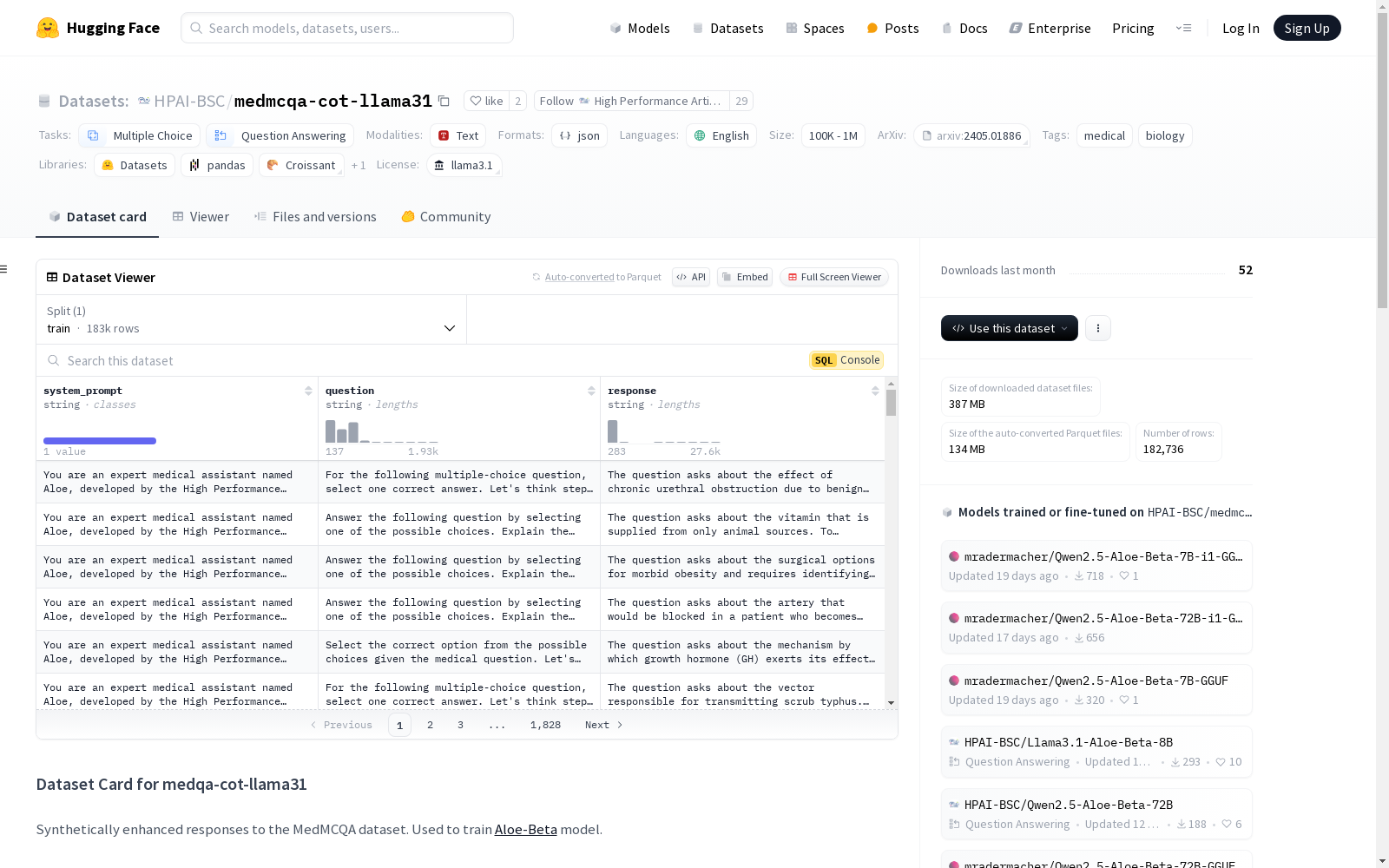
medmcqa-cot-llama31
收藏MedMCQA - CoT 数据集
数据集概述
MedMCQA - CoT 数据集是对 MedMCQA 数据集的合成增强响应。该数据集用于训练 Aloe-Beta 模型。
数据集详情
数据集描述
为了提高 MedMCQA 数据集训练拆分中答案的质量,我们利用 Llama-3.1-70B-Instruct 生成 Chain of Thought (CoT) 答案。我们为数据集创建了一个自定义提示,并结合了手工制作的少量示例。对于多选答案,我们要求模型重新表述并解释问题,然后根据问题解释每个选项,最后总结这些解释以得出最终解决方案。在合成数据生成过程中,模型还会被提供解决方案和参考答案。在模型未能生成正确响应并仅重复输入问题的情况下,我们会重新生成解决方案,直到生成正确的响应。更多细节可在论文中找到。
- 语言(NLP): 英语
- 许可证: Apache 2.0
数据集来源
数据集创建
创建理由
该数据集的创建旨在提供一个基于 MedQA 的高质量、易于使用的指令调优数据集。
引用
BibTeX:
@misc{gururajan2024aloe, title={Aloe: A Family of Fine-tuned Open Healthcare LLMs}, author={Ashwin Kumar Gururajan and Enrique Lopez-Cuena and Jordi Bayarri-Planas and Adrian Tormos and Daniel Hinjos and Pablo Bernabeu-Perez and Anna Arias-Duart and Pablo Agustin Martin-Torres and Lucia Urcelay-Ganzabal and Marta Gonzalez-Mallo and Sergio Alvarez-Napagao and Eduard Ayguadé-Parra and Ulises Cortés Dario Garcia-Gasulla}, year={2024}, eprint={2405.01886}, archivePrefix={arXiv}, primaryClass={cs.CL} }
@InProceedings{pmlr-v174-pal22a, title = {MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering}, author = {Pal, Ankit and Umapathi, Logesh Kumar and Sankarasubbu, Malaikannan}, booktitle = {Proceedings of the Conference on Health, Inference, and Learning}, pages = {248--260}, year = {2022}, editor = {Flores, Gerardo and Chen, George H and Pollard, Tom and Ho, Joyce C and Naumann, Tristan}, volume = {174}, series = {Proceedings of Machine Learning Research}, month = {07--08 Apr}, publisher = {PMLR}, pdf = {https://proceedings.mlr.press/v174/pal22a/pal22a.pdf}, url = {https://proceedings.mlr.press/v174/pal22a.html}, abstract = {This paper introduces MedMCQA, a new large-scale, Multiple-Choice Question Answering (MCQA) dataset designed to address real-world medical entrance exam questions. More than 194k high-quality AIIMS & NEET PG entrance exam MCQs covering 2.4k healthcare topics and 21 medical subjects are collected with an average token length of 12.77 and high topical diversity. Each sample contains a question, correct answer(s), and other options which requires a deeper language understanding as it tests the 10+ reasoning abilities of a model across a wide range of medical subjects & topics. A detailed explanation of the solution, along with the above information, is provided in this study.} }
数据集卡片作者
数据集卡片联系