baltivoice-asr
收藏Hugging Face2026-05-30 更新2026-05-31 收录
下载链接:
https://huggingface.co/datasets/mohdali1/baltivoice-asr
下载链接
链接失效反馈官方服务:
资源简介:
BaltiVoice ASR数据集是首个公开可用的巴蒂语自动语音识别数据集,专门针对低资源的巴蒂语(ISO 639-3代码:bft,一种藏缅语族濒危语言)开发。巴蒂语主要在巴基斯坦吉尔吉特-巴尔蒂斯坦地区和印度拉达克地区使用,使用人数约40万至50万。该数据集旨在通过微调OpenAI Whisper模型,构建首个开源巴蒂语ASR系统。它包含总计10,060个音频-文本对,其中训练集9,051个样本,验证集1,006个样本,总时长约16.8小时。音频为16kHz单声道WAV格式,平均时长约6秒。每个样本包含两个字段:audio(音频数组)和sentence(使用Nastaliq阿拉伯文字书写的巴蒂语转写文本)。数据来源于Mozilla Common Voice巴蒂语贡献项目,经过质量验证和转写准确性处理,并按90/10比例随机划分。该数据集适用于低资源语言的自动语音识别任务研究,支持巴蒂语数字保存和语音技术开发,并为未来巴蒂语的文本转语音、命名实体识别和机器翻译系统提供基础。数据收集存在局限性,如录音质量差异、词汇范围可能局限于常用对话领域,以及模型训练时使用乌尔都语分词器作为Nastaliq文字的代理。数据集采用CC-BY-4.0许可证发布。
The BaltiVoice ASR dataset is the first publicly available automatic speech recognition dataset for the Balti language (ISO 639-3 code: bft), specifically developed for this low-resource Tibeto-Burman language. Balti is primarily spoken in the Gilgit-Baltistan region of Pakistan and the Ladakh region of India, with approximately 400,000 to 500,000 speakers, and is considered an endangered language by linguists, with extremely scarce digital resources. The dataset aims to build the first open-source Balti ASR system by fine-tuning the OpenAI Whisper model. It contains a total of 10,060 audio-text pairs, with 9,051 samples in the training set and 1,006 samples in the validation set, totaling approximately 16.8 hours of audio. The audio is in 16kHz mono WAV format, with an average duration of about 6 seconds. Each sample includes two fields: audio (an audio array at 16kHz sampling rate) and sentence (a transcribed text in Balti written in Nastaliq Arabic script). The data is sourced from the Mozilla Common Voice Balti contribution project, having undergone quality verification and transcription accuracy processing, and is randomly split into training and validation sets in a 90/10 ratio. The dataset is suitable for research on automatic speech recognition tasks for low-resource languages, supporting