WTS
收藏arXiv2024-07-22 更新2024-07-24 收录
下载链接:
https://woven-visionai.github.io/wts-dataset-homepage/
下载链接
链接失效反馈官方服务:
资源简介:
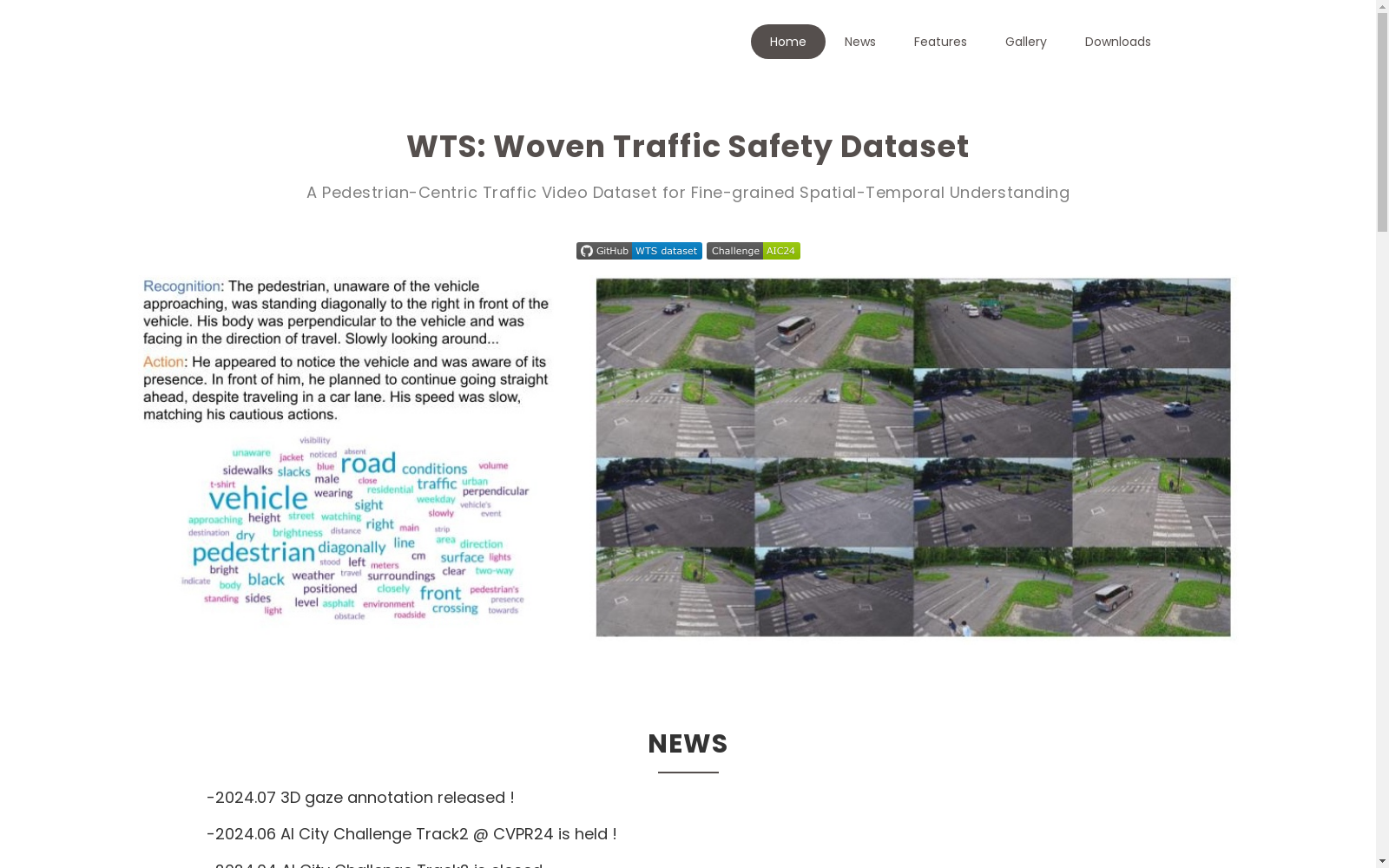
WTS数据集是由丰田纺织和东京大学共同创建的一个以行人为中心的交通视频数据集,旨在深入理解交通场景中的细粒度视频事件。该数据集包含超过1.2k的视频事件,覆盖255个交通场景,通过车辆自身和固定高空摄像头的多视角视频,结合详细的文本描述和独特的3D视线数据,专注于行人分析。数据集的创建过程中,采用了多视角同步技术和高清录制,确保了数据的准确性和多样性。WTS数据集主要应用于提升交通安全和自动驾驶技术的发展,特别是在行人行为分析和交通事件的细粒度理解方面。
The WTS dataset is a pedestrian-centric traffic video dataset co-created by Toyota Boshoku and the University of Tokyo, aiming to deeply explore fine-grained video events in traffic scenarios. This dataset includes over 1.2k video events covering 255 traffic scenarios, and focuses on pedestrian analysis by providing multi-view videos captured via in-vehicle and fixed aerial cameras, combined with detailed text descriptions and unique 3D gaze data. During the dataset development process, multi-view synchronization technology and high-definition recording were adopted to ensure the accuracy and diversity of the data. The WTS dataset is mainly used to advance traffic safety and the development of autonomous driving technologies, particularly in pedestrian behavior analysis and fine-grained understanding of traffic events.
