alpaca-cleaned-gemini-hun
收藏Hugging Face2024-07-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/sarpba/alpaca-cleaned-gemini-hun
下载链接
链接失效反馈官方服务:
资源简介:
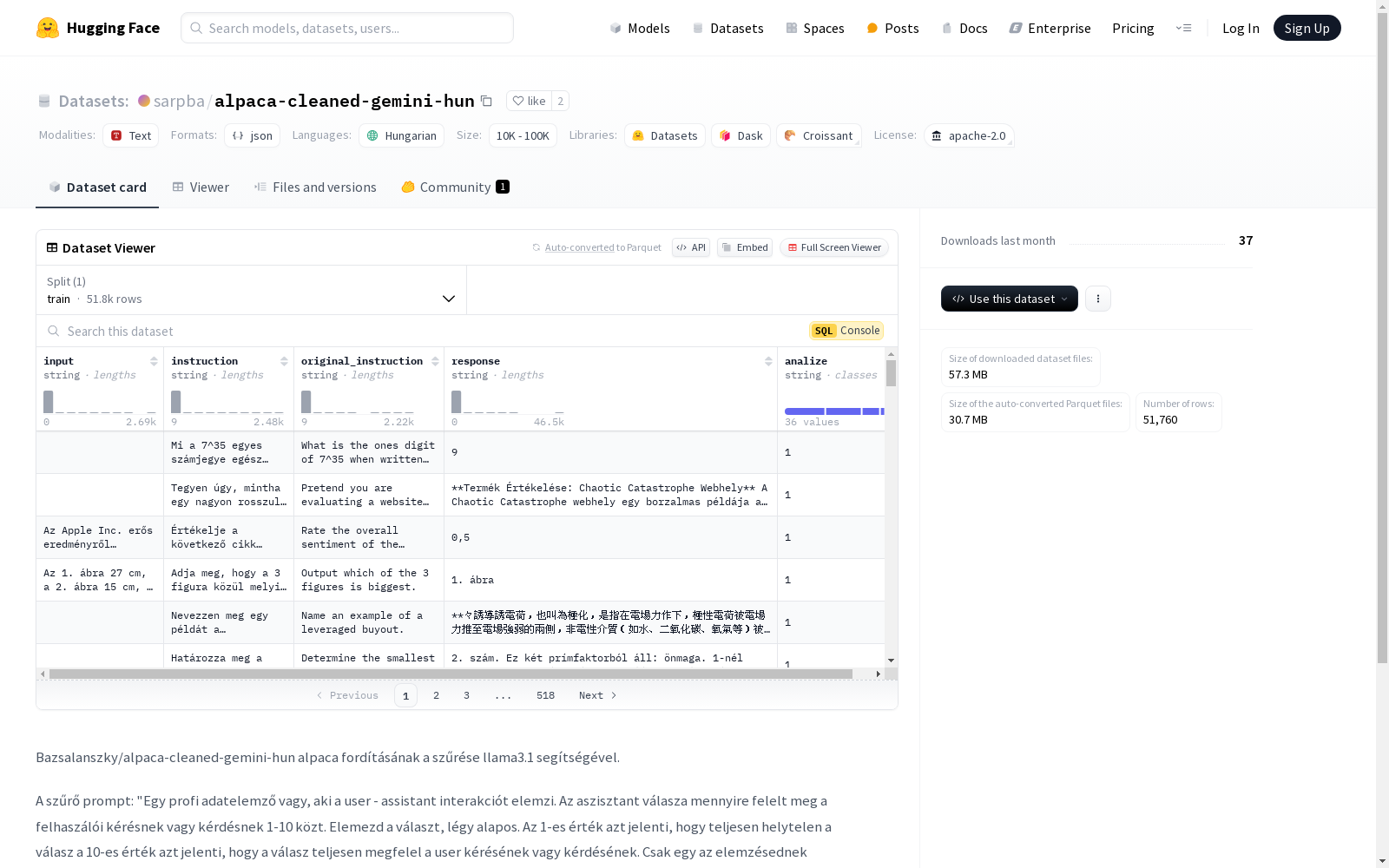
Bazsalanszky/alpaca-cleaned-gemini-hun alpaca翻译的筛选数据集,使用llama3.1模型进行。筛选过程包括一个特定的提示,要求助手分析用户与助手之间的交互,并根据用户请求或问题的匹配程度给出1到10的评分。LLM模型对这些行进行评分,以剔除翻译错误的一部分。不同子集被分到不同的文件中。筛选工作在Colab中完成,相关工作簿可在提供的GitHub链接中找到。
创建时间:
2024-07-28
原始信息汇总
数据集概述
数据集名称
Bazsalanszky/alpaca-cleaned-gemini-hun
许可证
Apache-2.0
语言
匈牙利语
描述
该数据集是通过使用llama3.1模型对alpaca翻译进行筛选得到的。筛选过程中,使用了一个专业的数据分析提示,要求评估助手回答在1到10的范围内对用户请求或问题的符合程度。1表示完全错误,10表示完全符合用户请求或问题。筛选结果被分成不同的子集并存储在文件中。
筛选过程
- 使用LLM模型对翻译文本进行1到10的评分,以筛选出因翻译导致的错误。
- 筛选过程在Colab中进行,需要24GB Nvidia VGA和64GB CPU RAM。
搜集汇总
数据集介绍
构建方式
alpaca-cleaned-gemini-hun数据集的构建基于对alpaca数据集匈牙利语翻译的筛选过程。通过使用llama3.1模型,数据集创建者对翻译结果进行了质量评估。评估过程中,模型根据用户与助手之间的互动质量,对每个回答进行1到10的评分,筛选出符合标准的翻译内容。这一过程在Google Colab环境中完成,确保了数据的高质量和一致性。
特点
该数据集的主要特点在于其高质量的语言翻译和严格的筛选标准。通过llama3.1模型的评分机制,数据集剔除了翻译过程中产生的错误和不准确内容,确保了数据的准确性和可靠性。此外,数据集被细分为多个文件,便于用户根据需求选择和使用。
使用方法
alpaca-cleaned-gemini-hun数据集适用于自然语言处理任务,特别是匈牙利语相关的机器翻译和对话系统开发。用户可以通过访问GitHub上的工作簿链接,获取详细的数据处理和分析方法。数据集的使用需要一定的计算资源,建议在配备24GB Nvidia显卡和64GB CPU内存的环境中运行,以获得最佳效果。
