what-breaks
收藏Hugging Face2026-05-28 更新2026-05-29 收录
下载链接:
https://huggingface.co/datasets/nlp-mark/what-breaks
下载链接
链接失效反馈官方服务:
资源简介:
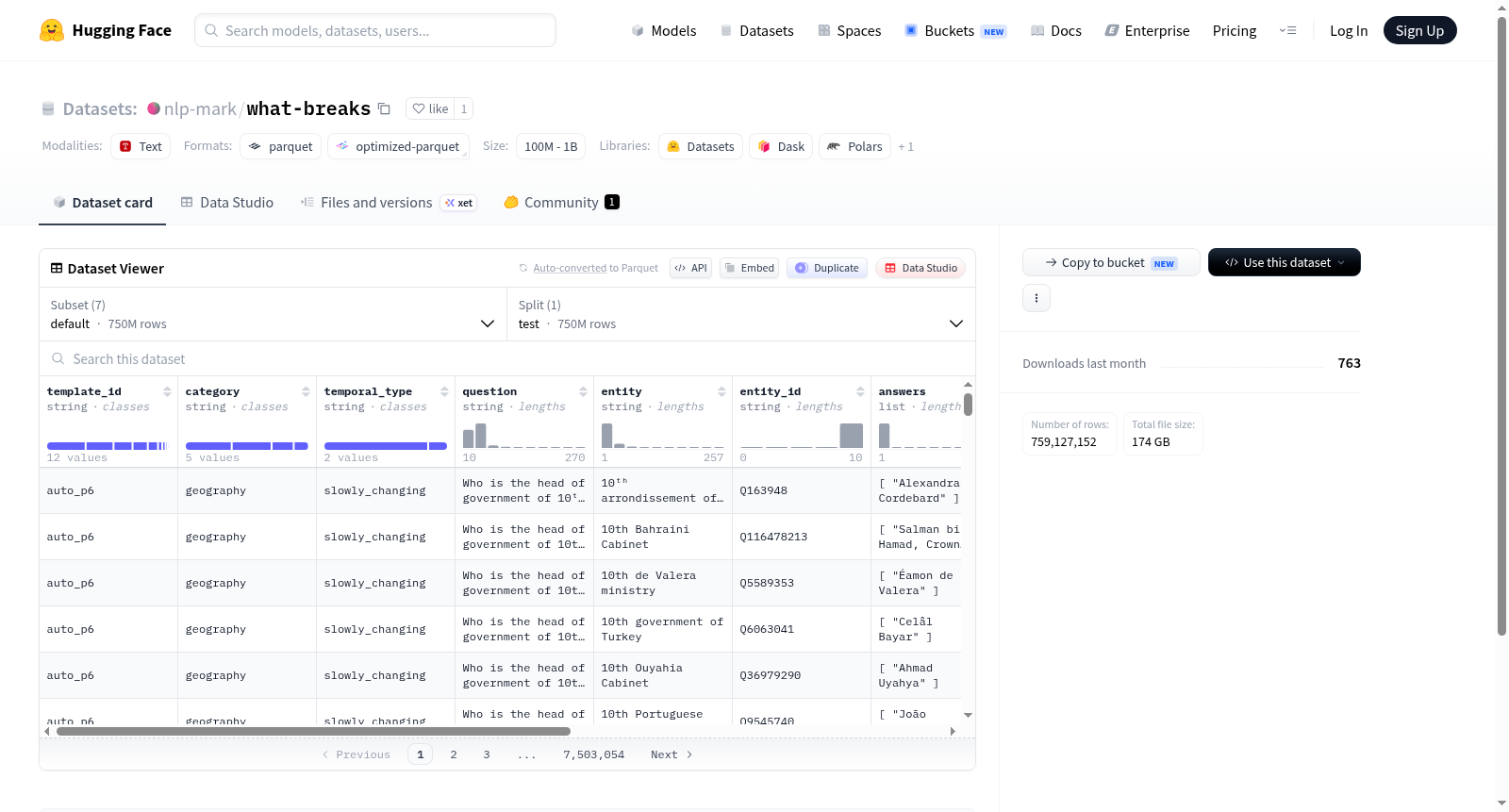
该数据集是一个大规模结构化问答数据集,提供多种规模配置,包括100K、250K、500K、1M、2M、5M及默认配置,所有配置均包含测试集,样本量从约9.3万到7.5亿不等。每个样本包含11个字段:模板ID(template_id)、问题类别(category)、时间类型(temporal_type)、自然语言问题(question)、实体名称(entity)、实体ID(entity_id)、答案列表(answers)、答案实体ID列表(answer_entity_ids)、类别解释(category_explanation)、时间解释(temporal_explanation)以及截断标志(truncated)。数据集设计适用于知识问答、实体链接、时间推理等自然语言处理任务,其结构化特征支持对问题类型、时间信息和实体关系的深入分析。
This dataset is a large-scale structured question-answering dataset, offering multiple size configurations including 100K, 250K, 500K, 1M, 2M, 5M, and a default configuration. All configurations include test sets, with sample sizes ranging from approximately 93,000 to 750 million. Each sample contains 11 fields: template ID (template_id), question category (category), temporal type (temporal_type), natural language question (question), entity name (entity), entity ID (entity_id), answer list (answers), answer entity ID list (answer_entity_ids), category explanation (category_explanation), temporal explanation (temporal_explanation), and truncation flag (truncated). The dataset is designed for natural language processing tasks such as knowledge question answering, entity linking, and temporal reasoning, with its structured features supporting in-depth analysis of question types, temporal information, and entity relationships.
创建时间:
2026-05-18
原始信息汇总
数据集名称
What Breaks
数据集地址
