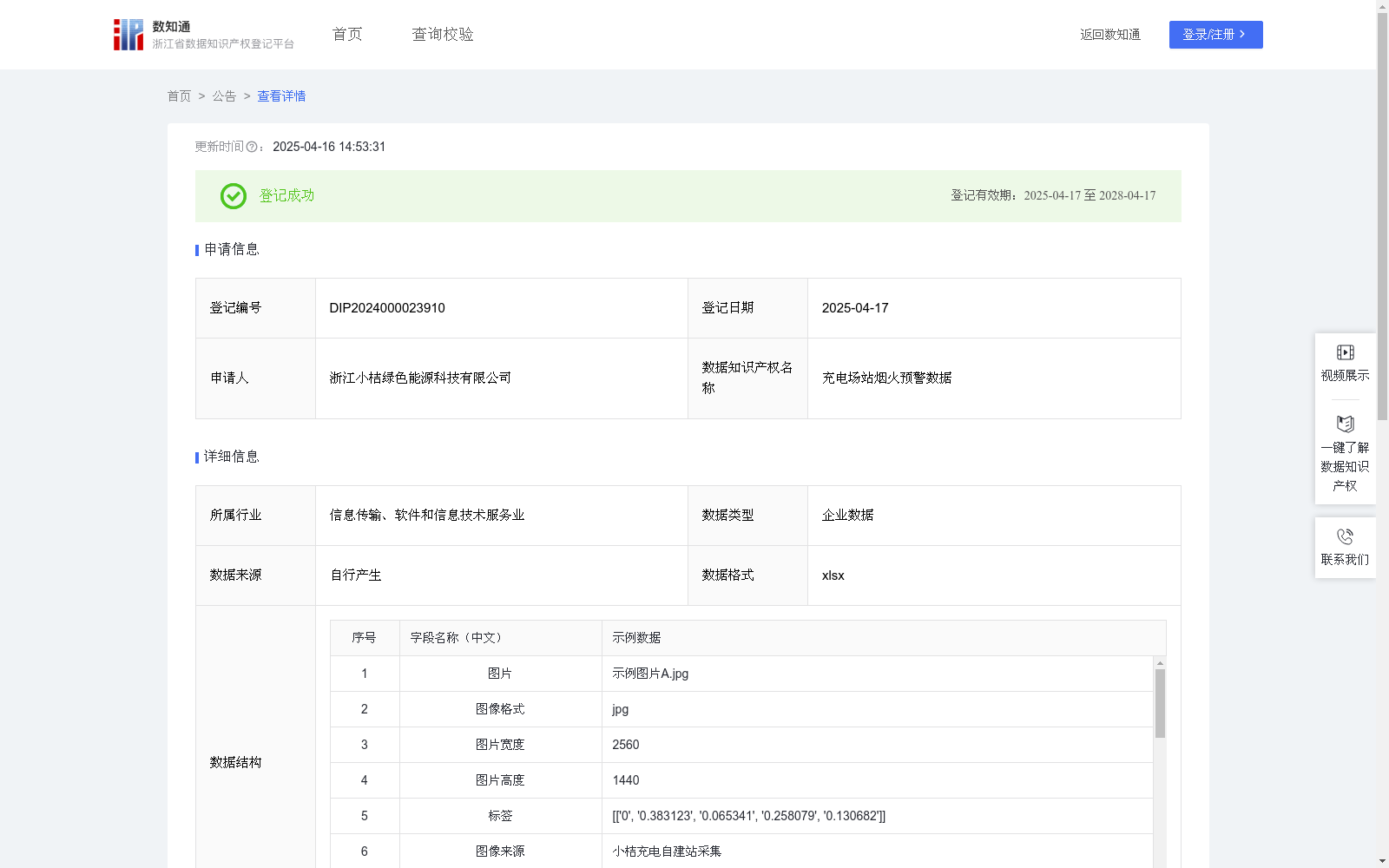
充电场站烟火预警数据
收藏浙江省数据知识产权登记平台2025-04-16 更新2025-04-17 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/124193
下载链接
链接失效反馈官方服务:
资源简介:
数据集为烟火图片数据集,主要应用于基于视觉的,烟火目标检测深度学习模型训练,训练完成的模型,对输入图片中的烟、火目标物有准确的检出能力。数据集全部采集于充电场站的视频监控系统回流、抽帧数据,因此,使用该数据集训练模型特别适用于充电场站场景的烟、火目标检测。该数据集也可用于其他对于烟、火标注图片有使用需求模型训练,例如通用场景下的视觉大模型的训练。1. 数据来源:原始数据来源于小桔能源全国充电场站视频监控系统捕获的车辆自燃、消防演习、其他烟火图片,确保了原始数据在充电场站场景下的多样性和广泛性。
2. 图像标准化处理:包括调整分表率和裁剪,以统一数据格式,确保一致性和适配性
3. 数据增强:应用旋转、缩放、颜色调整、AICG等技术增强数据多样性,提升模型泛化能力。
4. 关键视觉特征提取:从图像中提取关键视觉特征,包括颜色直方图、纹理纹理信息、边缘特征、深度学习特征等
5. 深度学习架构选择:采用YOLO系列模型作为深度学习架构
6. 模型训练与评估:在标注好的数据集训练YOLO模型,通过监督学习的方式让模型学习标准的烟火数据图片。通过交叉验证,使用不同指标如召回率、误报率评估模型的识别能力。
7. 模型优化与验证:通过调整学习率、batch大小等超参;调整模型结构,如更换卷积模块,修改网络深度等对模型进行优化,在独立测试集验证模型性能,确保模型在未见数据也能表现良好
8. 模型推理:模型推理输入为单张图片,输出为图片中检测到烟、火目标的位置信息,如未检测到烟、火目标则输出为空
9. 提交数据信息:所提交的csv文件中,每行数据为推理或训练输入的最小数据单元,对各字段进行说明:
img: 图像数据
width: 图像宽度
height: 图像高度
Label:图像中烟、火目标标签信息,为yolo格式标签,采用以下形式:(class_id, x_center, y_center, width, height)
每个字段具体含义如下
- class_id:目标类别索引,0为烟、1为火。
- x_center:物体边界框的中心点横坐标,归一化到[0, 1]范围。
- y_center:物体边界框的中心点纵坐标,归一化到[0, 1]范围。
- width:物体边界框的宽度,归一化到[0, 1]范围,即width是图像宽度的比例。
- height:物体边界框的高度,归一化到[0, 1]范围,即 height是图像高度的比例。
This is a fire and smoke image dataset primarily used for training visual-based deep learning models for fire and smoke object detection. The trained model can accurately detect smoke and fire targets in input images. All data in this dataset are frame-extracted from the video surveillance systems of nationwide charging stations, so models trained with this dataset are particularly suitable for fire and smoke detection in charging station scenarios. This dataset can also be used for training other models that require labeled fire and smoke images, such as training of visual large models in general scenarios.
1. Data Source: The original data comes from vehicle spontaneous combustion, fire drill, and other fire and smoke images captured by the video surveillance systems of charging stations nationwide under Xiaoju Energy, ensuring the diversity and wide coverage of the original data in charging station scenarios.
2. Image Standardization Processing: Including resolution adjustment and cropping to unify the data format, ensuring consistency and adaptability.
3. Data Augmentation: Techniques such as rotation, scaling, color adjustment, and AICG are applied to enhance data diversity and improve model generalization ability.
