TBC-Bench
收藏arXiv2024-12-10 更新2024-12-12 收录
下载链接:
https://github.com/Aria-Zhangjl/StoryWeaver
下载链接
链接失效反馈官方服务:
资源简介:
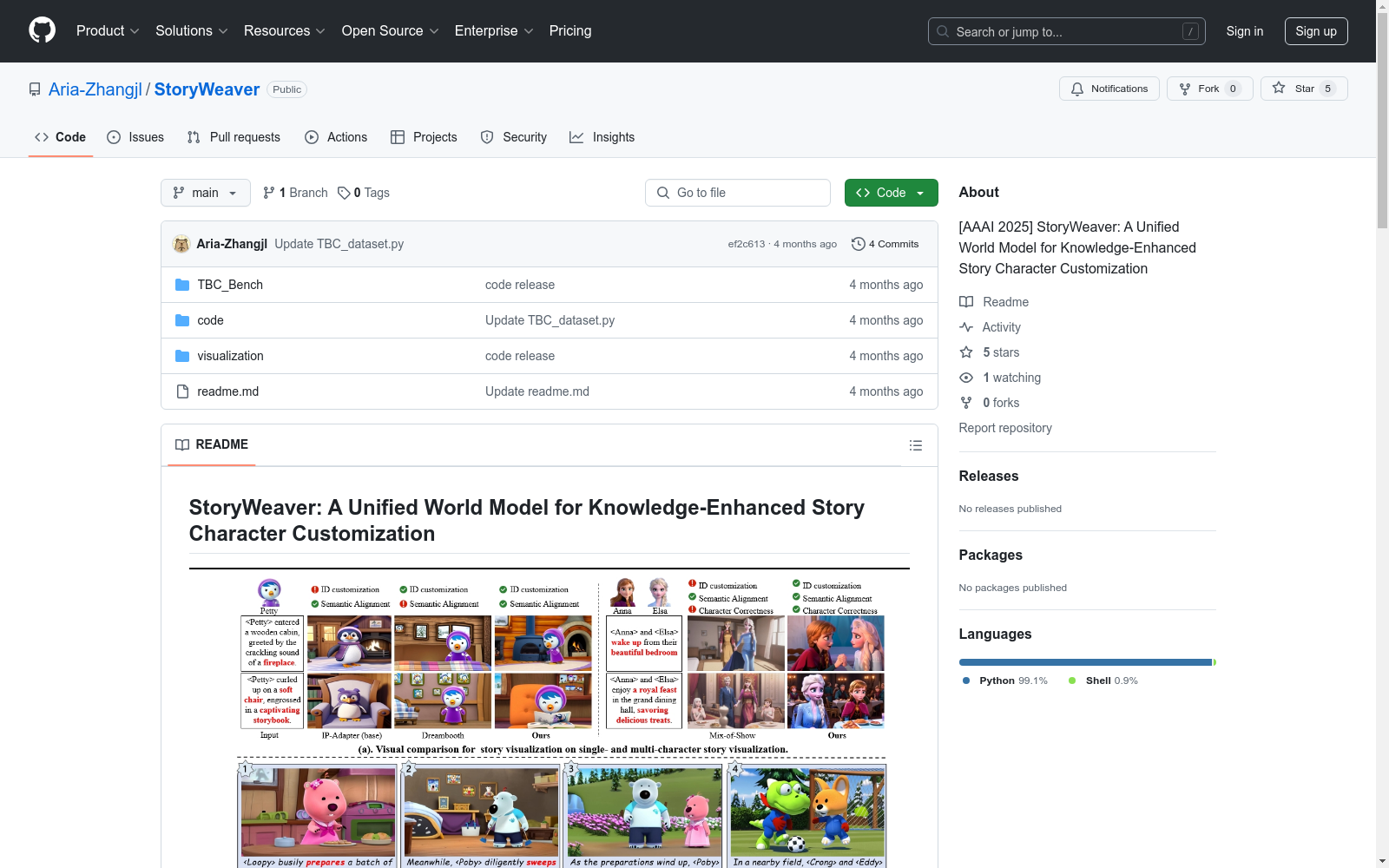
TBC-Bench是一个用于故事可视化任务的新基准数据集,由厦门大学和网易伏羲人工智能实验室共同创建。该数据集旨在评估多角色故事生成中的角色身份保持和文本语义对齐能力。数据集包含了丰富的角色属性、关系和事件描述,通过详细的语义建模来增强故事场景的生成质量。创建过程中,研究团队利用视觉语言模型和场景图解析器提取角色和事件的详细语义信息,并结合知识增强的空间指导技术,确保多角色生成任务中的精确性和一致性。该数据集主要应用于教育、娱乐等领域,特别是在漫画书创作和电影制作中,旨在解决角色身份混淆和语义对齐不准确的问题。
TBC-Bench is a novel benchmark dataset for story visualization tasks, co-created by Xiamen University and NetEase Fuxi AI Lab. This dataset aims to evaluate two core capabilities in multi-role story generation: character identity preservation and text-semantic alignment. It contains rich descriptions of character attributes, relationships and events, and enhances the quality of story scene generation via detailed semantic modeling. During the dataset construction process, the research team utilized vision-language models and scene graph parsers to extract detailed semantic information about characters and events, and integrated knowledge-enhanced spatial guidance technologies to ensure accuracy and consistency in multi-role generation tasks. This dataset is primarily applicable in fields such as education and entertainment, especially in comic book creation and film production, with the objective of resolving the issues of character identity confusion and inaccurate semantic alignment.
