contaminated-documents
收藏Hugging Face2025-11-25 更新2025-11-26 收录
下载链接:
https://huggingface.co/datasets/openeurollm/contaminated-documents
下载链接
链接失效反馈官方服务:
资源简介:
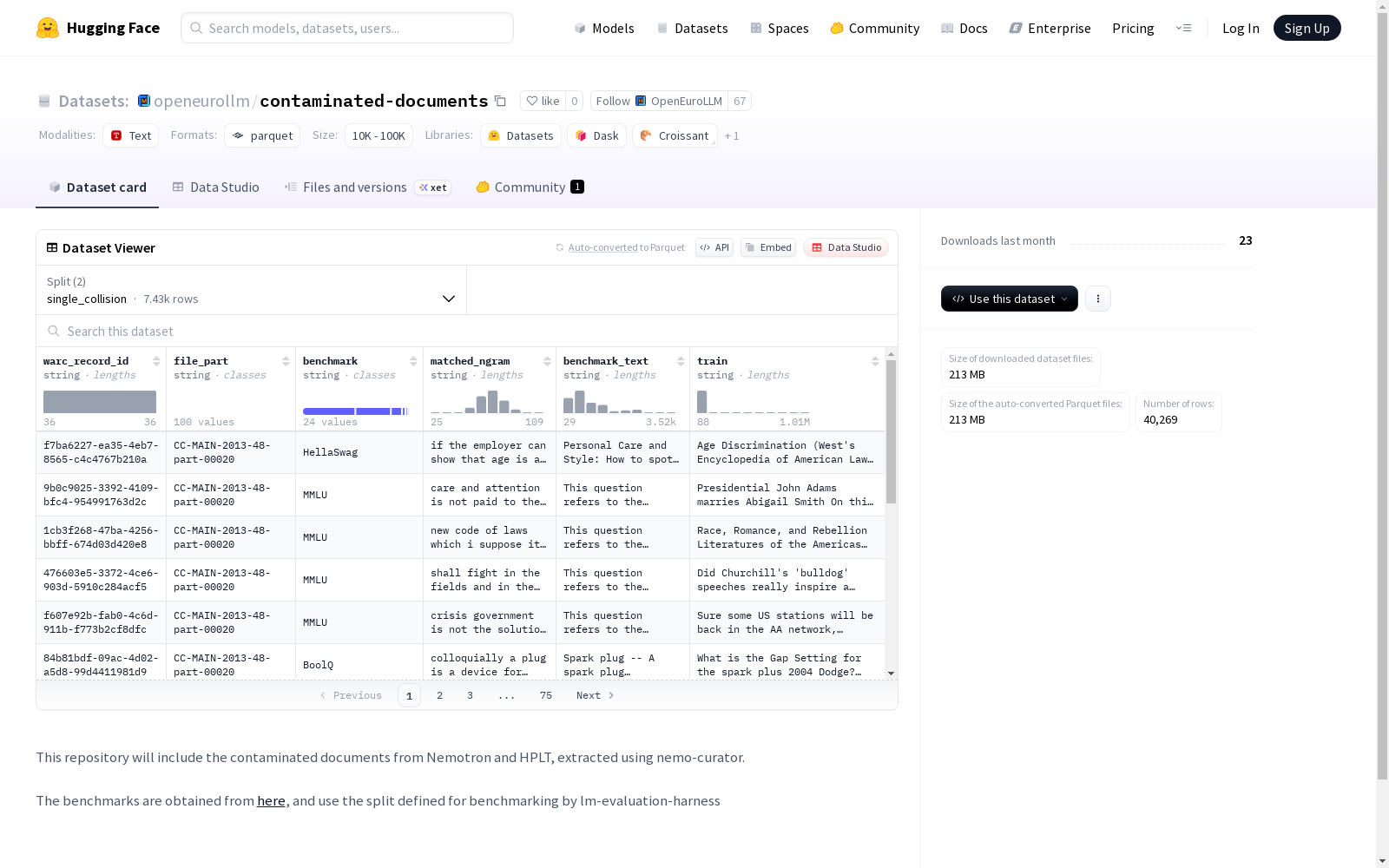
这是一个包含从Nemotron和HPLT中提取的受污染文档的数据集,用于评估文本匹配的benchmark。数据集分为single_collision和all_collisions两个部分,包含了用于训练和测试的文本记录,具体包括记录ID、文件部分、benchmark名称、匹配的n-gram和benchmark文本等信息。
创建时间:
2025-11-20
原始信息汇总
数据集概述
基本信息
- 数据集名称: contaminated-documents
- 存储库: openeurollm/contaminated-documents
- 配置名称: nemotron_sample
数据特征
- 字段结构:
- warc_record_id (字符串类型)
- file_part (字符串类型)
- benchmark (字符串类型)
- matched_ngram (字符串类型)
- benchmark_text (字符串类型)
- train (字符串类型)
数据划分
- single_collision:
- 样本数量: 7,428
- 数据大小: 189,307,298 字节
- all_collisions:
- 样本数量: 32,841
- 数据大小: 1,044,885,141 字节
存储信息
- 下载大小: 212,808,419 字节
- 数据集总大小: 1,234,192,439 字节
数据来源
- 数据内容: 来自Nemotron和HPLT的污染文档
- 提取工具: nemo-curator
- 基准来源: https://docs.google.com/spreadsheets/d/1uBji9fJFLdaaOnzYI71RGW2IiuHJ2vrmuHsXPIsx_rk/edit?gid=1345345034#gid=1345345034
- 划分标准: 采用lm-evaluation-harness定义的基准测试划分
搜集汇总
数据集介绍
构建方式
在数字文档治理领域,contaminated-documents数据集通过nemo-curator工具从Nemotron和HPLT两大语料源系统性地提取受污染文档。其构建过程采用基准测试框架,原始评测数据来源于公开可溯的标准化表格,并严格遵循lm-evaluation-harness设定的数据划分规范,形成包含单次碰撞与全碰撞两类子集的层次化结构。
