REAL-MM-RAG_FinSlides
收藏Hugging Face2025-03-16 更新2025-03-17 收录
下载链接:
https://huggingface.co/datasets/ibm-research/REAL-MM-RAG_FinSlides
下载链接
链接失效反馈官方服务:
资源简介:
REAL-MM-RAG-Bench是一个现实世界多模态检索基准,旨在在可靠、具有挑战性和现实的环境中评估检索模型。该数据集通过自动化的管道构建,其中查询由视觉语言模型(VLM)生成,经过大型语言模型(LLM)过滤和改写,以确保高质量的检索评估。为了模拟现实世界的检索挑战,引入了多级查询改写,修改查询在三个不同级别上的表达,确保模型在真正的语义理解上而不是简单的关键词匹配上进行测试。
REAL-MM-RAG-Bench is a real-world multimodal retrieval benchmark designed to evaluate retrieval models in a reliable, challenging and realistic environment. This dataset is constructed via an automated pipeline, where queries are generated by Vision-Language Models (VLMs) and filtered and rewritten by Large Language Models (LLMs) to ensure high-quality retrieval evaluation. To simulate real-world retrieval challenges, multi-level query rewriting is introduced, which modifies the expression of queries at three distinct levels, ensuring that models are tested on genuine semantic understanding rather than simple keyword matching.
创建时间:
2025-03-13
搜集汇总
数据集介绍
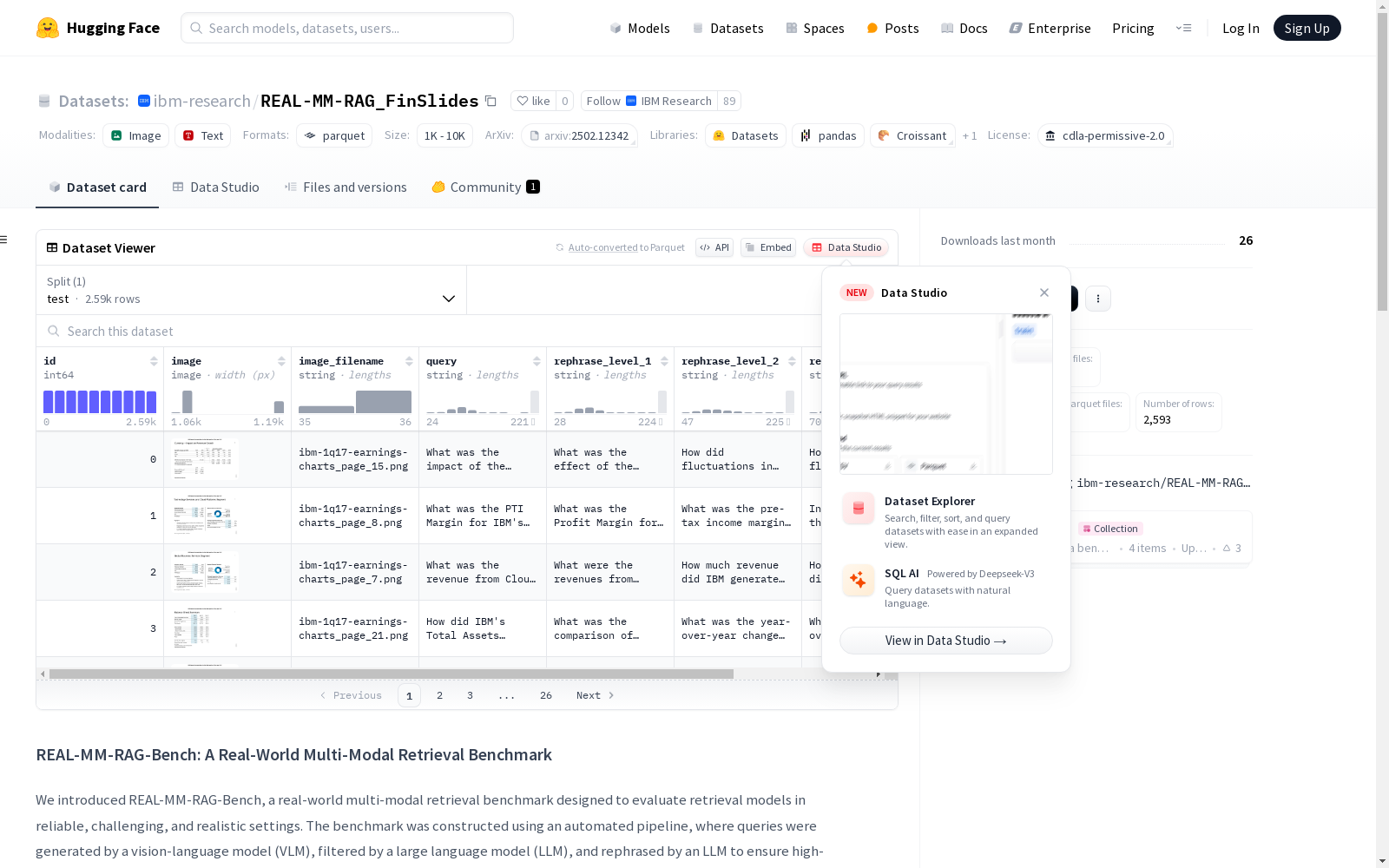
构建方式