提供机构:
中国教育部多媒体可信感知与高效计算重点实验室, 厦门大学, 网易伏羲人工智能实验室
创建时间:
2024-12-10
搜集汇总
数据集介绍
构建方式
TBC-Bench数据集的构建基于两个广受欢迎的卡通系列,即《Pororo the Little Penguin》和《Frozen》。该数据集通过收集每个角色的正面图像以及多个角色互动的场景图像,构建了一个包含丰富语义信息的场景图(Character Graph)。具体而言,每个角色的正面图像通过视觉语言模型(VLM)生成详细的描述,并使用场景图解析器提取与角色相关的属性。此外,数据集还包含了多角色互动的复杂场景,确保了数据集在故事可视化任务中的多样性和挑战性。
特点
TBC-Bench数据集的显著特点在于其丰富的语义信息和多角色互动场景的构建。通过详细的场景图,数据集不仅能够捕捉角色的外观特征,还能描述角色之间的关系和互动。此外,数据集的高分辨率图像(512×896)确保了生成图像的质量和细节,使其在故事可视化任务中具有较高的应用价值。
使用方法
TBC-Bench数据集主要用于训练和评估故事可视化模型,特别是在多角色场景中的身份保持和语义对齐方面。研究者可以使用该数据集进行模型的训练和微调,以生成与文本描述高度一致的视觉故事。通过对比不同方法在该数据集上的表现,可以有效评估模型在角色身份保持、语义对齐和复杂场景生成等方面的性能。
背景与挑战
背景概述
TBC-Bench数据集由Netease Fuxi AI Lab和Xiamen University的Key Laboratory of Multimedia Trusted Perception and Efficient Computing联合开发,旨在解决故事可视化任务中的角色身份保持与文本语义对齐的挑战。该数据集基于Pororo和Frozen两个知名卡通系列构建,包含多个角色的详细图像和复杂场景,旨在为多角色故事可视化提供高质量的基准。TBC-Bench的提出不仅推动了故事可视化领域的发展,还为多角色生成任务提供了新的评估标准,展示了在角色身份保持和语义对齐方面的显著提升。
当前挑战
TBC-Bench数据集的构建面临两大主要挑战:一是如何在多角色场景中保持角色的身份一致性,避免角色混淆和身份丢失;二是如何确保生成的图像与文本描述的语义高度对齐,尤其是在复杂的场景和多角色互动中。此外,数据集的构建过程中还面临资源限制和样本多样性的挑战,如何在有限的资源下生成高质量的图像样本,并确保样本能够覆盖多角色的复杂互动,是该数据集面临的另一大挑战。
常用场景
经典使用场景
TBC-Bench数据集的经典使用场景主要集中在故事可视化任务中,特别是在多角色故事生成和角色身份定制方面。该数据集通过提供丰富的角色描述和场景信息,使得研究者能够训练模型在生成故事图像时保持角色的身份一致性和语义对齐。例如,通过TBC-Bench,研究者可以生成包含多个角色的复杂场景图像,确保每个角色在不同场景中的外观和行为保持一致,从而实现高质量的故事可视化。
解决学术问题
TBC-Bench数据集解决了现有故事可视化方法在角色身份保持和语义对齐方面的常见问题。传统方法在处理多角色场景时,往往难以保持角色的身份一致性,且生成的图像与文本描述的语义对齐度较低。TBC-Bench通过引入角色图(Character Graph)和知识增强的空间指导(Knowledge-Enhanced Spatial Guidance),显著提升了模型在多角色生成中的身份保持能力和语义对齐精度,为故事可视化领域的研究提供了新的基准和方法。
衍生相关工作
TBC-Bench数据集的提出催生了一系列相关研究工作,特别是在角色定制和多角色生成领域。例如,基于TBC-Bench的研究者提出了StoryWeaver模型,通过角色图和知识增强的空间指导,显著提升了多角色故事生成的质量和一致性。此外,TBC-Bench还启发了其他研究者在图像生成、语义对齐和角色身份保持方面的创新方法,推动了故事可视化领域的技术进步。
以上内容由遇见数据集搜集并总结生成


