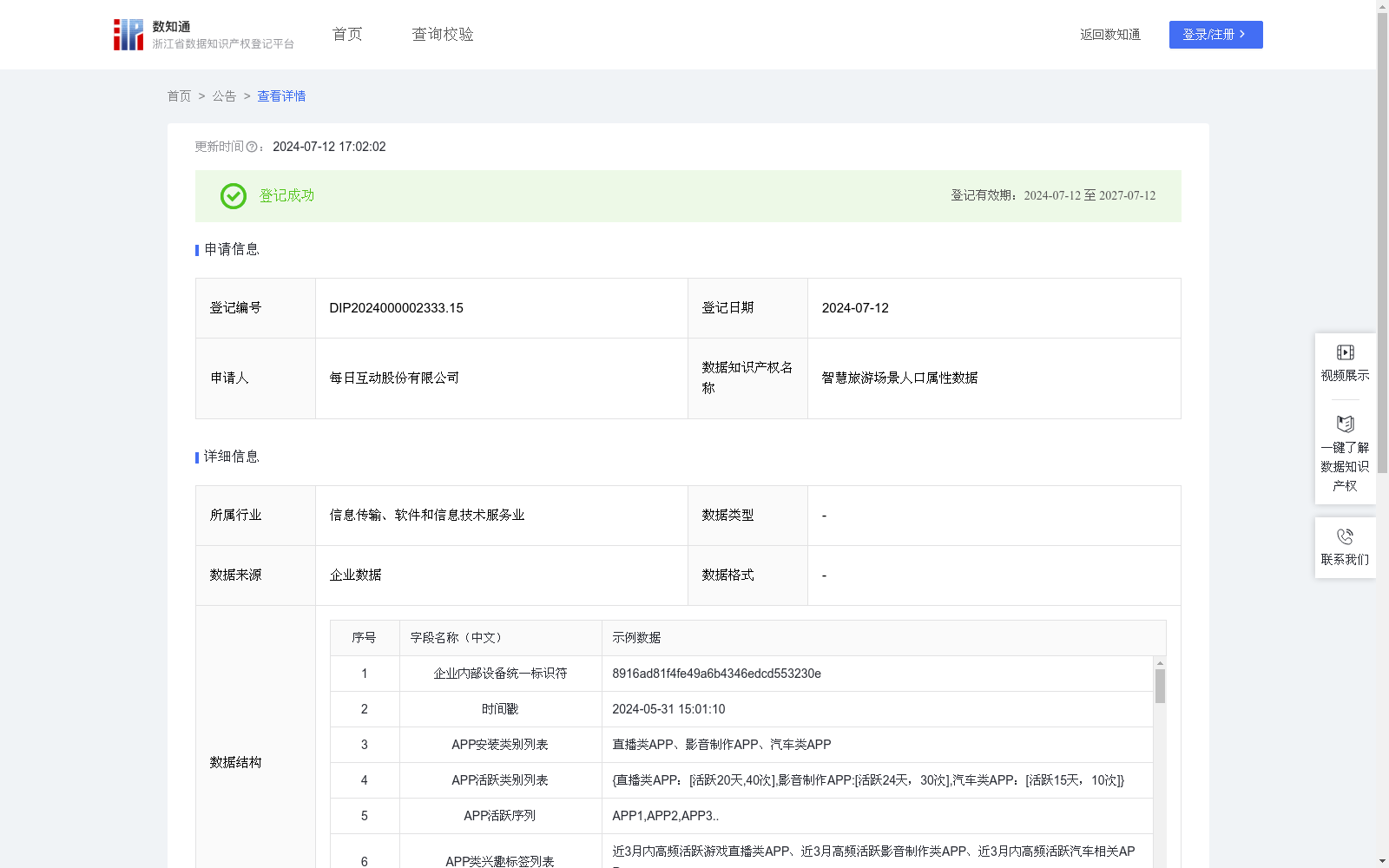
智慧旅游场景人口属性数据
收藏浙江省数据知识产权登记平台2024-07-12 更新2024-07-13 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/37815
下载链接
链接失效反馈官方服务:
资源简介:
a. 游客行为分析:通过收集和分析景区内游客的人口属性数据,如年龄层次、性别、地域分布等,可以深入了解游客的行为特征、偏好和需求。
b. 景区规划与管理:人口属性数据可以帮助景区进行更合理的规划和管理。
c. 安全管理:人口属性数据在景区的安全管理中也发挥着重要作用。市场研究与预测:景区人口属性数据为市场研究提供了宝贵的素材。
d. 个性化服务:基于人口属性数据,景区可以为游客提供个性化的服务。在自研的每日治数平台上对数据抽取、清理和处理,完成数据仓库层建设,通过用户近期线下场景偏好数据,通过机器学习得到景区人口属性数据。
一、数据抽取、清理和处理
数据抽取:从数据库中抽取与用户LBS类相关的原始数据。
数据清理:对抽取的数据进行清洗,去除重复、错误或无关的信息。这包括处理缺失值、异常值、格式转换等,确保数据的准确性和一致性。
数据处理:对清洗后的数据进行必要的转换和整合,如数据聚合、特征提取等,以便后续的分析和建模。
二、数据仓库层建设
1.数据模型设计
2.ETL过程
3.数据仓库优化
三、基于用户线下场景偏好数据预测景区人口属性数据
特征提取:从用户LBS类数据中提取关键特征,如景区LBS历史各时段人数、用户对应常驻城市。
模型选择:根据业务需求和数据特点,选择合适的机器学习模型,如时间序列模型(AR、MA、ARMA、ARIMA)。
模型训练与评估:使用历史数据对模型进行训练,并通过交叉验证等方法评估模型的性能。根据评估结果调整模型参数和结构,优化模型的预测能力。
预测景区人口:将训练好的模型应用于预测新用户或新数据,预测景区人口数据。
a. Tourist Behavior Analysis: By collecting and analyzing demographic attribute data of tourists within scenic spots (including age groups, genders, and regional distribution), in-depth insights into tourists' behavioral characteristics, preferences and demands can be obtained.
b. Scenic Spot Planning and Management: Demographic attribute data can assist scenic spots in conducting more rational planning and management.
c. Safety Management: Demographic attribute data also plays a vital role in the safety management of scenic spots. Market Research and Forecasting: Demographic attribute data of scenic spots provides valuable materials for market research.
d. Personalized Services: Based on demographic attribute data, scenic spots can deliver personalized services to tourists.
On the self-developed Daily Data Governance Platform, data extraction, cleaning and processing are conducted, and the construction of the data warehouse layer is completed. The demographic attribute data of scenic spots is derived through machine learning based on users' recent offline scene preference data.