digital preservation of Balti and speech technology development, and providing a foundation for future Balti text-to-speech, named entity recognition, and machine translation systems. There are limitations in data collection, including variations in volunteer recording quality, potential vocabulary limitations to common conversational domains, and the use of an Urdu tokenizer as a proxy for Nastaliq script during model training. The dataset is released under the CC-BY-4.0 license.
创建时间:
2026-05-28
原始信息汇总
BaltiVoice ASR Dataset 概述
数据集简介
- 名称: BaltiVoice ASR Dataset
- 用途: 自动语音识别(ASR)
- 语言: Balti(ISO 639-3: bft),一种极度低资源的藏语支语言,主要使用于巴基斯坦的吉尔吉特-巴尔蒂斯坦地区和印度的拉达克地区
- 资源水平: 极度低资源,是首批公开可用的巴尔蒂语 ASR 数据集之一
语言属性
| 属性 | 详情 |
|---|---|
| 语言 | Balti (بلتی) |
| ISO 代码 | bft |
| 语系 | 汉藏语系 → 藏缅语族 → 藏语支 |
| 文字 | Nastaliq(基于阿拉伯字母) |
| 地区 | 巴基斯坦吉尔吉特-巴尔蒂斯坦;印度拉达克 |
| 使用人口 | 约 40万–50万(估算) |
数据集统计
| 子集 | 样本数 | 时长(估计) |
|---|---|---|
| 训练集 | 9,051 | ~15.1 小时 |
| 验证集 | 1,006 | ~1.7 小时 |
| 总计 | 10,060 | ~16.8 小时 |
音频与文本属性
- 音频属性:
- 格式: WAV(16kHz,单声道)
- 平均时长: ~6.0 秒
- 最小时长: ~1.0 秒
- 最大时长: ~15.0 秒
- 采样率: 16,000 Hz
- 文本属性:
- 平均每句词数: 10.12
- 平均每句字符数: 48.80
- 文字: Nastaliq(从右到左书写)
数据结构
每个样本包含两个字段:
audio: 16kHz 单声道 WAV 音频数组及其采样率sentence: 巴尔蒂语转写文本(Nastaliq 文字)
数据来源与收集
- 基础数据来自 Mozilla Common Voice 巴尔蒂语(bft)贡献项目
- 音频片段经过质量验证和转写准确性校验
- 为 HuggingFace 兼容的 ASR 训练进行加工和结构化
- 按 90/10 比例(随机种子 42)划分为训练集和验证集
使用示例
python from datasets import load_dataset, Audio
dataset = load_dataset("mohdali1/baltivoice-asr") dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
相关模型
基于该数据集微调的 Whisper 模型已发布:
社会影响
- 为濒危的巴尔蒂语提供数字化保存
- 为巴尔蒂语使用者提供语音技术支持
- 促进低资源藏语支语言的 NLP 研究
- 为未来巴尔蒂语的 TTS、NER 和机器翻译系统提供基础
局限性
- 音频来自志愿者贡献,录音质量存在差异
- 词汇可能局限于常见会话领域
- 模型使用乌尔都语的分词器作为代理(Whisper 支持的与 Nastaliq 文字最接近的选项)
- 词错误率(WER)指标基于 Whisper 的乌尔都语分词,而非原生巴尔蒂语分词器
许可协议
搜集汇总
数据集介绍
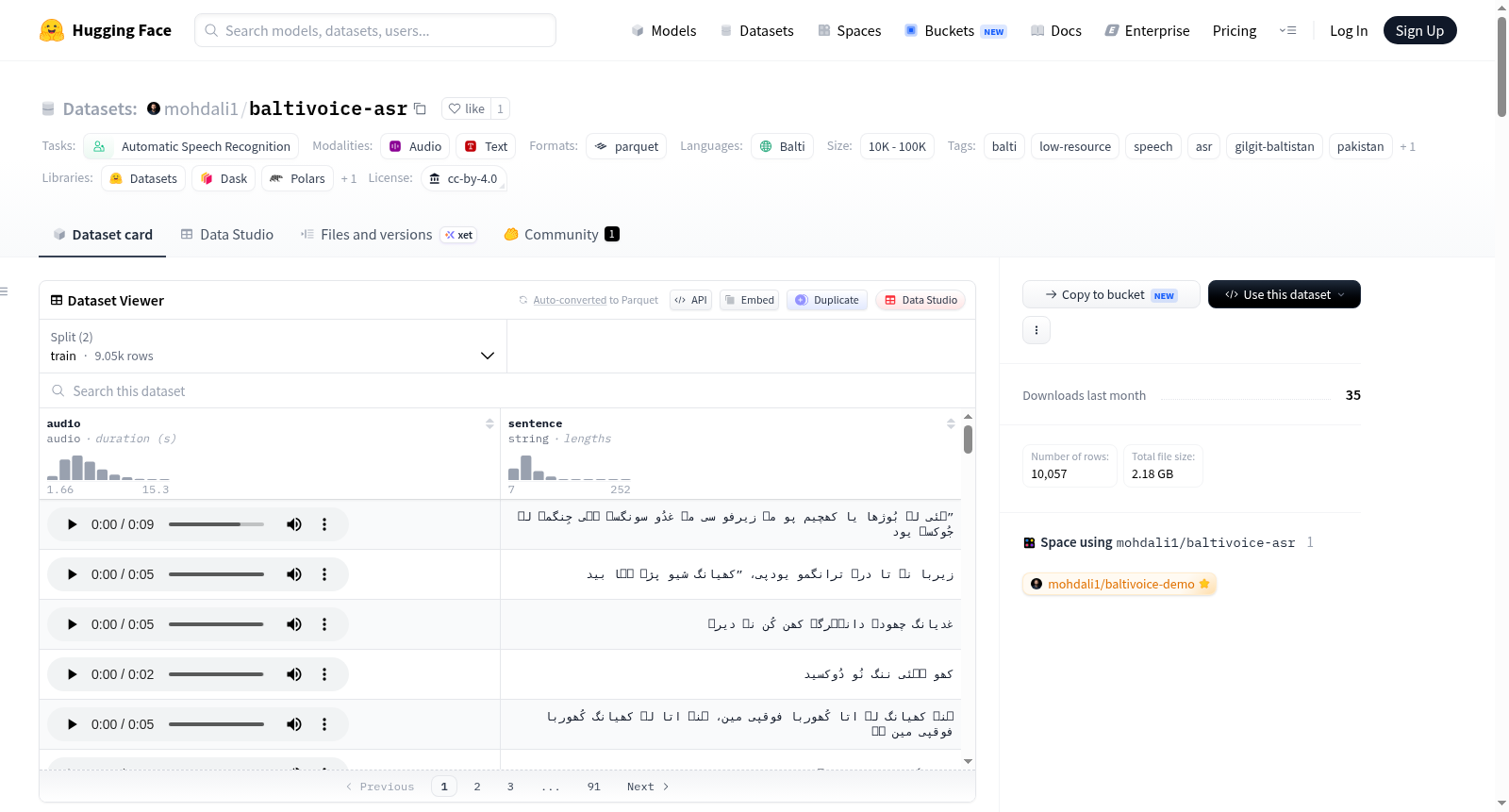
构建方式
