scala
收藏Hugging Face2024-07-17 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/alexandrainst/scala
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含多个语言版本,每个版本都有文本、错误类型和标签三个特征。数据集用于评估语言的可接受性,即判断文本是否语法正确。数据集通过自动生成的方式创建,使用了通用依赖树库中的文档,并通过脚本引入错误。数据集支持多种语言,包括丹麦语、瑞典语、挪威语、冰岛语、法罗语、德语、荷兰语和英语。
创建时间:
2024-07-17
原始信息汇总
数据集卡片 ScaLA
数据集描述
数据集摘要
该数据集包含文档及其语法正确性判断。数据集通过自动生成,使用脚本对通用依存树库中的文档进行损坏。
支持的任务和排行榜
该数据集旨在用于语言可接受性评估(正确/不正确的二元分类)。排行榜可在此处查看。
语言
数据集支持以下语言:
- 丹麦语 (
da) - 瑞典语 (
sv) - 挪威博克马尔语 (
nb) - 挪威尼诺斯克语 (
nn) - 冰岛语 (
is) - 法罗语 (
fo) - 德语 (
de) - 荷兰语 (
nl) - 英语 (
en)
数据集结构
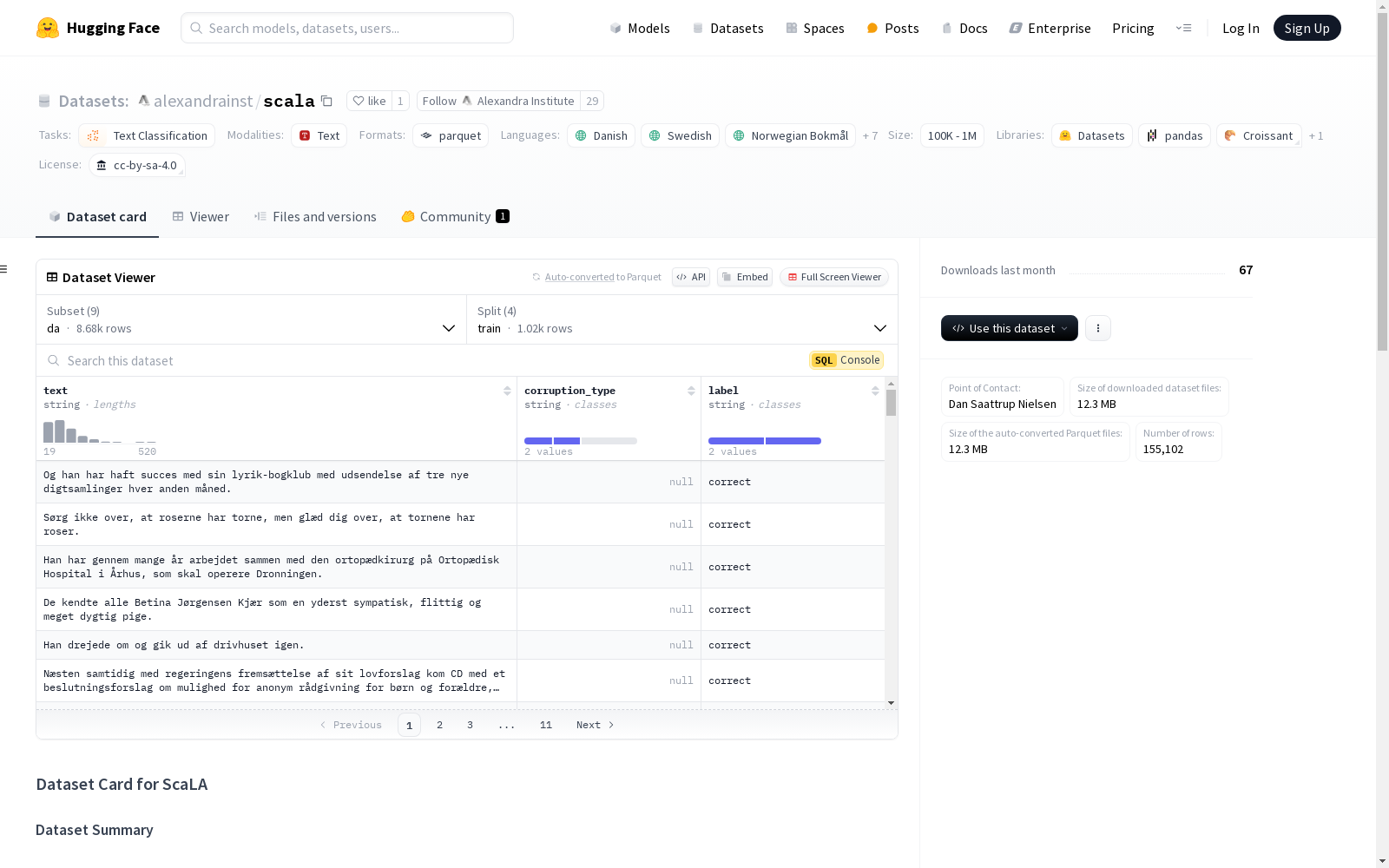
数据字段
text: 字符串类型特征。corruption_type: 字符串或空类型特征。label: 字符串类型特征。
数据分割
数据集包含以下分割:
trainvaltestfull_train
数据集大小
da配置:- 下载大小:703702 字节
- 数据集大小:1195591 字节
de配置:- 下载大小:2609370 字节
- 数据集大小:4263943 字节
en配置:- 下载大小:1490532 字节
- 数据集大小:2517869 字节
fo配置:- 下载大小:240821 字节
- 数据集大小:506374 字节
is配置:- 下载大小:665385 字节
- 数据集大小:1242819 字节
nb配置:- 下载大小:2159785 字节
- 数据集大小:3635659 字节
nl配置:- 下载大小:1551953 字节
- 数据集大小:2633807 字节
nn配置:- 下载大小:2086411 字节
- 数据集大小:3495664 字节
sv配置:- 下载大小:810940 字节
- 数据集大小:1455846 字节
数据集创建
数据来源
数据集从通用依存数据集中收集。
附加信息
许可证信息
数据集基于 CC BY-SA 4.0 许可证。
搜集汇总
数据集介绍
构建方式
ScaLA数据集通过自动化脚本从通用依存树库中生成,该脚本对文档进行语法破坏处理,生成包含正确与错误文本的样本。数据来源于多种语言的通用依存数据集,确保了数据的多样性和广泛性。构建过程中,文档被随机破坏以生成错误样本,同时保留原始正确样本,形成了二元分类任务的基础。
