DeepDive
收藏github2025-10-02 更新2025-10-03 收录
下载链接:
https://github.com/THUDM/DeepDive
下载链接
链接失效反馈官方服务:
资源简介:
DeepDive是一个用于训练深度搜索代理的数据集,通过知识图谱中的受控随机游走生成具有挑战性的问答对,支持复杂多步信息搜索任务。数据集包含4108个条目,包括问答对和监督微调轨迹,专门设计用于深度搜索代理的多轮强化学习训练。
DeepDive is a dataset for training deep search agents. It generates challenging question-answer pairs via controlled random walks over knowledge graphs, and supports complex multi-step information search tasks. The dataset contains 4108 entries, including question-answer pairs and supervised fine-tuning trajectories, and is specifically designed for multi-turn reinforcement learning training of deep search agents.
创建时间:
2025-09-13
原始信息汇总
DeepDive数据集概述
数据集基本信息
- 数据集名称: DeepDive
- 发布机构: THUDM
- 发布时间: 2025年9月
- 论文链接: https://arxiv.org/abs/2509.10446
- 数据集链接: https://huggingface.co/datasets/zai-org/DeepDive
数据集规模
| 数据组件 | 数量 | 说明 |
|---|---|---|
| 总数据集 | 3,250 | 训练语料库中的所有问答对 |
| SFT部分 | 1,016 | 用于监督微调的数据子集 |
| SFT轨迹 | 858 | 通过拒绝采样从SFT问答对中获得的搜索轨迹 |
| RL部分 | 2,234 | 用于强化学习的数据子集 |
数据构建方法
自动化数据合成流程
知识图谱随机游走: 从初始节点$v_0$开始,在图中导航$k$步形成路径$P=[v_0, v_1, ldots, v_k]$,选择较长路径长度($k > 5$)以增加推理复杂度。
实体混淆: 将路径中的每个节点$v_i$与其对应属性结合形成属性丰富的路径$P_A$,使用LLM混淆整个路径信息,创建需要深度搜索解决的"模糊实体"。
