NUSAAKSARA
收藏arXiv2025-02-25 更新2025-02-27 收录
下载链接:
https://huggingface.co/datasets/NusaAksara/NusaAksara
下载链接
链接失效反馈官方服务:
资源简介:
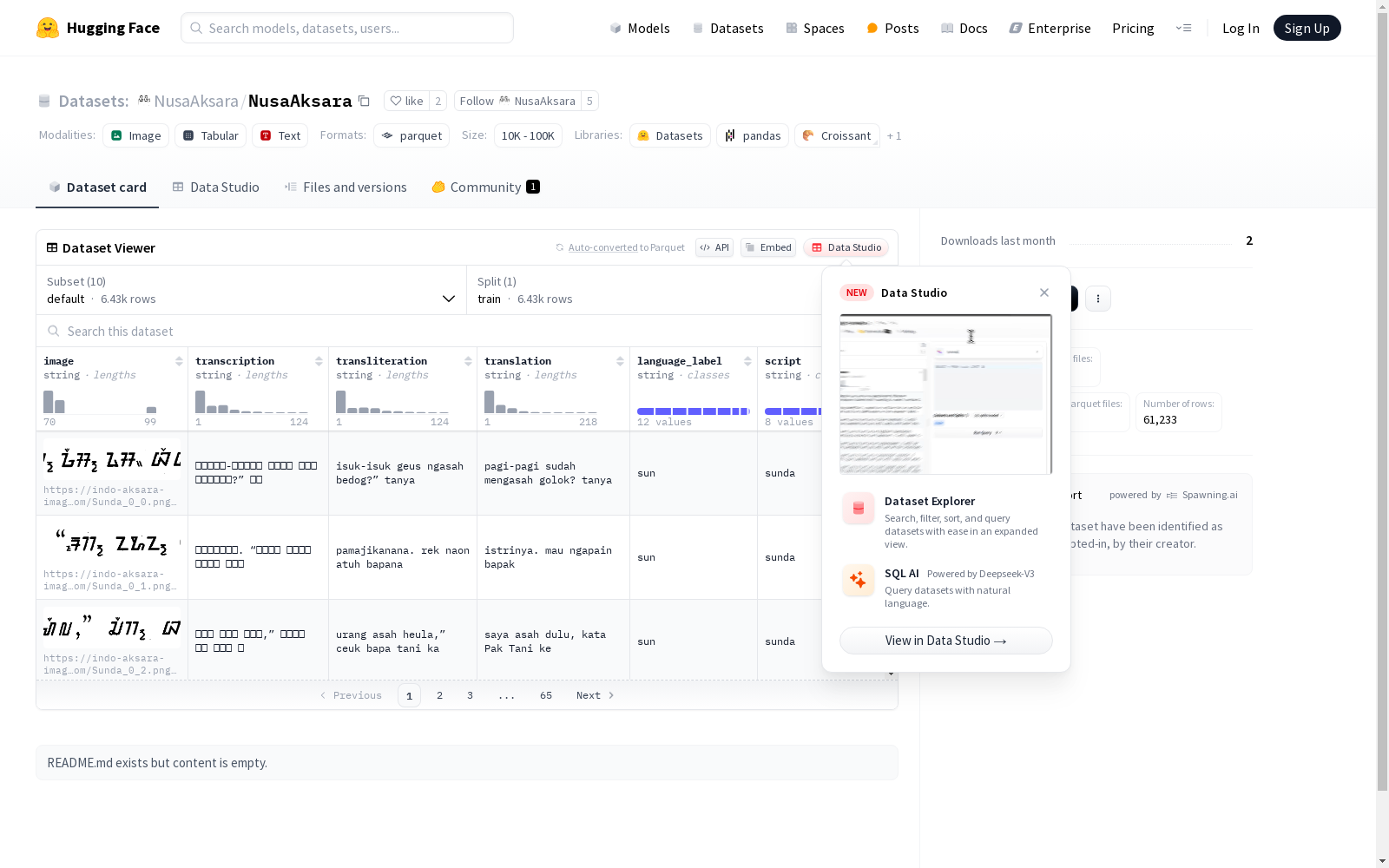
NUSAAKSARA是一个包含文本和图像模态的多模态多语言基准数据集,旨在保存和振兴印度尼西亚的传统脚本。该数据集涵盖了7种语言中的8种脚本,包括一些在NLP基准中不常见的低资源语言。数据集通过专家的严谨步骤构建,包括对文本进行转录、转写和翻译。该数据集可用于多种任务,如图像分割、光学字符识别、转写、翻译和语言识别等。
NUSAAKSARA is a multimodal and multilingual benchmark dataset covering both text and image modalities, which aims to preserve and revitalize Indonesia's traditional scripts. This dataset includes 8 scripts across 7 languages, with several low-resource languages that are rarely encountered in mainstream NLP benchmarks. It is constructed through rigorous expert-led workflows, encompassing text transcription, transliteration, and translation. The dataset supports a wide range of downstream tasks, such as image segmentation, optical character recognition (OCR), transcription, translation, and language identification.
