SSPDEBench/Reuglar_and_Singular_SPDEBench
收藏Hugging Face2026-05-02 更新2025-08-30 收录
下载链接:
https://hf-mirror.com/datasets/SSPDEBench/Reuglar_and_Singular_SPDEBench
下载链接
链接失效反馈官方服务:
资源简介:
SPDEBench是一个用于评估机器学习求解随机偏微分方程方法的基准数据集,包括非奇异SPDE数据集和新型奇异SPDE数据集。非奇异SPDE包含随机Ginzburg-Landau方程、随机Korteweg–De Vries方程、随机波动方程和随机Navier-Stokes方程。新型奇异SPDE包含动态Phi42模型。数据集为每个方程提供1200个样本,分为训练集、验证集和测试集,并考虑了不同截断程度的驱动噪声和不同类型的初始条件。
SPDEBench is a benchmark dataset for evaluating machine learning-based approaches to solving stochastic partial differential equations (SPDEs), including nonsingular SPDE datasets and a novel singular SPDE dataset. The nonsingular SPDE contains stochastic Ginzburg-Landau equation, stochastic Korteweg–De Vries equation, stochastic wave equation, and stochastic Navier-Stokes equation. The novel singular SPDE contains the dynamical Phi42 model. The dataset provides 1200 samples for each equation, divided into training, validation, and testing sets, considering different truncation degrees of driving noise and different types of initial conditions.
提供机构:
SSPDEBench
原始信息汇总
数据集详情概述:SSPDEBench / Reuglar_and_Singular_SPDEBench
基本信息
- 数据集名称:Regular_and_Singular_SPDEBench
- 数据集地址:https://hf-mirror.com/datasets/SSPDEBench/Reuglar_and_Singular_SPDEBench
- 任务类型:Other
- 数据模态:Tabular(表格数据)
- 数据格式:parquet
- 语言:English
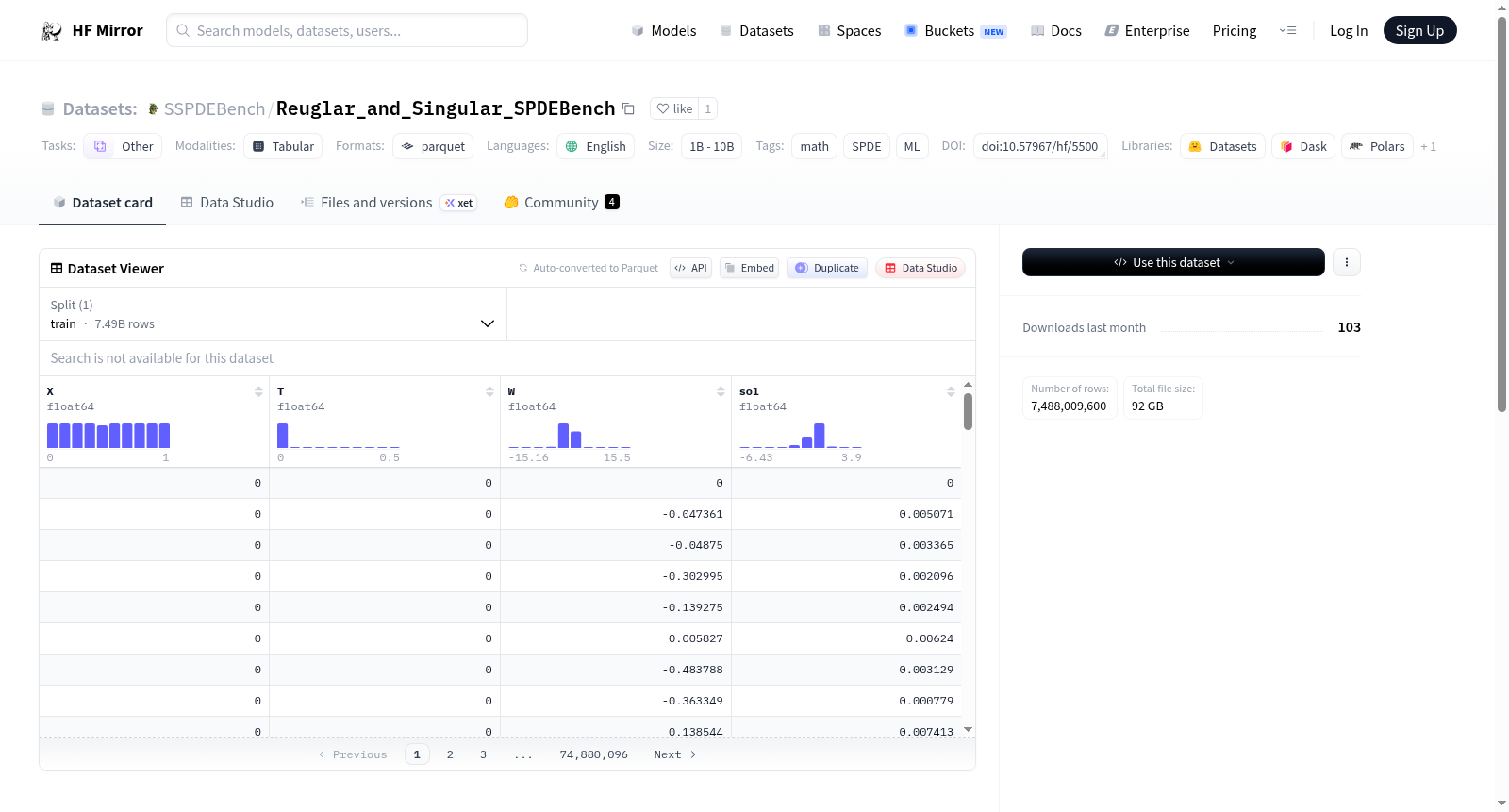
- 数据规模:1B - 10B(具体行数为 7,488,009,600 行,总文件大小 92 GB)
- 标签:math, SPDE, ML
- DOI:doi:10.57967/hf/5500
- 库依赖:Datasets, Dask, Polars