难度过滤: 使用前沿模型(GPT-4o)进行基本搜索,每个问题尝试四次,仅保留前沿模型在所有尝试中都失败的问题,确保高难度。
模型信息
| 模型 | 参数量 | HuggingFace Hub | 性能(BrowseComp) |
|---|---|---|---|
| DeepDive-9B | 9B | 即将发布 | 6.3% |
| DeepDive-32B | 32B | 即将发布 | 14.8% |
评估结果
主要基准测试表现
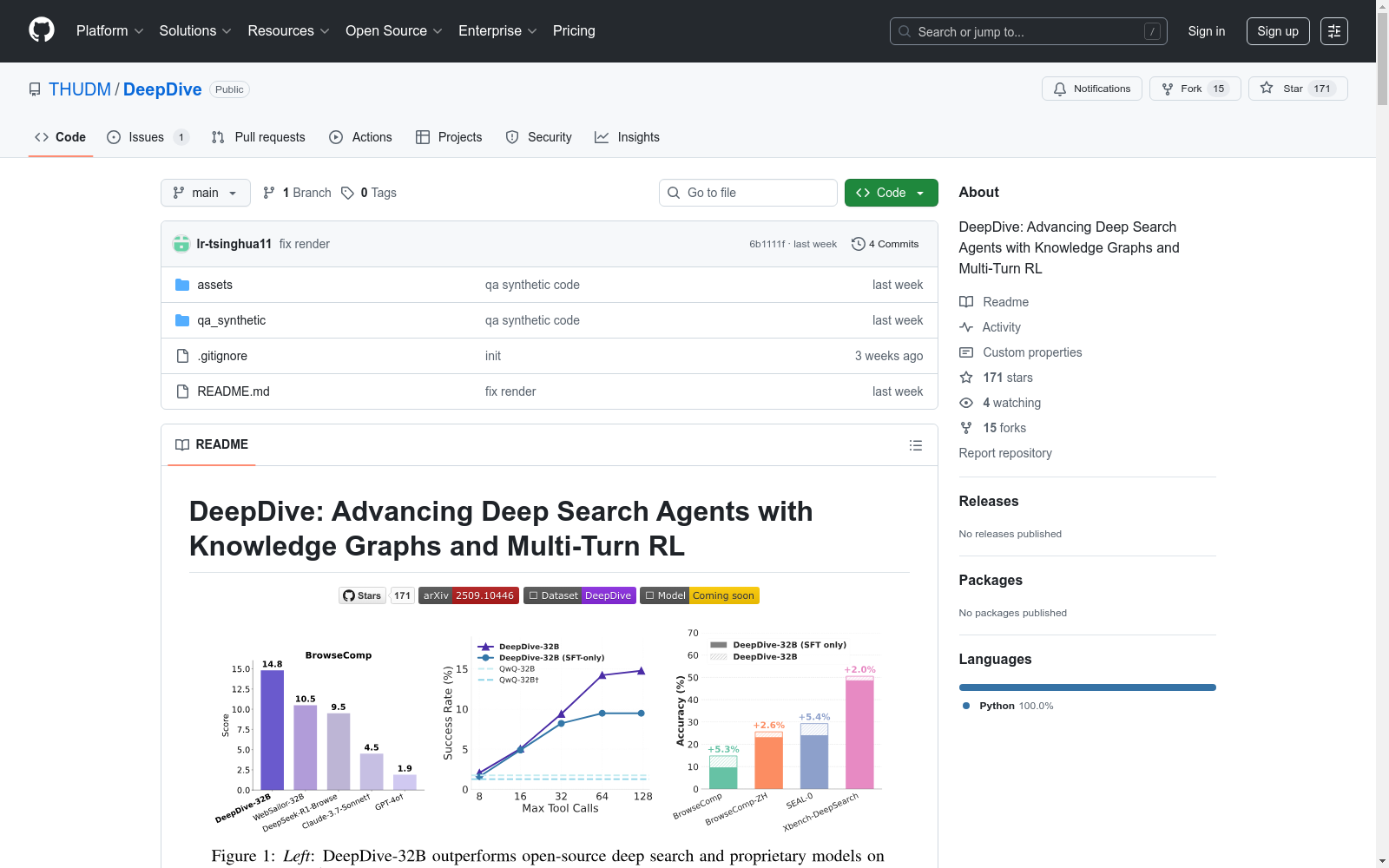
DeepDive-32B在四个深度搜索基准测试中的表现:
- BrowseComp: 14.8%
- BrowseComp-ZH: 25.6%
- Xbench-DeepSearch: 50.5%
- SEAL-0: 29.3%
简单搜索任务泛化能力
在HotpotQA、Frames和WebWalker等简单基准测试中,DeepDive-32B(SFT和RL)持续优于强基线,在WebWalker上获得超过60分,超越WebShaper-72B(52.2)。
测试时扩展能力
工具调用扩展
允许DeepDive在推理过程中进行更多工具调用,在复杂多步任务中实现更高准确率:
- 在BrowseComp上,工具调用从8次增加到128次时,性能从8%提升到15%
- DeepDive-32B在工具调用超过32次时持续优于仅SFT变体
并行采样
为每个问题并行生成8个独立推理轨迹:
- 最少工具调用选择策略将准确率从12.0%(单次推理)提升到24.8%
- 多数投票策略达到18.8%准确率
技术依赖
- 基础模型: GLM-4和QwQ
- RL训练框架: Slime
- Web访问API: Serper和Jina
搜集汇总
数据集介绍
构建方式
在深度搜索智能体研究领域,DeepDive数据集通过知识图谱自动化合成技术构建而成。该方法首先在KILT和AMiner知识图谱中进行长度超过五步的随机游走,形成复杂的多跳推理路径。随后对路径中的实体进行信息模糊化处理,利用大型语言模型将具体细节泛化为模糊实体,从而生成需要深度搜索才能解决的挑战性问题。最后通过前沿模型的多次尝试筛选机制,仅保留所有尝试均失败的难题,确保数据集具备高度复杂性。
特点
该数据集最显著的特点在于其问题的高难度特性,所有问题均经过严格筛选,确保需要深度推理和复杂搜索过程才能解决。数据集包含3,250个问答对,其中1,016个用于监督微调,2,234个用于强化学习训练,并额外提供858条搜索轨迹数据。这些数据覆盖了从基础搜索到复杂多步推理的完整任务谱系,为训练智能体进行长程推理提供了丰富素材。数据集的构建还特别注重实体关系的多样性,通过知识图谱的广泛覆盖确保了问题的广泛代表性。