提供机构:
MBZUAI, Monash University Indonesia
创建时间:
2025-02-25
搜集汇总
数据集介绍
构建方式
NUSAAKSARA数据集的构建方式是通过从历史手稿、文学作品、书籍、宗教文本、杂志和教育文献等多种来源收集资源,并进行数字化。数据集由人类专家进行严格的标注和验证,包括转录、转写和翻译成印度尼西亚语。数据集涵盖了8种不同的脚本和7种语言,包括低资源语言。对于没有Unicode支持的Lampung脚本,使用了自定义字体进行标注。
特点
NUSAAKSARA数据集的特点是它包含了8种不同的印尼本地脚本和7种语言,其中大多数语言被认为是低资源语言。数据集涵盖了多种任务,包括图像分割、OCR、转写、翻译和语言识别。数据集由人类专家进行严格的标注和验证,确保了数据的质量和准确性。
使用方法
NUSAAKSARA数据集的使用方法包括多种自然语言处理任务,如图像分割、OCR、转写、翻译和语言识别。数据集可以用于评估和比较各种模型的性能,特别是对于处理印尼本地脚本的能力。数据集的标注和验证过程保证了数据的质量和准确性,使其成为研究和开发印尼本地脚本NLP技术的宝贵资源。
背景与挑战
背景概述
NUSAAKSARA数据集是一项旨在保存印度尼西亚本土文字的创新性公共基准,涵盖了文本和图像两种模态,并包含图像分割、OCR、转写、翻译和语言识别等多种任务。该数据集由人类专家通过严格的步骤构建而成,涵盖了8种文字和7种语言的脚本,包括低资源语言。NUSAAKSARA数据集旨在解决印度尼西亚本土文字在NLP技术中的缺乏支持问题,并促进这些文字的保存和复兴。
当前挑战
NUSAAKSARA数据集面临的主要挑战包括:1) NLP技术对印度尼西亚本土文字的识别能力不足;2) 构建过程中遇到的挑战,如Lampung脚本缺乏Unicode支持,以及一些语言和脚本之间存在重叠,增加了数据标注和语料库构建的复杂性。此外,由于版权和伦理指导原则的限制,数据集仅包含了可用资源的10%,这限制了NUSAAKSARA数据集的进一步发展。
常用场景
经典使用场景
NUSAAKSARA数据集主要用于自然语言处理(NLP)技术的训练和评估,特别是在图像分割、光学字符识别(OCR)、转写、翻译和语言识别(LID)等任务上。该数据集包含了8种不同语言的文本和图像数据,涵盖了多种模态,使得模型可以在多种任务上进行训练和评估。此外,NUSAAKSARA数据集还可以用于研究印尼本土语言和文字的保护和振兴,为语言和文化多样性提供支持。
实际应用
NUSAAKSARA数据集的实际应用场景包括历史文献数字化、文化遗产保护和语言多样性维护。通过对历史文献进行OCR和转写,可以将珍贵的历史资料转化为可搜索和可访问的数字化资源,方便学者研究和公众了解。此外,NUSAAKSARA数据集还可以用于保护和振兴印尼本土语言和文字,通过提供数据支持,使得这些语言和文字可以得到更好的传承和发展。最后,NUSAAKSARA数据集还可以用于研究和开发印尼本土语言NLP技术,为印尼的语言和文化多样性提供技术支持。
衍生相关工作
NUSAAKSARA数据集的发布为后续相关研究提供了基础。例如,基于NUSAAKSARA数据集,可以进一步研究和开发针对印尼本土语言的NLP技术,如OCR、转写、翻译和LID等。此外,NUSAAKSARA数据集还可以用于研究和开发印尼本土语言的语音识别、语音合成和机器翻译等技术,为印尼的语言和文化多样性提供更多技术支持。
以上内容由遇见数据集搜集并总结生成


