Multi_Turn_RAG_with_Tools
收藏Hugging Face2025-05-05 更新2025-05-06 收录
下载链接:
https://huggingface.co/datasets/sprinklr-huggingface/Multi_Turn_RAG_with_Tools
下载链接
链接失效反馈官方服务:
资源简介:
Multi-Turn RAG with Tools是一个用于评估对话AI系统在商业环境中多轮对话的检索、生成和工具使用能力的数据集。它包含模拟对话,这些对话需要知识检索和工具选择,数据集分为两个子集,分别用于评估对话生成质量和工具选择准确性。
Multi-Turn RAG with Tools is a dataset designed to evaluate the retrieval, generation, and tool-use capabilities of conversational AI systems during multi-turn dialogues in business scenarios. It comprises simulated dialogues that require knowledge retrieval and tool selection. The dataset is divided into two subsets, which are respectively used to evaluate the quality of dialogue generation and the accuracy of tool selection.
创建时间:
2025-04-30
原始信息汇总
数据集概述:Multi-Turn RAG with Tools Benchmark
基本信息
- 名称: Multi Turn RAG with Tools
- 语言: 英语 (en)
- 许可证: CC BY-NC-4.0
- 规模: 1K<n<10K
- 任务类别: 文本生成、文本检索
- 标签: 联系中心 (contact-center)
数据集详情
- 创建者: Spinklr AI
- 内容: 包含两个主要评估任务的子集:
- 多轮RAG评估数据:
conversation_context: 对话上下文kb_ids: 相关知识库条目标识符correct_agent_response: 正确的代理响应
- 工具调用评估数据:
conversation_context: 对话上下文kb_ids: 相关知识库条目标识符true_tools: 应调用的工具列表tool_candidates<k>: 包含k个潜在工具名称的列表
- 多轮RAG评估数据:
用途
直接用途
- 评估多轮对话业务场景中的检索系统性能
- 评估RAG框架中的对话响应生成质量
- 评估对话代理在不同候选集大小下的工具选择准确性