- 下载次数(上月):103
数据集描述
该数据集是用于评估基于机器学习的随机偏微分方程(SPDE)求解方法的基准数据集。数据集包含两类数据:
- 非奇异 SPDE 数据集,包括:
- 随机 Ginzburg-Landau 方程(Phi41)
- 随机 Korteweg–De Vries 方程(KdV)
- 随机波动方程(Stochastic wave equation)
- 随机 Navier-Stokes 方程(NS)
- 新型奇异 SPDE 数据集,包括:
- 动力学 Phi42 模型(Phi42)
数据集划分与样本量
- 每个方程的数据集包含 1200 个样本,其中:
- 70% 用于训练(840 个样本)
- 15% 用于验证(180 个样本)
- 15% 用于测试(180 个样本)
- 每个样本包含:初始条件、驱动噪声、空间网格和时间网格的数据。
数据子集(Subset)与切分(Split)
- Subset 名称:default,行数:7.49B rows
- Split 名称:train,行数:7.49B rows
数据列特征
表中包含以下四列(均为 float64 类型):
- X:范围 [0, 1]
- T:范围 [0, 0.5]
- W:范围 [-15.16, 15.5]
- sol:范围 [-6.43, 3.9]
不同 SPDE 的附加数据说明
- 动力学 Phi42 模型:提供两种生成方法的数据:
- 实施重整化(denoted by reno)
- 未实施重整化(denoted by expl)
- 随机 Ginzburg-Landau 方程:提供不同加性扩散项 sigma 值的数据(sigma = 0.1 或 sigma = 1)
- KdV 方程:提供两种驱动噪声类型的数据:
- 圆柱维纳过程(denoted by cyl)
- Q-维纳过程(denoted by Q)
搜集汇总
数据集介绍
构建方式
该数据集旨在为机器学习方法求解随机偏微分方程(SPDE)提供系统化评估基准。在构建过程中,数据集被划分为非奇异SPDE与奇异SPDE两大类别。非奇异部分涵盖了随机Ginzburg-Landau方程、随机Korteweg–De Vries方程、随机波动方程及随机Navier-Stokes方程,共计四类经典方程。奇异部分则引入了动力学Phi42模型这一全新挑战型方程。每个方程均生成1200个样本,并按照70%训练、15%验证、15%测试的比例划分。样本中包含了初始条件、驱动噪声以及时空网格等完整信息,确保数据集的全面性与实用性。
特点
数据集独具特色之处在于其层次化的参数变异性设计。针对不同方程,引入了多样化的调控参数:对于动力学Phi42模型,提供了是否实施重整化两种生成方式;对于随机Ginzburg-Landau方程,设置了不同强度的加性扩散项;对于KdV方程,则包含了圆柱型Wiener过程与Q-Wiener过程两种驱动噪声。这些精心设计的参数变化,使得数据集能够系统评估模型在不同物理机制与数值复杂度下的泛化能力与鲁棒性。
使用方法
使用者可直接加载各方程对应的HDF5或NumPy格式数据文件,每个文件内已按规范划分好训练集、验证集与测试集。建议采用初始条件与驱动噪声作为模型输入,以时空网格上的解场作为预测目标。对于奇异SPDE部分,应特别关注是否启用重整化模块,以验证模型对奇异扰动的处理能力。该基准支持多种机器学习框架,并鼓励用户针对不同参数设置进行消融实验,深入探究模型性能的边界条件。
背景与挑战
背景概述
