LEGAL-UQA
收藏arXiv2024-10-17 更新2024-10-19 收录
下载链接:
https://huggingface.co/datasets/nlp-anonymous-researcher/LEGAL-UQA
下载链接
链接失效反馈官方服务:
资源简介:
LEGAL-UQA是由拉合尔管理科学大学的研究人员创建的第一个乌尔都语法律问答数据集,源自巴基斯坦宪法。该数据集包含619个问答对,每个问答对都有相应的法律文章背景,旨在支持低资源语言的领域特定NLP资源需求。数据集的创建过程包括OCR提取、手动精炼以及使用GPT-4进行翻译和问答对的生成。该数据集的应用领域主要集中在宪法法律,旨在改善巴基斯坦法律信息的获取,并为全球NLP研究与本地化应用之间的桥梁提供基础。
LEGAL-UQA is the first Urdu-language legal question answering dataset developed by researchers at the Lahore University of Management Sciences, sourced from the Constitution of Pakistan. This dataset contains 619 question-answer pairs, each paired with corresponding legal article context, aiming to support domain-specific NLP resource requirements for low-resource languages. The dataset creation process includes OCR extraction, manual refinement, as well as translation and question-answer pair generation using GPT-4. Its application scenarios mainly focus on constitutional law, with the goals of improving access to legal information in Pakistan and laying a foundation for building a bridge between global NLP research and localization applications.
提供机构:
拉合尔管理科学大学
创建时间:
2024-10-17
原始信息汇总
LEGAL-UQA 数据集概述
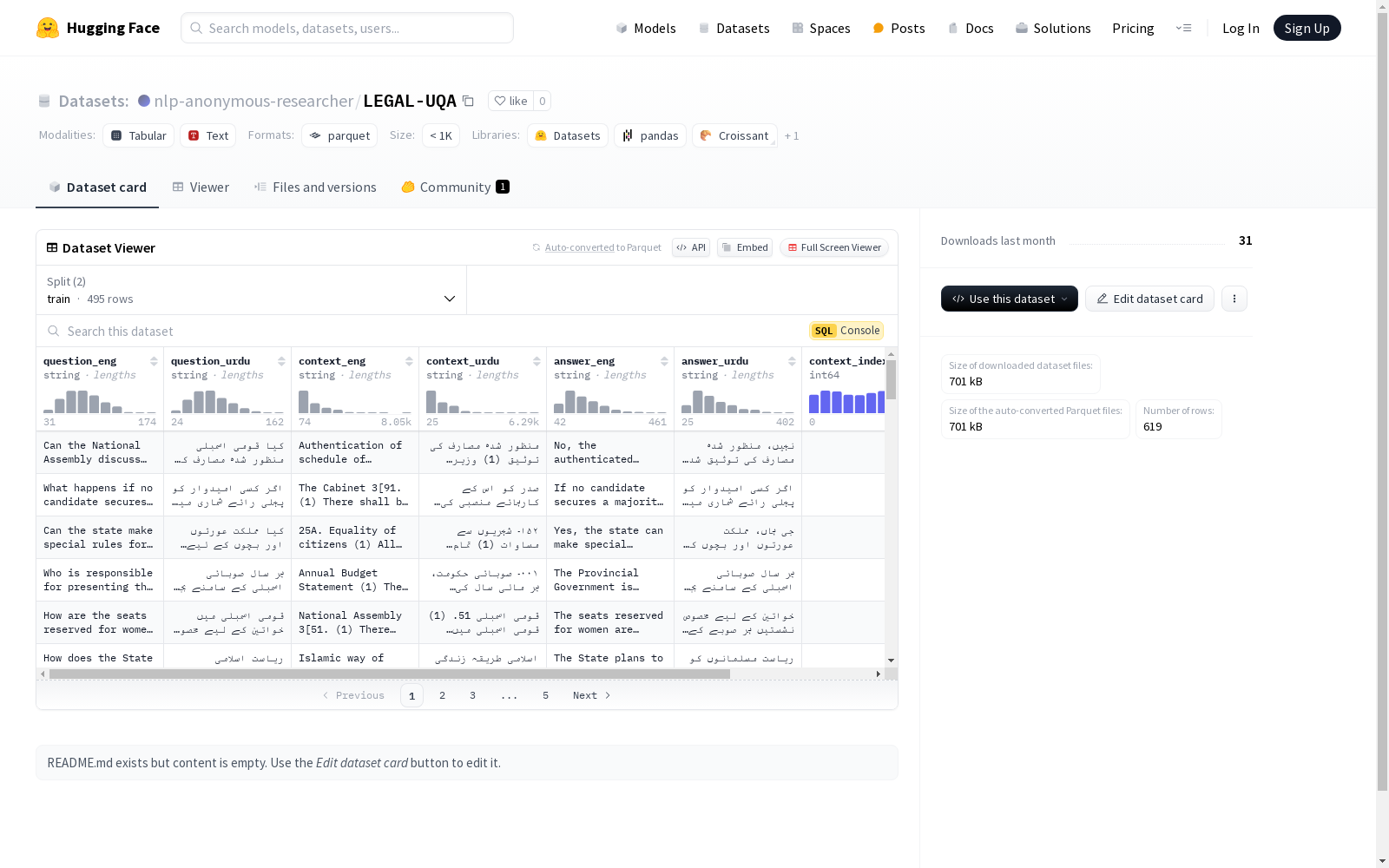
数据集信息
特征
- question_eng: 英文问题,数据类型为字符串。
- question_urdu: 乌尔都语问题,数据类型为字符串。
- context_eng: 英文上下文,数据类型为字符串。
- context_urdu: 乌尔都语上下文,数据类型为字符串。
- answer_eng: 英文答案,数据类型为字符串。
- answer_urdu: 乌尔都语答案,数据类型为字符串。
- context_index: 上下文索引,数据类型为整数(int64)。
- index_level_0: 索引级别0,数据类型为整数(int64)。
数据分割
- train: 训练集,包含495个样本,大小为1847013字节。
- validation: 验证集,包含124个样本,大小为510197字节。
数据集大小
- 下载大小: 701381字节
- 数据集大小: 2357210字节
配置
- config_name: default
- data_files:
- train: data/train-*