- 开发和测试集成管道
超出范围用途
- 高风险应用
- 超出业务背景的领域
- 不涉及多轮对话、知识检索或工具使用的任务
- 评估工具的执行成功或输出
数据集创建
- 生成方法: 使用GPT-4o和Gemini-2.0-flash合成生成
- 过程: 两阶段生成,首先识别重要品牌实体,然后围绕这些实体模拟对话
基准测试与结果
- 评估指标:
- 检索性能 (Recall@k)
- 工具选择准确性
- 响应生成质量 (正确率、错误率、幻觉率、拒绝率)
偏差、风险与限制
- 内容限于合成生成的业务相关主题
- 仅使用"嘈杂"的知识库格式
- 可能继承生成模型的偏见
- 工具候选生成方法可能不同于其他选择方法
引用
bibtex @misc{spinklr2025multiturnragtools, title = {Multi-Turn RAG with Tools Benchmark}, author = {{Spinklr AI}}, year = {2025}, note = {Dataset synthetically generated using GPT-4o and Gemini-2.0-flash for evaluating multi-turn RAG and tool use, including response classification and tool selection against varying candidates. CC BY-NC-4.0.}, url = {https://huggingface.co/datasets/sprinklr-huggingface/Multi_Turn_RAG_with_Tools} }
术语表
- RAG: 检索增强生成
- 多轮对话: 涉及多次来回交换的对话
- 召回率: 成功检索到的相关KB ID的比例
- 工具调用: 根据对话上下文识别和选择适当的外部功能
- 工具候选: 呈现给模型的潜在工具列表
- 响应分类类别: 正确、错误、幻觉、拒绝
联系方式
如需更多信息,请联系Spinklr AI团队。
搜集汇总
数据集介绍
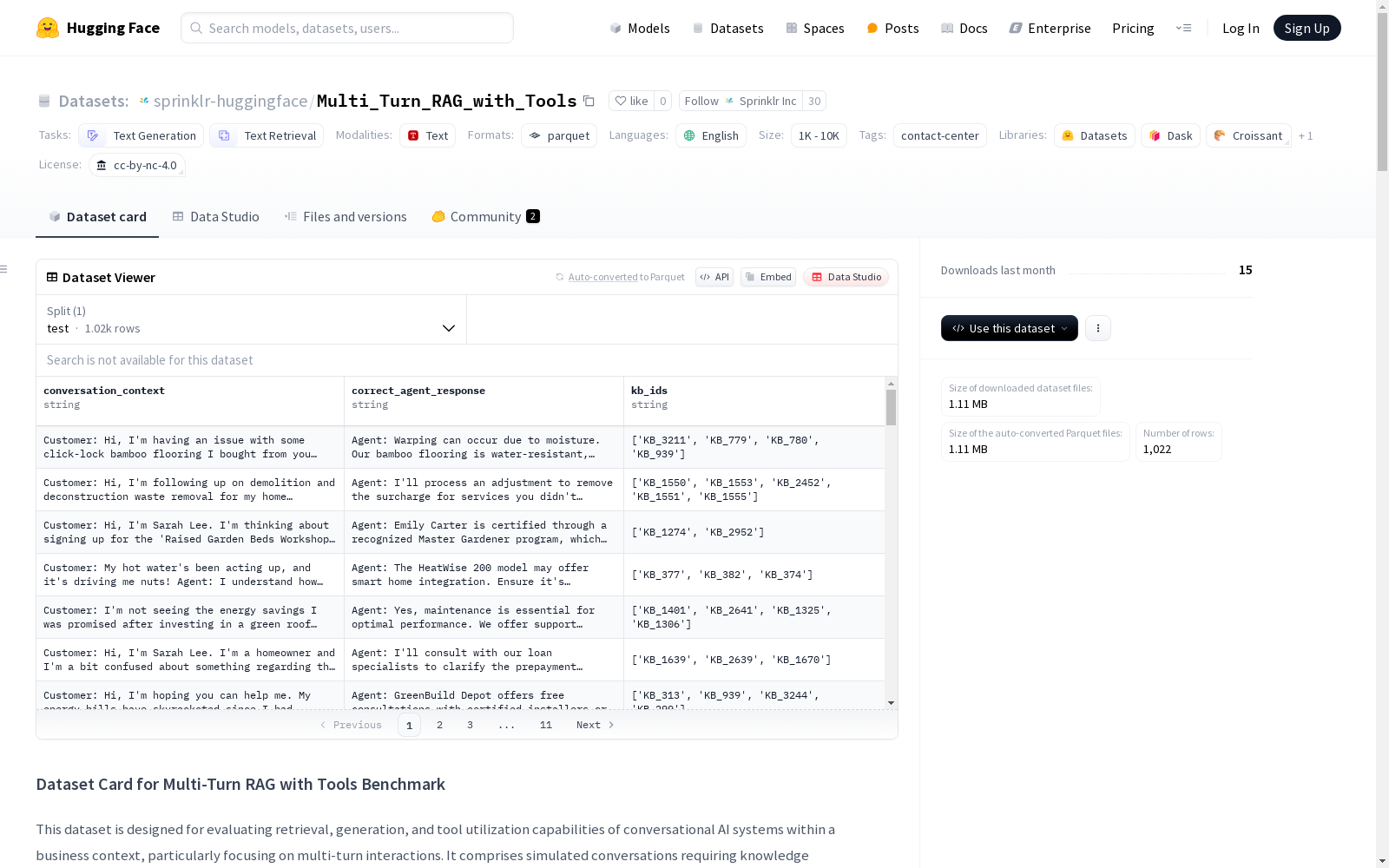
构建方式
该数据集采用两阶段合成生成方法,首先基于GPT-4o和Gemini-2.0-flash模型识别重要品牌实体并生成相关内容,随后围绕这些实体模拟多轮业务对话场景。知识库文章通过多种嵌入模型和分块配置建立索引,专门提供包含噪声的原始版本以增强现实性。工具调用子集则源自456个相关对话的分析,构建时确保真实工具包含在不同规模的候选工具集中。
特点
数据集突出多模态评估框架,包含对话上下文、真实知识库标识、标准代理响应等结构化字段,支持检索召回率、生成质量和工具选择准确性的三维度测评。独特之处在于提供16至128个动态工具候选集,模拟真实业务场景中的决策复杂度。响应分类体系引入正确、错误、幻觉和拒绝四类标准,为生成质量评估提供细粒度判断依据。
