Genome-Bench
收藏arXiv2025-05-26 更新2025-05-28 收录
下载链接:
https://huggingface.co/datasets/Mingyin0312/Genome-Bench
下载链接
链接失效反馈官方服务:
资源简介:
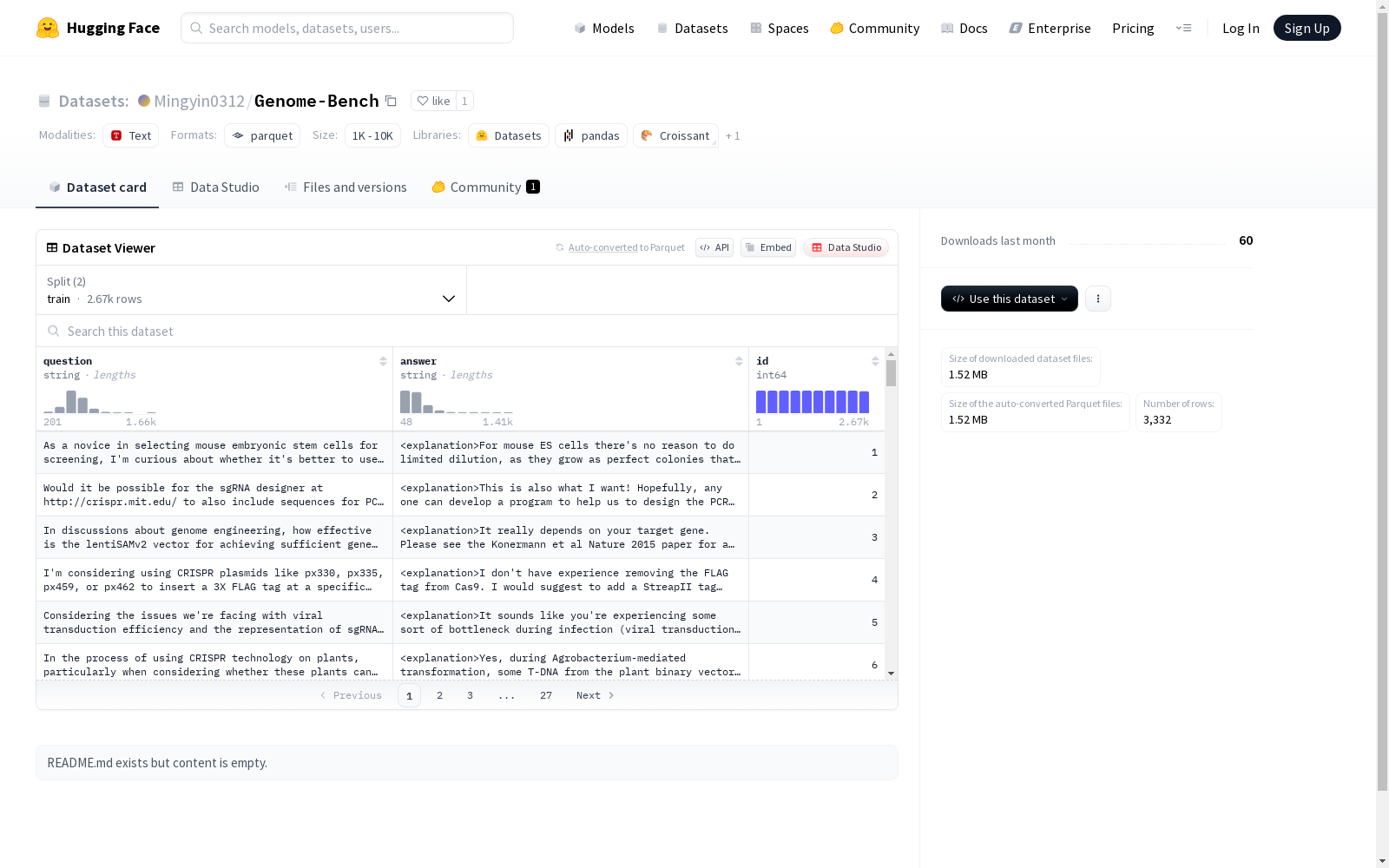
Genome-Bench是一个由真实专家讨论构建的科学推理基准数据集,涵盖基因编辑领域,包括超过十年的CRISPR论坛讨论。数据集包含3332个精心策划的多项选择题,涉及基础生物学、实验故障排除、工具使用等多个方面。Genome-Bench数据集反映了实际实验生物学的复杂性和不确定性,为大型语言模型提供了真实的测试环境。
Genome-Bench is a scientific reasoning benchmark dataset constructed from real expert discussions, covering the field of gene editing and including over a decade of CRISPR forum discussions. The dataset contains 3,332 carefully curated multiple-choice questions spanning multiple aspects such as basic biology, experimental troubleshooting, and tool usage. The Genome-Bench dataset reflects the complexity and uncertainty of real-world experimental biology, providing a realistic test environment for large language models (LLMs).