4. Key Visual Feature Extraction: Extract key visual features from images, including color histograms, texture information, edge features, deep learning features, etc.
5. Deep Learning Architecture Selection: The YOLO series of models are adopted as the deep learning architecture.
6. Model Training and Evaluation: Train the YOLO model on the labeled dataset, allowing the model to learn standard fire and smoke image data through supervised learning. Conduct cross-validation and evaluate the model's detection performance using metrics such as recall rate and false positive rate.
7. Model Optimization and Validation: Optimize the model by adjusting hyperparameters such as learning rate and batch size; adjust the model structure, such as replacing convolutional modules and modifying network depth. Validate the model's performance on an independent test set to ensure that the model performs well on unseen data.
8. Model Inference: The input of model inference is a single image, and the output is the position information of detected smoke and fire targets in the image. If no smoke or fire targets are detected, the output is empty.
9. Submitted Data Information: Each row in the submitted CSV file represents the smallest data unit for inference or training input. The following describes each field:
img: Image data
width: Image width
height: Image height
Label: Label information of smoke and fire targets in the image, in YOLO format, following the structure: (class_id, x_center, y_center, width, height)
Detailed meanings of each field are as follows:
- class_id: Target category index, where 0 represents smoke and 1 represents fire.
- x_center: The horizontal coordinate of the center point of the object's bounding box, normalized to the range [0, 1].
- y_center: The vertical coordinate of the center point of the object's bounding box, normalized to the range [0, 1].
- width: The width of the object's bounding box, normalized to the range [0, 1], i.e., width represents the proportion of the image width.
- height: The height of the object's bounding box, normalized to the range [0, 1], i.e., height represents the proportion of the image height.
提供机构:
浙江小桔绿色能源科技有限公司
创建时间:
2024-12-26
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个包含501条烟火图片的企业数据,主要用于基于视觉的烟火目标检测深度学习模型训练。数据来源于充电场站的视频监控系统,每日更新,适用于充电场站场景的烟火检测,也可用于通用场景下的视觉大模型训练。
以上内容由遇见数据集搜集并总结生成