使用方法
使用时应区分RAG评估和工具调用评估两个子任务。前者需加载对话上下文和知识库标识进行检索召回测试,比对标准响应进行生成质量分类;后者需根据对话上下文从候选工具集中选择真实工具,支持不同规模候选集的准确率对比。建议配合提供的知识库定义文件,建立端到端评估管道时注意噪声知识库带来的现实挑战。
背景与挑战
背景概述
Multi_Turn_RAG_with_Tools数据集由Spinklr AI团队于2025年构建,旨在评估对话式AI系统在商业场景下的多轮交互能力。该数据集聚焦于检索增强生成(RAG)与工具调用的协同作用,通过模拟真实商业对话场景,为研究者提供了评估检索、生成及工具选择性能的标准化基准。数据集采用GPT-4o和Gemini-2.0-flash两阶段生成方法,首阶段构建品牌实体知识库,次阶段模拟围绕实体的多轮对话,其创新性在于首次将工具调用评估与多轮RAG任务有机结合,填补了复杂商业对话系统评估框架的空白。
当前挑战
该数据集面临的核心挑战体现在两个维度:在领域问题层面,多轮对话中知识检索的时序依赖性导致传统单轮RAG评估指标失效,需设计新型跨轮次一致性评价体系;工具调用任务中候选工具数量动态变化(16至128个)对模型抗干扰能力提出严峻考验。在构建层面,合成数据虽能保证规模,但对话逻辑的自然性与商业场景的真实性之间存在固有矛盾;知识库仅提供'噪声'版本的设计虽增强实用性,却为检索系统的鲁棒性评估引入变量控制难题。此外,响应分类标准(正确/错误/幻觉/拒绝)的严格定义可能与其他评估框架存在兼容性挑战。
常用场景
经典使用场景
在商业对话智能体领域,Multi_Turn_RAG_with_Tools数据集为评估多轮对话系统的综合能力提供了标准化测试平台。该数据集通过模拟真实商业场景中的多轮对话流程,重点考察智能体在知识检索、工具调用和响应生成三个关键维度的表现。研究者可利用其结构化对话上下文、真实知识库标识和工具候选集,系统性地测试不同检索增强生成模型在连续对话中保持语义一致性和工具选择准确性的能力。
实际应用
在实际商业场景中,该数据集支持构建高鲁棒性的智能客服系统。企业可基于其评估框架优化知识库检索策略,提升多轮对话中工具调用的精准度,例如在银行场景准确调用利率计算工具,或在电商场景触发订单查询接口。数据集模拟的噪声知识库环境特别有助于测试系统在非结构化数据条件下的稳定性,为实际部署前的压力测试提供重要参考。
衍生相关工作
该数据集已催生多个重要研究方向,包括动态工具选择算法优化、多模态知识检索增强框架,以及对话状态跟踪模型的改进。基于其构建的基准测试推动了大语言模型在工具调用准确率方面的突破,相关成果见于ACL、EMNLP等顶级会议。部分衍生工作进一步扩展了数据集的评估维度,开发了融合用户意图识别的端到端评估体系。
以上内容由遇见数据集搜集并总结生成


