animelist-dataset
收藏Hugging Face2024-11-17 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/labofsahil/animelist-dataset
下载链接
链接失效反馈官方服务:
资源简介:
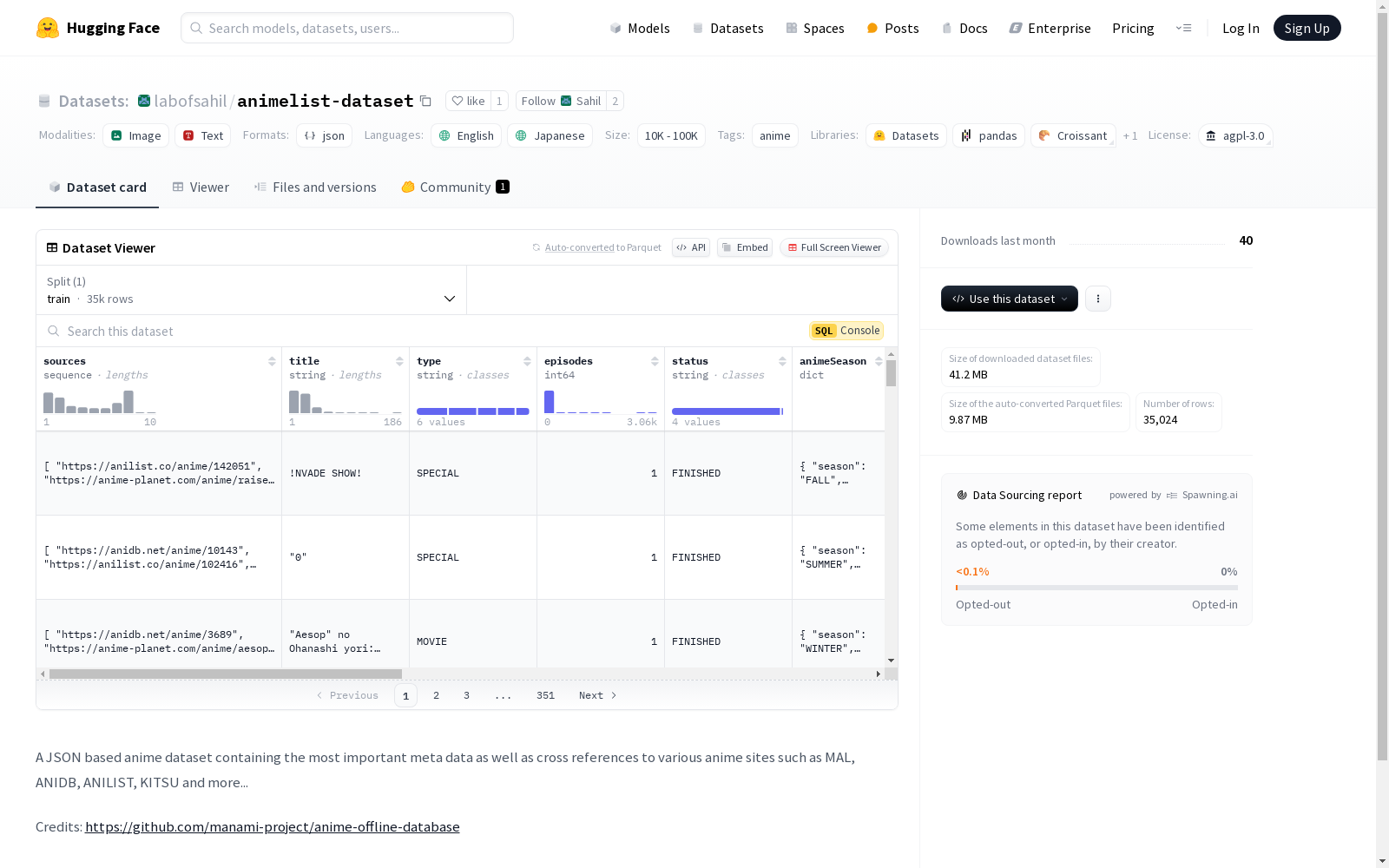
一个基于JSON的动漫数据集,包含了最重要的元数据以及与其他多个动漫网站(如MAL、ANIDB、ANILIST、KITSU等)的交叉引用。数据集每周更新,涵盖了从10K到100K条记录的规模,主要语言为英语和日语,标签为'anime'。
This is a JSON-based anime dataset that includes core metadata and cross-references to various major anime platforms such as MAL, AniDB, AniList, Kitsu, and more. Updated weekly, the dataset contains between 10,000 and 100,000 entries, is primarily available in English and Japanese, and is tagged with 'anime'.