REAL-MM-RAG_FinSlides数据集通过自动化流程构建,利用视觉语言模型(VLM)生成查询,经过大型语言模型(LLM)筛选和重写,确保查询的高质量。数据集包含65份季度财务演示文稿,时间跨度从2008年至2024年,总计2280页,主要由表格和关键财务见解组成,以模拟真实世界中的视觉结构化财务演示文稿的检索挑战。
特点
该数据集的特点在于其多模态文档的构成,包含文本、表格和图像,且专注于IBM公司的财务报告,保证了子域的一致性。数据集引入了多级查询重写,从微小的措辞调整到显著的结构性变化,以评估模型在真正语义理解上的能力,而不仅仅是简单的关键词匹配。
使用方法
使用该数据集时,需先安装datasets库。通过load_dataset函数加载数据集,可以索引查询到图像文件名,也可以索引图像文件名到相关查询。此外,数据集处理中需注意部分页面可能没有查询的情况。
背景与挑战
背景概述
REAL-MM-RAG_FinSlides数据集,作为REAL-MM-RAG-Bench的一部分,由IBM研究团队于2025年推出,旨在通过多模态检索评估模型在现实世界中的表现。该数据集的构建采用自动化流程,利用视觉语言模型生成查询,再通过大型语言模型进行过滤和重写,以保障检索评价的高质量。数据集汇集了65份季度财务报告,总计2280页,内容以表格为主,辅以关键财务洞察,为研究者在多模态检索领域提供了宝贵的资源。
当前挑战
该数据集在构建和应用过程中面临的挑战包括:如何确保多模态文档中视觉与文本信息的有效融合,以及如何处理长文档中信息的复杂关联。在研究领域问题方面,数据集需要解决如何准确理解和检索表格密集型财务报告中的信息。此外,多级查询重写技术的应用增加了检索模型的难度,要求模型不仅能处理简单的关键词匹配,还要具备深层次语义理解的能力。
常用场景
经典使用场景
REAL-MM-RAG_FinSlides数据集是针对多模态检索模型在现实世界条件下的可靠性与挑战性进行评估而设计的。该数据集的经典使用场景在于,研究者可通过其提供的多模态文档——主要是表格丰富的财务演示文稿,来训练并测试模型对自然语言查询进行有效信息检索的能力。
解决学术问题
该数据集解决了多模态检索领域中的多个学术研究问题,包括如何处理表格和文本混合的复杂文档,如何确保检索系统理解查询的深层语义而非仅仅匹配关键词,以及如何在实际应用中评估模型的检索准确性和鲁棒性。其意义在于为多模态检索研究提供了现实世界的数据支撑,对于提升模型在实际场景中的应用性能具有重要影响。
衍生相关工作
基于该数据集,研究者们已经衍生出一系列相关工作,包括但不限于对多模态检索模型的改进、查询生成的优化、以及针对特定金融领域的模型定制化研究,这些工作进一步推动了多模态检索技术在金融数据分析中的应用与发展。
以上内容由遇见数据集搜集并总结生成