使用方法
使用该数据集时,研究人员可采用两阶段训练流程。首先利用监督微调部分的数据对基础模型进行初步训练,使其掌握基本的搜索和推理能力。随后使用强化学习部分的数据进行多轮次强化学习训练,通过严格的二元奖励机制优化模型的长程推理能力。在推理阶段,可通过增加工具调用次数和并行采样策略进一步提升模型性能,其中选择工具调用次数最少的答案被证明能显著提高准确率。数据集还支持测试时扩展,允许模型通过多次搜索和推理来应对复杂任务。
背景与挑战
背景概述
DeepDive数据集由清华大学团队于2025年提出,聚焦于深度搜索智能体训练领域。该数据集通过知识图谱随机游走与实体混淆技术,构建了包含3,250个复杂问答对的训练资源,旨在解决多轮信息检索任务中的长程推理难题。其创新性地融合了自动化数据合成与端到端强化学习框架,显著提升了智能体在浏览复杂网络信息时的决策能力,为开放领域搜索任务设立了新的技术基准。
当前挑战
在解决深度搜索领域问题时,该数据集面临多跳推理路径的语义连贯性维护挑战,需确保智能体在长序列动作中保持逻辑一致性。构建过程中,知识图谱的稀疏性与实体模糊化处理导致原始信息损失,需通过严格难度过滤机制保留仅1.2%的高质量数据。多轮强化学习的稀疏奖励设计亦增加了训练稳定性控制的复杂度,要求精确平衡探索与利用策略。
常用场景
衍生相关工作
DeepDive数据集的发布催生了一系列重要的衍生研究工作。基于其构建方法,研究人员开发了多种改进的深度搜索智能体训练框架,如结合思维链推理的增强版本和适应特定领域的知识图谱构建技术。该数据集还启发了对测试时扩展机制的系统性研究,推动了工具调用优化和并行采样策略的发展。在评估基准方面,DeepDive为BrowseComp、Xbench-DeepSearch等深度搜索评测标准的完善提供了重要参考,促进了整个领域在模型架构设计和训练方法上的创新突破。
数据集最近研究
最新研究方向
在深度搜索智能体领域,DeepDive数据集正推动基于知识图谱与多轮强化学习的融合研究。前沿探索聚焦于自动化数据合成机制,通过知识图谱随机游走构建复杂推理路径,结合实体模糊化技术生成高难度问答对,有效解决了传统搜索任务中信息稀疏的瓶颈。多轮强化学习框架采用严格二元奖励机制,显著提升了智能体在长程推理中的稳定性,其在BrowseComp、Xbench-DeepSearch等基准测试中展现的泛化能力,为构建具备人类级复杂问题解决能力的搜索系统提供了新范式。测试时扩展技术的突破性进展,特别是并行采样与工具调用优化策略,使模型在保持高效性的同时实现了准确率倍增,这一技术路径正逐渐成为开放领域搜索智能体的核心发展方向。
以上内容由遇见数据集搜集并总结生成