https://huggingface.co/datasets/nlp-mark/what-breaks
数据集概览
该数据集包含多个配置(config),每个配置对应不同规模的子集,所有配置的数据集特征结构一致。数据集仅包含 test 拆分的样本,没有 train 或 validation 拆分。
特征字段
每个样本包含以下字段:
- template_id(字符串):模板ID。
- category(字符串):类别。
- temporal_type(字符串):时间类型。
- question(字符串):问题内容。
- entity(字符串):实体名称。
- entity_id(字符串):实体ID。
- answers(字符串列表):答案列表。
- answer_entity_ids(字符串列表):答案对应的实体ID列表。
- category_explanation(字符串):类别解释。
- temporal_explanation(字符串):时间解释。
- truncated(布尔值):是否被截断。
配置与规模
| 配置名称 | 数据集大小(字节) | 下载大小(字节) | 样本数 |
|---|---|---|---|
| 100K | 124,728,886 | 93,446,584 | 93,348 |
| 250K | 261,999,341 | 176,108,410 | 251,686 |
| 500K | 432,210,144 | 274,191,320 | 461,365 |
| 1M | 1,038,433,361 | 602,440,758 | 1,266,596 |
| 2M | 1,697,426,517 | 931,888,950 | 2,218,676 |
| 5M | 3,197,211,915 | 1,627,610,922 | 4,530,110 |
| default | 481,603,053,422 | 170,559,310,170 | 750,305,371 |
数据文件
每个配置对应的数据文件路径如下:
- 100K:
100K/train-* - 1M:
1M/train-* - 250K:
250K/train-* - 2M:
2M/train-* - 500K:
500K/train-* - 5M:
5M/train-* - default:
data/train-*
搜集汇总
数据集介绍
构建方式
What-Breaks数据集是一个面向知识图谱问答任务的测试基准,由WikiWeb2M知识库衍生而来。该数据集采用基于模板的自动生成策略,通过预定义的问句模板与知识图谱中的实体、关系进行匹配,构造出覆盖多类别多时间维度的问题。每个样本包含模板标识符、问题类型(category)、时间语义类型(temporal_type)、问题文本、关联实体及编号、标准答案集合及对应实体编号,并辅以类别与时间维度的解释说明。数据集提供从100K到5M共六个不同规模的子配置,以及一个包含数亿样本的默认完整版本,满足不同场景下模型评测的需求。
特点
该数据集最显著的特点在于其结构化的标注设计与大规模的多层级划分。每个样本都明确标注了问题所属的类别(如属性查询、关系推理等)和时间语义类型(如过去、现在、未来),使研究者能够拆解模型在不同类型问题上的表现。数据集中所有问题均基于知识图谱中的真实实体生成,且答案以标准化字符串列表存储,便于评估。此外,数据集提供的默认配置包含约7.5亿个样本,是当前规模最大的知识图谱问答测试集之一,适合开展大规模鲁棒性分析。
使用方法
