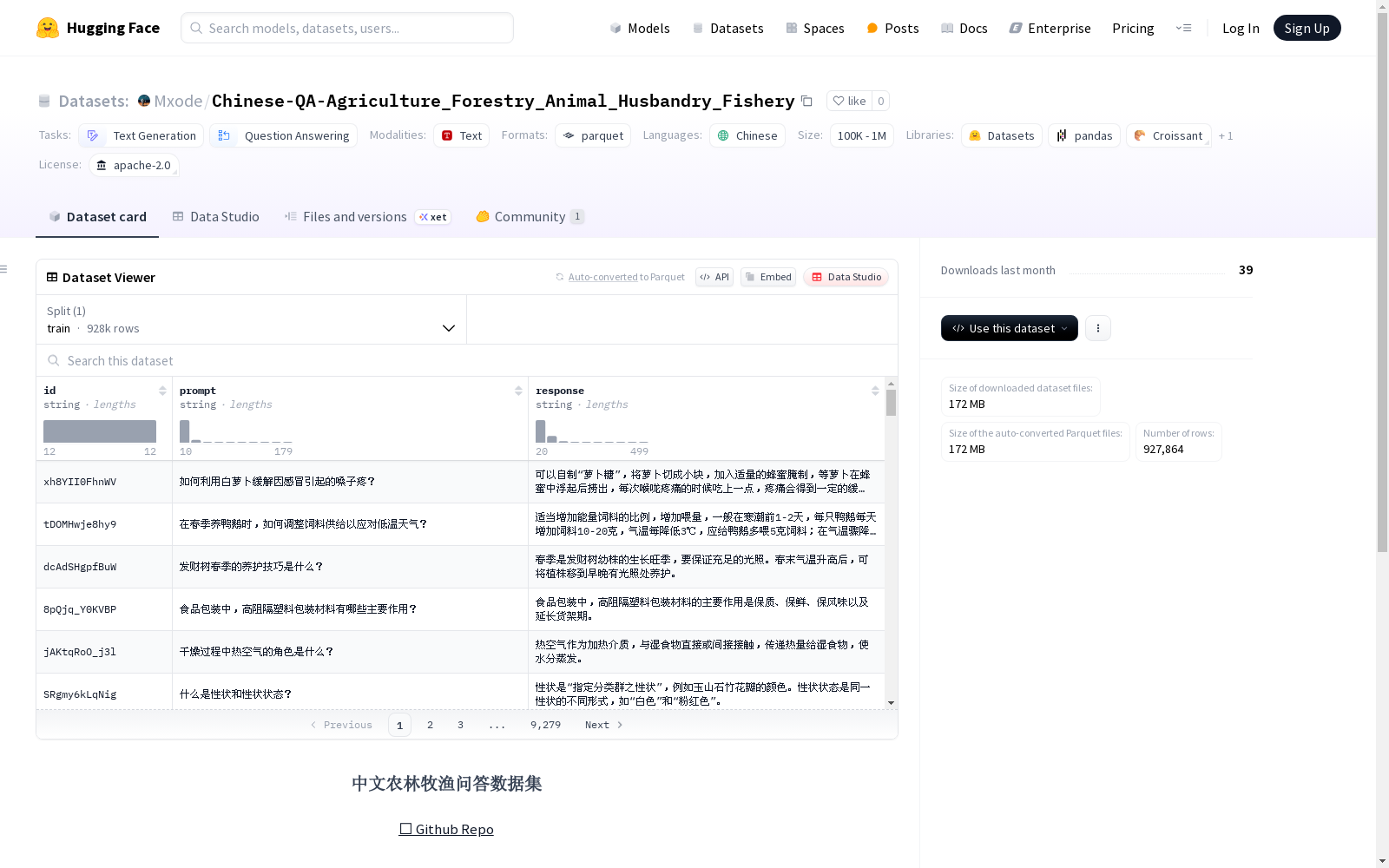
中文农林牧渔问答数据集是一个包含农业、林业、畜牧业和渔业相关问题的数据集,数据量为900K+,以简单的问答对形式存在,每个问答对包括一个问题和一个答案。
创建时间:
2025-04-23
搜集汇总
数据集介绍
构建方式
该数据集聚焦于农林牧渔领域的知识问答,通过系统化采集和整理行业相关的问题与答案构建而成。数据来源涵盖农业、林业、畜牧业和渔业四大板块,采用标准化的数据清洗流程确保质量,最终形成超过90万条结构化的问答对。每条数据均以JSON格式存储,包含唯一的12位nanoid标识符、问题文本及对应答案,为后续模型训练提供了规范化的数据基础。
特点
作为中文领域首个大规模农林牧渔专业问答数据集,其显著特点在于覆盖范围广且专业性强。数据内容涉及作物栽培、林木养护、畜禽养殖和水产捕捞等细分领域,问题设计简洁明了,答案准确精炼。900K+的数据规模为模型训练提供了充足的语料,而统一的JSON格式则极大便利了数据的解析与应用,特别适合用于农业知识问答系统的开发与优化。
使用方法
该数据集主要适用于自然语言处理领域的文本生成和问答系统研究。使用者可通过解析JSON文件获取问答对,直接用于模型的监督学习。在农业智能客服、专业知识问答等应用场景中,建议先对数据进行领域适配性预处理,再输入至BERT、GPT等预训练模型进行微调。数据集的标准化格式也支持与其他领域问答数据进行联合训练,以增强模型的跨领域理解能力。
背景与挑战
背景概述
中文农林牧渔问答数据集由Mxoder团队构建,旨在为农业、林业、畜牧业及渔业领域提供高质量的中文问答数据支持。该数据集创建于近年,数据量超过90万条,采用简单的问答形式,覆盖了农林牧渔领域的广泛知识。该数据集的推出填补了中文农业领域问答数据的空白,为自然语言处理技术在农业智能化、知识问答系统等应用场景提供了重要的数据基础。其开源特性也促进了农业知识服务领域的学术研究和工业应用发展。
当前挑战
该数据集面临的主要挑战包括领域专业性与数据质量的平衡问题。农林牧渔领域包含大量专业术语和复杂知识体系,确保问答对的准确性和专业性是一大难点。在构建过程中,数据收集面临领域知识分散、专家资源有限等困难。同时,中文农业文本存在表述多样性、地域差异大等特点,给数据清洗和标准化带来挑战。此外,如何保持数据的前沿性以反映快速发展的农业技术也是持续性的难题。
常用场景
经典使用场景
在农业知识智能化的研究领域中,该数据集为构建专业领域的问答系统提供了重要支撑。研究者通过分析90万条结构化问答对,能够训练出精准理解农林牧渔领域术语的语义模型,特别是在农作物病虫害防治、水产养殖技术等垂直场景中展现出色的意图识别能力。
实际应用
实际应用中,该数据集已支撑多个省级农业智能助手的开发,农户通过语音交互即可获取精准的种植建议。在渔业灾害预警系统中,基于该数据集训练的模型能自动解析渔民咨询,快速关联气象水文数据库生成防灾指导,显著提升了应急响应效率。
衍生相关工作
围绕该数据集衍生的经典工作包括基于对比学习的农业知识检索系统AgriRetriever,以及融合多模态数据的智慧农业问答框架AgriMM。这些成果在ACL、AAAI等顶会发表后,进一步催生了农业大模型训练范式的研究热潮。
以上内容由遇见数据集搜集并总结生成