使用方法
ScaLA数据集主要用于语言学可接受性评估任务,特别是二元分类任务,即判断文本是否语法正确。用户可通过加载数据集配置文件,访问不同语言的数据集。数据集支持直接用于模型训练、验证和测试,也可用于构建多语言语法评估的基准测试。通过ScandEval平台,用户可参与公开的排行榜,评估模型性能。
背景与挑战
背景概述
ScaLA数据集由Dan Saattrup Nielsen及其团队创建,旨在解决多语言语法正确性检测的问题。该数据集基于通用依存树库(Universal Dependencies)自动生成,涵盖了丹麦语、瑞典语、挪威语、冰岛语、法罗语、德语、荷兰语和英语等多种语言。其核心研究问题在于通过文本分类任务,评估模型在判断文本语法正确性方面的能力。ScaLA的创建填补了相关语言在语法接受度数据集上的空白,为自然语言处理领域的研究提供了重要的资源支持。
当前挑战
ScaLA数据集面临的挑战主要体现在两个方面。首先,语法正确性检测任务本身具有较高的复杂性,尤其是在多语言环境下,不同语言的语法规则差异显著,模型需要具备跨语言的泛化能力。其次,数据集的构建过程中,自动生成的文本可能引入噪声,尤其是在处理低资源语言时,数据质量和多样性难以保证。此外,如何确保生成的错误类型(如翻转相邻词或删除词)能够真实反映实际语法错误,也是构建过程中的一大挑战。
常用场景
经典使用场景
ScaLA数据集在自然语言处理领域中被广泛用于语言可接受性评估任务。该数据集通过自动生成的语法错误文本,提供了丰富的训练和测试样本,使得研究人员能够构建和优化二分类模型,以判断文本是否在语法上正确。这种任务在语言模型训练、语法检查工具开发以及多语言处理系统中具有重要应用。
解决学术问题
ScaLA数据集解决了在多种语言中缺乏语法可接受性评估数据的问题。通过提供丹麦语、瑞典语、挪威语等多种语言的标注数据,该数据集为研究人员提供了跨语言的基准测试工具,推动了多语言语法分析领域的研究进展。其自动生成的错误类型(如相邻词翻转、删除等)也为语法错误的系统性研究提供了丰富的数据支持。
实际应用
在实际应用中,ScaLA数据集被用于开发语法检查工具和语言学习辅助系统。例如,教育技术公司可以利用该数据集训练模型,为学生提供实时的语法错误反馈。此外,多语言翻译系统和语音识别系统也可以通过该数据集优化其语法处理能力,从而提高用户体验和系统性能。
数据集最近研究
最新研究方向
在自然语言处理领域,ScaLA数据集为多语言语法正确性评估提供了重要的资源。近年来,随着多语言模型的快速发展,研究者们利用该数据集探索了跨语言的语法错误检测与纠正技术。特别是在低资源语言(如冰岛语、法罗语)中,ScaLA数据集的应用显著提升了语法分析模型的性能。此外,结合深度学习与迁移学习技术,研究者们正在开发更高效的语法错误分类模型,以应对不同语言间的语法差异。这些研究不仅推动了多语言语法分析技术的发展,也为低资源语言的自动化处理提供了新的可能性。
以上内容由遇见数据集搜集并总结生成


