StarCloud
收藏Hugging Face2025-04-21 更新2025-04-22 收录
下载链接:
https://huggingface.co/datasets/rubenroy/StarCloud
下载链接
链接失效反馈官方服务:
资源简介:
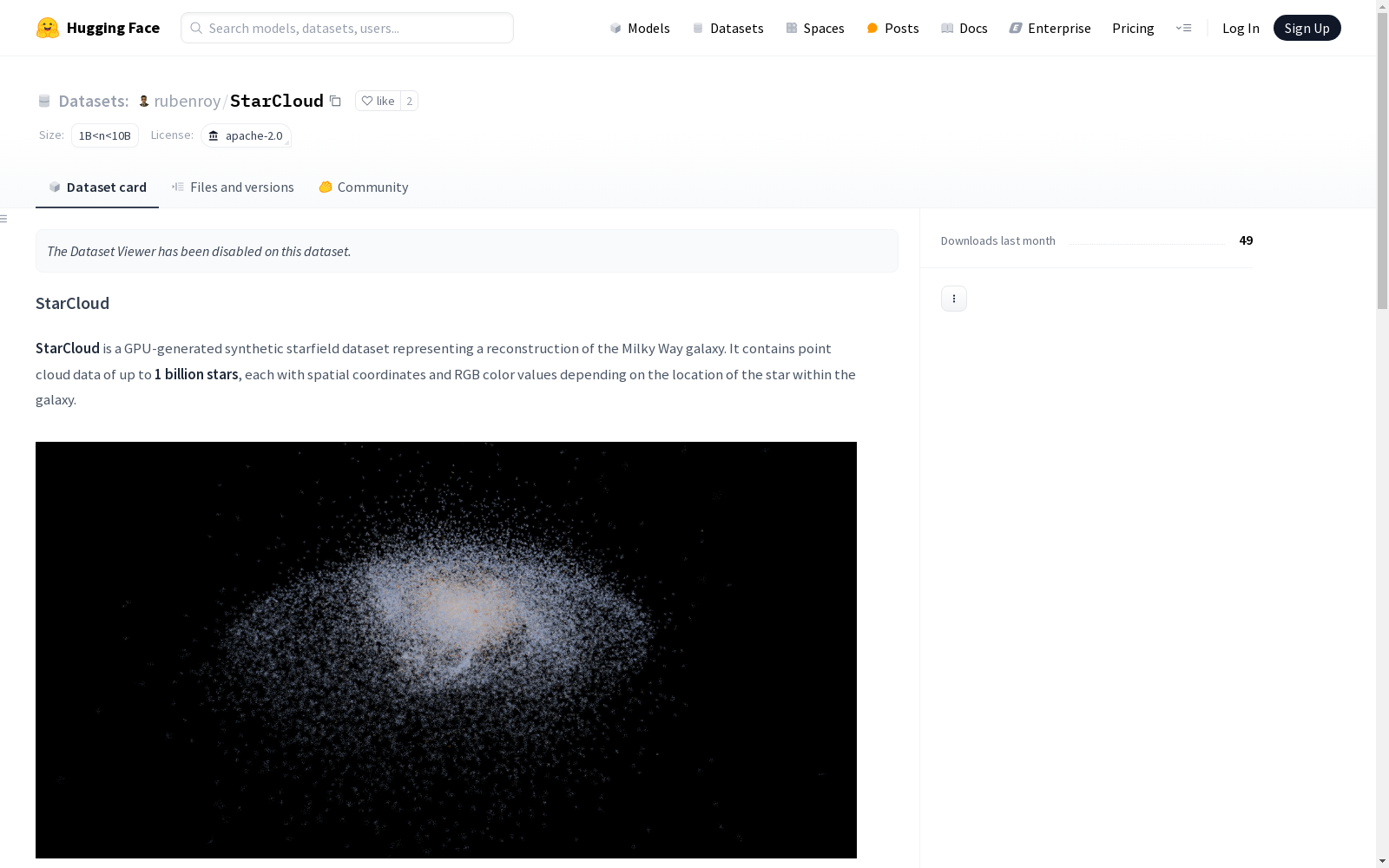
StarCloud是一个由GPU生成的合成星场数据集,代表了对银河系的重建。它包含了多达10亿颗星星的点云数据,每颗星星具有根据其在银河中位置的空间坐标和RGB颜色值。
创建时间:
2025-04-20
搜集汇总
数据集介绍
构建方式
在计算天文学领域,StarCloud数据集通过高性能GPU技术实现了银河系恒星分布的数字化重构。该数据集采用NVIDIA A100 40GB显卡进行并行计算,历时两小时生成包含10K至1B恒星点的多尺度点云数据。每个数据点以PLY格式存储,包含三维空间坐标(x,y,z)和基于银河系位置生成的RGB色彩值(r,g,b),所有数据均为程序化合成,未使用实际观测数据。
特点
作为目前最大规模的合成星场数据集,StarCloud的突出特点体现在其多分辨率层级结构。数据集提供从万级到十亿级恒星点的六个精度版本,单个文件大小跨越400KB至38.2GB的广泛区间。每个恒星点包含精确的浮点型空间坐标和8位色彩编码,这种结构化设计既支持科研级的天体动力学分析,也能满足计算机图形学的渲染需求。数据集的合成特性规避了真实天文数据常见的噪声干扰问题。
使用方法
该数据集支持主流的点云处理技术栈,用户可通过Pandas库直接读取PLY文件进行数据分析,或借助Open3D框架实现三维可视化。在Python生态中,数据加载仅需简单调用read_csv或read_point_cloud接口,其标准化字段命名(x/y/z/r/g/b)确保了与现有处理流程的无缝对接。对于超大规模数据文件,建议采用分布式计算框架进行并行处理以优化内存使用效率。
背景与挑战
背景概述