背景与挑战
背景概述
alpaca-cleaned-gemini-hun数据集是一个专注于匈牙利语(hu)的文本翻译与质量评估的数据集,其创建旨在通过LLM(大语言模型)技术对alpaca数据集的翻译结果进行过滤与优化。该数据集的核心研究问题在于如何通过自动化手段提升翻译质量,特别是在用户与助手交互场景中的文本准确性。数据集的主要研究人员或机构并未明确提及,但其构建过程依赖于先进的LLM模型(如llama3.1)和专业的提示工程(prompt engineering)。该数据集对匈牙利语的自然语言处理(NLP)领域具有重要影响,为多语言翻译和对话系统的优化提供了新的数据支持。
当前挑战
alpaca-cleaned-gemini-hun数据集在构建过程中面临多重挑战。首先,翻译质量的自动化评估本身具有高度复杂性,尤其是在多语言场景下,语义准确性和文化适配性难以量化。其次,LLM模型的评分机制依赖于人工设计的提示词(prompt),其设计是否合理直接影响过滤效果。此外,数据集的构建需要高性能计算资源(如24GB Nvidia GPU和64GB CPU内存),这对研究者的硬件条件提出了较高要求。最后,尽管数据集通过过滤减少了翻译错误,但如何进一步优化模型以处理更复杂的语言现象仍是一个未解决的难题。
常用场景
经典使用场景
在自然语言处理领域,alpaca-cleaned-gemini-hun数据集主要用于训练和评估匈牙利语的语言模型。该数据集通过LLM模型对alpaca翻译的匈牙利语文本进行评分和过滤,确保文本质量符合用户需求。这一过程不仅提升了数据集的准确性,还为研究者提供了高质量的匈牙利语语料,用于模型训练和性能测试。
解决学术问题
alpaca-cleaned-gemini-hun数据集解决了匈牙利语自然语言处理研究中高质量语料稀缺的问题。通过LLM模型的评分机制,数据集有效过滤了翻译过程中产生的错误,提供了更为精准的匈牙利语文本。这不仅为匈牙利语的语言模型训练提供了可靠的数据支持,还推动了跨语言自然语言处理技术的发展。
衍生相关工作
基于alpaca-cleaned-gemini-hun数据集,研究者们开发了多种匈牙利语自然语言处理模型和工具。例如,一些工作利用该数据集优化了匈牙利语的机器翻译系统,显著提升了翻译质量。此外,该数据集还被用于匈牙利语文本分类和情感分析任务,推动了匈牙利语自然语言处理领域的研究进展。
以上内容由遇见数据集搜集并总结生成