提供机构:
普林斯顿大学, 斯坦福大学, 加州大学伯克利分校
创建时间:
2025-05-26
搜集汇总
数据集介绍
构建方式
在基因组学研究领域,科学讨论的复杂性和专业性对语言模型的推理能力提出了严峻挑战。Genome-Bench采用自动化流程,从长达十年的CRISPR论坛讨论中提取原始数据,通过定制解析器和GPT-4 Turbo模型将邮件线程转化为结构化的问题-答案-上下文三元组。随后利用大语言模型生成具有科学可信度的干扰选项,经过严格的去重和质量过滤,最终形成包含3,332个高质量多选题的基准数据集,完整保留了真实科学讨论中的实验约束和方法论考量。
特点
该数据集最显著的特点在于其真实性和专业性,所有问题均源自基因组编辑实践者的实际讨论,涵盖了验证、故障排除、克隆构建等七个关键主题。不同于人工合成的测试集,Genome-Bench完整保留了科学探索过程中的模糊性和复杂性,包括常见误解和实验优化轨迹。每个问题均标注难度等级和主题分类,并附有专家提供的详细解释,为评估语言模型在专业领域的推理能力提供了多维度的分析框架。
使用方法
研究人员可通过标准化格式直接使用该数据集进行监督微调或强化学习,每个样本包含完整的问题描述、随机排序的选项以及带标签的正确答案。评估时需遵循特定协议,要求模型在<explanation>标签内生成推理过程,并在<answer>标签中输出最终选项。数据集按4:1比例划分为训练集和测试集,支持对模型在基础生物学、实验方案设计等细分领域的性能进行分层评估,特别适合检验语言模型处理专业歧义和复杂实验场景的能力。
背景与挑战
背景概述
Genome-Bench是由普林斯顿大学、斯坦福大学和加州大学伯克利分校的研究团队于2025年推出的基因组学科学推理基准数据集。该数据集基于CRISPR基因编辑技术领域长达十年的科学论坛讨论构建,包含3,332个高质量的多选题问答对,涵盖基础生物学、实验故障排除、工具使用等多个子领域。作为首个从真实专家对话中构建的LLM基准,Genome-Bench独特地捕捉了实验生物学中的复杂推理过程,包括假设提出、结果解释和协议优化等真实科研场景。其数据源来自Broad研究所2013-2023年的公开邮件列表,反映了CRISPR技术发展历程中的关键讨论与突破。
当前挑战
Genome-Bench面临的核心挑战体现在两个维度:领域问题方面,需解决LLMs在基因组学等专业领域存在的专家级科学推理能力不足问题,包括处理实验模糊性、整合跨抽象层次知识等;构建过程方面,需克服原始论坛数据的非结构化特性,通过自动化流程实现从嘈杂的邮件讨论到标准化多选题的转化,包括保持问题上下文完整性、生成科学可信的干扰项,以及确保3,000+问答对的质量控制。特别需要处理论坛讨论中常见的开放式问题、不完整答案和领域特定术语等复杂情况。
常用场景
经典使用场景
Genome-Bench数据集在基因组学领域的研究中具有广泛的应用价值,尤其在CRISPR基因编辑技术的实验设计和优化方面。该数据集通过提取真实科学论坛讨论中的高质量问答对,为研究人员提供了一个模拟真实实验环境的测试平台。经典使用场景包括基因编辑实验的故障排除、试剂选择、实验协议设计等,这些问题直接反映了科学家在实际工作中遇到的挑战和解决方案。
实际应用
在实际应用中,Genome-Bench可直接支持基因编辑实验室的工作流程。研究人员可利用该数据集训练AI助手,帮助解决实验设计中的常见问题,如CRISPR-Cas9系统的优化、基因敲除效率的提升等。此外,该数据集还可用于开发智能问答系统,为实验室新手提供实时指导,减少实验失败率并提高研究效率。
衍生相关工作
基于Genome-Bench的衍生工作主要集中在两个方向:一是开发专门针对基因组学领域的语言模型,如CRISPR-specific LLMs;二是构建更广泛的科学推理基准测试框架。相关经典工作包括Lab-Bench在生物学研究任务评估上的扩展应用,以及BioASQ挑战赛在生物医学问答系统上的持续优化。这些工作都在不同程度上借鉴了Genome-Bench的数据构建方法和领域专业知识。
以上内容由遇见数据集搜集并总结生成