I. Data Extraction, Cleaning and Processing
1. Data Extraction: Extract raw data related to user Location-Based Services (LBS) from the database.
2. Data Cleaning: Clean the extracted data to eliminate duplicate, erroneous or irrelevant information, including handling missing values, outliers, format conversion and other operations to ensure data accuracy and consistency.
3. Data Processing: Perform necessary conversions and integrations on the cleaned data, such as data aggregation, feature extraction and other steps, to facilitate subsequent analysis and modeling.
II. Data Warehouse Layer Construction
1. Data Model Design
2. ETL (Extract, Transform, Load) Process
3. Data Warehouse Optimization
III. Prediction of Scenic Spot Demographic Attribute Data Based on Users' Offline Scene Preference Data
1. Feature Extraction: Extract key features from user LBS data, such as the number of people in each historical time period at the scenic spot's LBS, and the user's corresponding permanent city.
2. Model Selection: Select appropriate machine learning models based on business requirements and data characteristics, including time series models such as AutoRegressive (AR), Moving Average (MA), AutoRegressive Moving Average (ARMA) and AutoRegressive Integrated Moving Average (ARIMA).
3. Model Training and Evaluation: Train the model using historical data, and evaluate the model's performance through methods such as cross-validation. Adjust the model's parameters and structure according to the evaluation results to optimize its predictive capability.
4. Scenic Spot Population Forecasting: Apply the trained model to new users or new datasets to forecast scenic spot population data.
提供机构:
每日互动股份有限公司
创建时间:
2024-06-27
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