使用该数据集时,可通过HuggingFace的datasets库按需加载指定配置。例如,调用load_dataset('what-breaks', '100K')即可获取10万规模的测试集。每个样本以字典形式返回,包含模板ID、问题文本、答案列表等字段。研究者可基于'category'字段筛选特定类型的问题,或利用'temporal_type'字段分析模型在处理时间敏感推理时的表现。由于所有配置均为test拆分,该数据集专为模型的零样本评估设计,无需额外划分训练集。
背景与挑战
背景概述
知识图谱的符号化表示在自然语言处理中占据核心地位,然而其静态特质使得模型难以捕捉实体与关系随时间流转的动态演化。针对这一局限,‘what-breaks’数据集由研究团队于2023年前后构建,旨在系统性地评估大语言模型在面对时序性知识变化时的鲁棒性与推理能力。该数据集以Wikidata为底库,通过引入时间常识的扰动,生成涵盖多种类别的时间敏感问题,为探索语言模型在处理知识演变时的失效模式提供了标准化的评测框架。其多配置设计(从100K到5M)适应不同规模的计算资源,有力推动了时序知识理解与模型脆弱性分析等前沿方向的研究发展。
当前挑战
该数据集所解决的领域挑战在于大语言模型对时序知识动态的理解匮乏,传统静态评测无法揭示模型在知识更新或过时条件下的表现退化。具体而言,模型常因预训练语料的时间截断而无法正确回答涉及实体状态变更、关系消亡或属性互换的问题。在构建过程中,挑战则体现为从海量结构化知识图谱中精准筛选并生成合理的时序对立样本,需要保证问题在语义上自然流畅且答案存在明确时间维度的正误差异。此外,如何通过类别分类与时间类型标注来涵盖丰富的知识变化模式,同时维持各配置版本间的样本平衡与分布一致性,也是确保评测全面性与有效性的关键难题。
常用场景
经典使用场景
What-Breaks数据集是自然语言处理领域用于评估语言模型在多轮对话或知识密集型任务中推理能力退化的基准资源。其设计聚焦于探究模型在面对干扰信息、时间冲突或实体混淆时,能否保持稳定的理解和回答质量。研究者常利用该数据集的不同规模版本(如100K至5M)进行模型鲁棒性的系统性测试,通过分析模型在模板化问题上的表现,揭示其在复杂语境下的脆弱环节。数据集的核心特征包括类别标签、时间类型、问题模板及多候选答案,为深入剖析模型行为提供了结构化分析框架,成为检验对话系统和问答模型可靠性的重要工具。
实际应用
在实际应用层面,数据集支撑了智能客服、虚拟助手和知识问答系统的可靠性验证与优化。例如,在金融咨询或医疗问诊场景中,系统需处理用户穿插的更正信息或时间敏感的条款变更,What-Breaks模拟的这些复杂对话模式可直接用于测试生产环境下的模型退化现象。开发者借助不同规模的数据子集,从轻量级模型到超大规模语言模型进行压力测试,识别出在实体跟踪、时序推理上的具体瓶颈。这些洞见转化为对抗训练方案或注意力机制改进,切实增强了商业系统在真实互动中的鲁棒性,减少了因信息冲突导致的错误响应。
衍生相关工作
基于What-Breaks的研究范式,衍生出一系列关于语言模型鲁棒性和长程一致性评估的经典工作。例如,有学者借鉴其模板化对抗样例设计思路,构建了跨领域鲁棒性测试集,探讨模型在不同知识图谱间的迁移表现。另一方向的研究利用该数据集的类别和时间标注,开发了专门针对时间推理能力增强的训练策略,如时间感知的掩码语言建模。此外,该数据集催生了若干关于模型解释性的工作,通过分析模板ID和类别解释字段,定位导致模型出错的特定神经元或注意力头。这些衍生贡献共同丰富了语言模型脆弱性诊断的理论工具箱,形成了一个持续进化的评估生态。
以上内容由遇见数据集搜集并总结生成