BaltiVoice ASR数据集是首个公开的巴尔蒂语音识别数据集,巴尔蒂语(ISO 639-3: bft)是一种极度低资源的藏缅语系语言,主要使用于巴基斯坦吉尔吉特-巴尔蒂斯坦地区和印度拉达克地区,被语言学家视为濒危语言。该数据集的数据源于Mozilla Common Voice的巴尔蒂语贡献项目,经过严格的质量验证和转录准确性审核后,进行结构化处理并适配HuggingFace格式。数据集以随机种子42进行90/10的划分,构建了训练集(9051条)和验证集(1006条),总计约16.8小时的语音数据。
使用方法
用户可通过HuggingFace的datasets库直接加载数据集,使用load_dataset('mohdali1/baltivoice-asr')命令获取,并通过cast_column方法将音频列转换为16kHz采样率格式。数据集以字典结构存储,每个样本包含音频数组和对应的巴尔蒂语转录文本。基于此数据集微调的Whisper模型(mohdali1/whisper-small-balti)已开源,用户可利用transformers库快速构建语音识别流水线,将巴尔蒂语音频输入后直接输出转录文本。
背景与挑战
背景概述
BaltiVoice ASR数据集由Mohammad Ali于2025年创建,旨在填补巴尔蒂语(Balti,ISO 639-3: bft)在自动语音识别领域的空白。巴尔蒂语是一种藏缅语族语言,主要使用于巴基斯坦吉尔吉特-巴尔蒂斯坦地区及印度拉达克,拥有约40至50万使用者,但被语言学家列为濒危语言,缺乏数字资源和自然语言处理工具。该数据集基于Mozilla Common Voice的巴尔蒂语贡献项目,经过质量验证与结构化处理,构建了首个公开的巴尔蒂语ASR数据集,包含约1万条音频-文本对,总时长约16.8小时,并成功用于微调OpenAI Whisper模型,为低资源藏缅语族的语音技术研究提供了基础性资源。
当前挑战
该数据集面临的核心挑战首先在于领域问题的复杂性:巴尔蒂语作为极度低资源语言,缺乏标准化的语音转写工具和语言模型,声音数据的采集依赖于志愿者贡献,导致录音质量参差不齐、词汇范围局限于日常对话,且无法直接适配主流ASR系统的分词器——研究团队不得不使用乌尔都语分词器作为代理,这会在词错误率评估中引入偏差。其次,构建过程中遇到严峻挑战:需要从零开始收集、验证和标注语音数据,处理阿拉伯-based纳斯塔里克文字从右到左书写带来的排版和编码问题,且有限的使用者数量限制了数据规模的扩展,最终仅获得约16.8小时的可用于训练的音频,远低于主流ASR数据集所需的数百小时。
常用场景
经典使用场景
BaltiVoice ASR数据集作为巴尔蒂语首个公开的自动语音识别资源,主要用于训练和评估低资源藏缅语族的端到端语音识别模型。研究者可基于该数据集微调Whisper等预训练模型,实现从巴尔蒂语音频到纳斯塔里克文字转录的映射。数据集包含约16.8小时、逾万条短语音片段,平均时长6秒,覆盖日常会话领域,为构建小语种语音助手、语音搜索等基础应用提供了关键训练语料。
解决学术问题
该数据集填补了巴尔蒂语在计算语言学领域的资源空白,解决了低资源藏缅语族语言缺乏标准化语音-文本对齐数据的学术困境。它为验证跨语言迁移学习在濒危语言上的有效性提供了基准,帮助研究者探索基于乌尔都语tokenizer的代理分词策略对巴尔蒂语识别性能的影响。数据集的出现使得定量评估Whisper等大模型在真正低资源场景下的泛化能力成为可能,推动了非主流语言文字的语音技术研究。
实际应用
在实际应用中,该数据集支撑的语音识别模型可集成至移动应用,为吉尔吉特-巴尔蒂斯坦地区约40万母语者提供语音转文字服务,辅助教育场景中的巴尔蒂语学习与教材数字化。语音接口可帮助老年群体和低识字率人群通过语音指令操作智能设备,亦可用于文化遗产保护中方言口述史的自动转写。此外,该技术为地方政府开发本地语言紧急呼叫系统和政务服务语音导航提供了技术基石。
数据集最近研究
最新研究方向
当前,巴尔蒂语作为极度濒危的藏缅语支语言,其数字资源匮乏,语音技术几乎空白。BaltiVoice数据集的诞生为低资源语言自动语音识别(ASR)研究开辟了新路径。该数据集不仅提供了首批公开的巴尔蒂语语音-文本对(约1.1万条、16.8小时),更结合OpenAI Whisper微调技术,成功构建了首个可用的巴尔蒂语ASR系统。这一工作呼应了全球对语言多样性与技术普惠性的关注,尤其是在吉尔吉特-巴尔蒂斯坦等高原地区的语言数字化保护浪潮中。研究者可通过该基准探索跨脚本(Nastaliq)迁移学习、轻量化模型适配等前沿议题,其意义不仅在于填补珠峰西麓的语言资源空白,更为希伯来语、藏语等相近语系的语言工程提供了可复用的范式——依托少量高质量数据实现从零到一的语音技术突破,有望推动低资源语言在智能语音助手、教育工具及文化遗产保存等场景中的实际应用。
以上内容由遇见数据集搜集并总结生成