创建时间:
2024-11-16
原始信息汇总
AnimeList Dataset (Updates Weekly)
基本信息
- 许可证: AGPL-3.0
- 语言:
- 英语 (en)
- 日语 (ja)
- 数据规模: 10K<n<100K
- 标签:
- 动漫 (anime)
数据集描述
- 该数据集是一个基于JSON的动漫数据集,包含最重要的元数据以及与多个动漫网站的交叉引用,如MAL、ANIDB、ANILIST、KITSU等。
数据来源
搜集汇总
数据集介绍
构建方式
animelist-dataset的构建依托于manami-project的anime-offline-database项目,采用JSON格式存储,整合了来自多个知名动漫网站如MAL、ANIDB、ANILIST和KITSU的元数据。该数据集每周更新,确保信息的时效性和准确性。通过跨平台数据整合,animelist-dataset为研究者提供了一个全面且动态的动漫信息资源库。
特点
animelist-dataset以其跨平台数据整合和丰富的元数据著称,涵盖了动漫作品的关键信息。数据集不仅包含基本的动漫属性,还提供了与其他动漫数据库的交叉引用,增强了数据的可用性和研究价值。其每周更新的机制保证了数据的实时性,使其成为动漫研究领域的重要资源。
使用方法
animelist-dataset的使用方法简便,用户可通过解析JSON文件获取所需数据。研究者可以利用该数据集进行动漫作品的元数据分析、跨平台数据对比以及动漫推荐系统的开发。由于其数据来源多样且更新频繁,animelist-dataset特别适合用于需要实时数据支持的动漫相关研究项目。
背景与挑战
背景概述
Animelist数据集是一个基于JSON格式的动漫元数据集合,涵盖了多个知名动漫网站如MAL、ANIDB、ANILIST和KITSU等的交叉引用信息。该数据集由manami-project团队创建,并定期更新,旨在为动漫研究者和爱好者提供一个全面且易于访问的资源。自发布以来,Animelist数据集在动漫信息整合、推荐系统开发以及跨平台数据对比等领域发挥了重要作用,极大地推动了相关研究的进展。
当前挑战
Animelist数据集在解决动漫信息整合与跨平台数据对比方面面临多重挑战。首要挑战在于数据的异构性,不同动漫网站的数据格式和标准各异,如何有效整合这些数据并确保一致性成为一大难题。其次,数据更新频率较高,如何实时同步各平台的最新信息,避免数据滞后,是构建过程中需要克服的技术障碍。此外,数据量庞大且复杂,如何在保证数据质量的同时,优化存储和检索效率,也是该数据集持续改进的关键。
常用场景
经典使用场景
在动漫研究领域,animelist-dataset提供了一个全面的元数据资源,涵盖了从基本标题、类型到跨平台引用的详细信息。这一数据集常被用于构建和优化推荐系统,通过分析用户的观看历史和偏好,为动漫爱好者提供个性化的内容推荐。
解决学术问题
animelist-dataset解决了动漫研究中数据分散和整合困难的问题。通过集中多个主流动漫平台的数据,研究者可以更便捷地进行跨平台分析,探讨动漫流行趋势、用户行为模式以及内容创作的影响因素,从而推动动漫研究的深入发展。
衍生相关工作
基于animelist-dataset,学术界和工业界衍生出多项经典工作。例如,研究者利用该数据集开发了基于深度学习的动漫推荐模型,显著提升了推荐的准确性和用户满意度。此外,还有研究通过分析该数据集,揭示了动漫内容在不同文化背景下的传播和接受模式,为跨文化研究提供了新的视角。
以上内容由遇见数据集搜集并总结生成