特点
该数据集呈现多维特征体系,每个样本均标注了WARC记录标识、文件分区及基准测试类型等结构化元数据。特别值得注意的是其双分支设计:single_collision子集聚焦独立碰撞案例,而all_collisions子集则整合了复合型数据交互现象。这种架构既保留了原始语料的文本完整性,又通过匹配n元语法实现了细粒度污染模式追踪。
使用方法
研究者可基于数据集的二分划分子集开展差异化学术探索,single_collision适用于基础污染模式分析,all_collisions则支持复杂场景下的交叉验证。典型应用流程包括加载指定配置的文档切片,通过benchmark_text与train字段的对比研究语料污染机制,亦可借助matched_ngram特征进行数据清洗算法的效果评估。
背景与挑战
背景概述
随着大规模语言模型在自然语言处理领域的广泛应用,数据污染问题逐渐成为影响模型评估可靠性的关键因素。contaminated-documents数据集由Nemotron与HPLT研究团队联合构建,旨在系统性地识别训练数据与基准测试集之间的文本重叠现象。该数据集通过nemo-curator工具从海量网络文档中提取可能污染评估结果的文本片段,为研究社区提供了量化数据污染程度的重要工具。其核心研究目标在于建立透明可控的基准测试环境,推动语言模型评估方法的标准化进程,对提升人工智能研究的可复现性具有深远意义。
当前挑战
数据污染检测面临多重技术挑战:在领域问题层面,需要精准识别训练集与测试集之间不同粒度的文本相似性,包括直接复制、语义等价改写等复杂场景;构建过程中需处理网络文档的异构性,应对多语言编码、非规范文本结构等数据质量问题。同时,基准测试标签的跨平台对齐要求开发高效的文本匹配算法,而动态更新的网络语料库更要求检测系统具备持续学习能力,这些因素共同构成了数据污染研究领域的技术壁垒。
常用场景
实际应用
在实际应用中,该数据集被广泛集成于数据预处理流程,帮助机构构建更纯净的训练语料库。数据工程师借助其碰撞检测结果优化数据筛选策略,显著降低模型在标准测试集上的过拟合风险。这种实践不仅提升了工业级语言模型的泛化能力,也为合规性审计提供了可追溯的数据证据链。
衍生相关工作
基于该数据集构建的污染检测框架,已催生多项重要研究。例如结合动态去重算法的数据清洗系统、针对多模态数据的污染传播分析模型等。这些工作进一步拓展了数据质量评估的维度,形成了从污染检测到缓解策略的完整方法论体系,持续推动着负责任人工智能的发展。
以上内容由遇见数据集搜集并总结生成