随机偏微分方程(SPDE)在物理学、金融学及生物学等诸多领域扮演着关键角色,然而传统数值方法在处理高维或奇异问题时面临严峻的精度与效率瓶颈。随着机器学习技术的迅猛发展,数据驱动方法为SPDE求解开辟了新路径,但此前缺乏系统性基准数据集来评估此类方法的性能。为此,研究人员于近期构建了Regular_and_Singular_SPDEBench数据集,旨在填补这一空白。该数据集由多个研究机构联合开发,核心研究问题聚焦于评估机器学习模型在非奇异与奇异SPDE上的泛化能力。其涵盖随机Ginzburg-Landau方程、KdV方程、随机波动方程、Navier-Stokes方程等经典非奇异模型,以及创新的动态Phi42奇异模型,通过提供标准化数据与多样化配置,显著推动了SPDE求解器评估的规范化与可重复性。
当前挑战
该数据集面临的核心挑战在于双重层面:首先,解决领域问题层面,机器学习方法需同时应对非奇异和奇异SPDE的数值逼近挑战,前者涉及非线性项与随机噪声的耦合效应,后者如Phi42模型因重整化需要处理无穷大发散问题,对算法稳定性构成严峻考验。其次,构建过程中遭遇多重困难,包括生成高保真度数据时需精细调节截断参数(eps)以避免近似误差,实现不同噪声类型(圆柱Wiener过程与Q-Wiener过程)的精确模拟,以及针对奇异方程设计两种生成策略(带重整化与不带重整化)以对比学习效果。此外,为确保数据代表性,采用了70%训练、15%验证、15%测试的划分,并保持各类方程样本数量均衡(各1200组),但这也对采样效率与存储管理提出较高要求。
常用场景
经典使用场景
在随机偏微分方程(SPDE)的数值求解领域,SPDEBench被广泛用于评估机器学习模型在捕捉复杂随机动力系统演化规律方面的能力。该数据集涵盖了非奇异SPDE(如随机Ginzburg-Landau方程、KdV方程、波动方程和Navier-Stokes方程)以及新颖的奇异SPDE(如动态Phi42模型),为研究者提供了多样化的初始条件、驱动噪声类型和截断程度配置。经典的用法是将初始条件与驱动噪声作为输入,训练神经网络等模型预测时空网格上的解场,从而检验算法对不同正则性、非线性和奇异性问题的泛化能力。
解决学术问题
SPDEBench的出现有效解决了现有基准缺乏奇异SPDE数据以及噪声配置单一的问题。学术研究中,传统数值方法在处理奇异SPDE时往往因重整化步骤而显得繁琐,而SPDEBench通过提供有无重整化的Phi42模型数据,使研究者能够系统对比机器学习方法在奇异情形下的表现。此外,该数据集还助推了关于噪声类型(如圆柱Wiener过程与Q-Wiener过程)和扩散系数对模型精度影响的研究,深化了对ML求解SPDE鲁棒性及可解释性的理解,对推动计算数学与机器学习的交叉融合具有重要意义。
衍生相关工作
SPDEBench的发布催生了一系列经典衍生工作,其中包括利用物理信息神经网络(PINN)对SPDEBench中的随机Ginzburg-Landau方程进行求解的研究,以及基于算子学习的深度算子网络(DeepONet)在SPDEBench非奇异数据集上的性能基准测试。此外,有学者针对奇异SPDE提出了新的神经算子架构,通过引入重整化修正模块在Phi42数据集上取得了更优的误差表现。更近期的研究则关注数据增强策略对SPDEBench中KdV方程预测精度的提升,以及利用生成模型对驱动噪声进行超分辨率重建,从而扩展了该数据集在低分辨率观测场景下的应用边界。
以上内容由遇见数据集搜集并总结生成