提供机构:
丰田纺织
创建时间:
2024-07-22
搜集汇总
数据集介绍
构建方式
WTS数据集的构建采用了多视角的录制方式,包括车载摄像头和固定在路边的俯瞰摄像头。这些摄像头以1080p的分辨率和24帧每秒的帧率记录交通场景,并通过无线电信号进行同步。数据集包括了255个交通场景,每个场景都标注了详细的行为描述,包括行人和车辆的行为。此外,数据集还提供了行人注视点和位置的3D标注数据,以及5千个公开的与行人相关的交通视频的详细文本描述。
特点
WTS数据集的主要特点是其行人中心的视角,它专注于行人的行为,这在现有的交通场景数据集中是相对缺失的。数据集包含了详细的文本描述,这些描述涵盖了交通事件中的四个主要方面:位置、注意力、行为和上下文。此外,WTS数据集还提供了行人注视点和位置的3D标注数据,这为理解行人的注意力和行为提供了独特的视角。最后,数据集还包含了大约5千个公开的与行人相关的交通视频的详细文本描述,这为研究提供了更广泛的数据。
使用方法
WTS数据集的使用方法包括多个方面。首先,它可以用于训练和评估视频到文本的模型,特别是那些专注于理解行人行为的模型。其次,数据集的详细标注和3D注视点数据可以用于开发更精确的交通事件检测和预测系统。此外,数据集还可以用于研究行人行为和注意力的模式,这有助于提高交通安全。最后,数据集的公开视频和描述可以用于教育和培训,以提高人们对行人行为的认识。
背景与挑战
背景概述
随着自动驾驶和交通安全场景分析的快速发展,对视频中的细粒度信息进行理解已成为计算机视觉领域的一项重大挑战。传统的数据集往往关注驾驶员或车辆行为,而忽视了行人的视角。为了填补这一空白,WTS数据集应运而生,该数据集由丰田公司Woven和东京大学共同创建,旨在通过超过1200个视频事件和数百个交通场景,突出展示车辆和行人的详细行为。WTS数据集整合了来自车辆自身视角和固定俯视摄像头的多样化视角,并在车辆-基础设施协同环境中丰富,包括全面的文本描述和独特的3D注视数据,以实现同步的2D/3D视图,重点关注行人分析。此外,WTS还提供了5k个公开来源的与行人相关的交通视频的注释。WTS旨在通过LLMScorer,一个基于大型语言模型的评估指标,来对推理字幕与真实情况的一致性进行评估,并建立了密集的视频到文本任务的基准,探索了最新的视觉-语言模型,并以实例感知的VideoLLM方法作为基准。WTS的目标是推进细粒度视频事件理解,增强交通安全和自动驾驶开发。
当前挑战
WTS数据集面临的挑战包括:1)解决交通场景中细粒度视频事件理解的挑战;2)构建过程中遇到的挑战,例如多视角视频同步、3D注视数据的准确标注以及长文本描述的评估。为了解决这些挑战,WTS数据集采用了多视角视频记录、3D注视数据标注和LLMScorer评估指标。
常用场景
经典使用场景
WTS数据集主要用于自动驾驶和交通安全场景中的细粒度视频事件理解。该数据集提供了超过1.2k个交通场景的视频事件,包括车辆和行人的详细行为。它集成了来自车辆自身和固定摄像头等多视角的视频,并提供了综合的文字描述和独特的3D视线数据,以实现同步的2D/3D视图,重点关注行人分析。此外,WTS还提供了约5k个公开来源的行人相关交通视频的标注。WTS旨在推进细粒度视频事件理解,增强交通安全和自动驾驶技术的发展。
衍生相关工作
WTS数据集的发布引发了大量相关研究。例如,基于WTS数据集,研究人员开发了一种基于LLM的视频字幕评分器,用于评估视频字幕的语义正确性。此外,还提出了一种基于实例感知的VideoLLM方法,用于细粒度视频到文本任务。这些研究工作进一步推动了视频理解和视频字幕生成技术的发展,为自动驾驶和交通安全领域带来了新的可能性。
数据集最近研究
最新研究方向
WTS数据集专注于交通场景中的行人行为理解,旨在填补现有数据集对行人行为关注度不足的空白。该数据集融合了车辆和固定摄像头多视角的视频,以及丰富的文本描述和独特的3D注视数据,为交通视频事件的理解提供了新的视角。WTS数据集的引入为自动驾驶和交通安全领域的研究提供了宝贵的资源,特别是对于细粒度的视频事件理解。该数据集通过提供行人行为的详细描述,以及3D注视和位置信息,有助于深入分析行人的注意力和行为。此外,WTS数据集还引入了基于大型语言模型(LLM)的视频字幕评分器LLMScorer,以更好地评估视频字幕的语义正确性。通过WTS数据集,研究人员可以探索最先进的视觉-语言模型,并使用实例感知的VideoLLM方法作为基准,以推动细粒度的视频事件理解研究。WTS数据集的发布,标志着交通视频理解研究进入了一个新的阶段,为自动驾驶和交通安全领域的发展提供了强有力的支持。
相关研究论文
- 1WTS: A Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding丰田纺织 · 2024年
以上内容由遇见数据集搜集并总结生成