- validation: data/validation-*
- data_files:
搜集汇总
数据集介绍
构建方式
LEGAL-UQA数据集的构建始于对巴基斯坦宪法文本的处理。首先,利用最先进的Urdu OCR技术UTRNet从宪法图像中提取文本,随后通过GPT-4进行手动校正,以确保文本的准确性和一致性。接着,将提取的文本转换为可编辑的Word文档,并在每篇文章的开始和结束处插入分隔符。为了生成英语的问答对,根据文章的字数将其分为小、中、大三类,并利用GPT-4模型生成相应数量的问答对。最后,通过GPT-4模型将英语问答对翻译成Urdu版本,确保翻译的准确性和风格的一致性。
特点
LEGAL-UQA数据集的显著特点在于其双语性和领域专一性。该数据集包含了619对Urdu-English的问答对,每对都附有相应的法律文章上下文,这使得其在低资源语言的法律问答领域具有独特价值。此外,数据集的设计支持生成式问答模型,而非传统的抽取式问答,这为法律领域的自然语言处理提供了新的研究方向。
使用方法
LEGAL-UQA数据集主要用于训练和评估法律领域的问答系统。研究者可以利用该数据集对多语言模型进行微调,以提高其在法律文本上的表现。此外,数据集的结构也适用于检索增强生成(RAG)模型,这为构建更为智能的法律聊天机器人提供了可能。通过使用该数据集,研究者可以探索如何在低资源语言环境中实现高效的法律信息访问和处理。
背景与挑战
背景概述
在自然语言处理(NLP)领域,尽管近年来取得了显著进展,但这些进步主要集中于少数全球性语言,特别是英语,导致语言资源的不均衡分布。这种不平衡在法律等关键领域尤为明显。LEGAL-UQA数据集由巴基斯坦拉合尔管理科学大学(LUMS)的Faizan Faisal和Umair Yousaf创建,是首个源自巴基斯坦宪法的乌尔都语法律问答数据集。该数据集包含619个问答对,每个问答对均附有相应的法律条文背景,旨在满足低资源语言领域特定NLP资源的需求。LEGAL-UQA不仅填补了乌尔都语法律问答数据集的空白,还为提升巴基斯坦法律信息的可访问性奠定了基础。
当前挑战
LEGAL-UQA数据集在构建过程中面临多项挑战。首先,从巴基斯坦宪法中提取文本涉及复杂的OCR技术,尤其是处理乌尔都语文本图像时。其次,生成高质量的问答对需要GPT-4模型的辅助,这增加了数据集构建的技术复杂性。此外,尽管现有的大型语言模型在通用任务中表现出色,但在法律领域的特定任务上,如法律问答,这些模型的适应性仍存在显著挑战。最后,数据集的规模相对较小,仅涵盖宪法领域,未涉及更广泛的刑法、民法等,限制了其在更广泛法律应用中的适用性。
常用场景
经典使用场景
LEGAL-UQA数据集在法律问答领域中展现了其经典应用场景,特别是在巴基斯坦宪法相关问题的解答上。该数据集通过提供619对英-乌双语问答对及其对应的法律条文上下文,支持机器学习模型理解和回答乌尔都语中的法律查询。这种双语问答对的生成不仅促进了法律信息的跨语言访问,还为低资源语言的领域特定自然语言处理(NLP)资源需求提供了重要支持。
实际应用
在实际应用中,LEGAL-UQA数据集可以用于开发法律聊天机器人,为巴基斯坦的公民提供即时、全天候的法律查询解答服务。这些聊天机器人能够帮助用户理解法律术语、导航法律程序,并提供基本的法律指导,从而在司法系统中提高效率和公正性。此外,该数据集的双语特性也促进了法律翻译和跨文化法律交流的发展。
衍生相关工作
LEGAL-UQA数据集的发布催生了一系列相关研究工作,特别是在多语言法律问答系统和低资源语言NLP模型的优化上。例如,研究者们利用该数据集对mt5-large-UQA-1.0模型进行了微调,以适应法律领域的特定需求。此外,该数据集还激发了对其他低资源语言法律数据集的创建和研究,推动了全球范围内法律信息访问技术的进步。
以上内容由遇见数据集搜集并总结生成