StarCloud数据集由Ruben Roy创建,是一项基于GPU生成的合成星场数据,旨在模拟银河系的点云结构。该数据集包含多达10亿颗恒星的空间坐标和RGB颜色值,为天文学和计算机图形学领域提供了宝贵的研究资源。通过利用NVIDIA A100 40GB GPU的强大计算能力,数据集在短短两小时内完成了所有文件的生成,展现了高效的计算性能。StarCloud的发布不仅填补了大规模合成星场数据的空白,还为相关领域的算法开发和可视化研究提供了重要支持。
当前挑战
StarCloud数据集在解决银河系点云建模问题时,面临着数据规模庞大带来的存储和处理挑战。构建过程中,生成高达10亿颗恒星的合成数据需要克服计算资源的限制,确保数据生成的效率和准确性。此外,点云数据的可视化与分析也对算法和工具提出了较高要求,如何在保证数据质量的同时优化处理流程成为关键问题。
常用场景
经典使用场景
在宇宙学与计算机图形学的交叉领域,StarCloud数据集为研究者提供了一个高度逼真的银河系三维点云模型。该数据集通过GPU生成的合成星场数据,精确模拟了银河系中多达10亿颗恒星的空间分布与色彩特征,成为测试点云处理算法和可视化技术的理想基准。其多尺度数据文件从1万到10亿点不等,能够满足不同计算规模的研究需求,特别适合用于评估点云压缩、渲染优化和空间索引算法的性能。
实际应用
该数据集在虚拟天文馆开发、航天任务模拟器等工程领域展现重要价值。教育机构可利用其不同规模的数据版本开发交互式天文教学系统,而航天工业则将其用于飞行器导航算法的星图匹配测试。游戏引擎开发者借助该数据集构建逼真的太空场景,其PLY格式数据可直接接入主流三维渲染管线,显著降低宇宙环境建模的时间成本。
衍生相关工作
基于StarCloud数据集已产生多项创新研究,包括《GPU加速的星系点云实时渲染系统》等代表性成果。研究者开发了基于八叉树的空间索引方法以高效处理十亿级星体数据,另有团队利用其色彩信息建立了恒星光谱分类的深度学习模型。该数据集还促进了天文与计算机视觉领域的合作,衍生出《基于生成对抗网络的银河系结构模拟》等跨学科研究。
以上内容由遇见数据集搜集并总结生成


