superviselab/video-understanding-distillation-sample
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/superviselab/video-understanding-distillation-sample
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
pretty_name: Video Understanding Distillation Sample
language:
- en
task_categories:
- text-generation
- image-text-to-text
tags:
- video-understanding
- multimodal
- distillation
- evaluation
- dataset
size_categories:
- n<1K
---
# Video Understanding Distillation Sample
This public sample shows what a **training-ready video understanding distillation dataset** can look like.
## Why this exists
Most teams evaluating outside data vendors want to know one thing first:
> What does the delivered data actually look like?
This sample is designed to answer that question.
It demonstrates how raw video clips can be converted into structured, model-ready supervision for:
- video understanding
- multimodal SFT
- teacher-student distillation
- evaluation and benchmark preparation
## What this sample includes
- `video_id`
- `clip_id`
- `duration_sec`
- `short_caption`
- `long_caption`
- `ocr_text`
- `transcript`
- `speaker_attribution`
- `distilled_target`
## What this sample is for
This is a **public schema and structure demonstration**.
It is not a production-scale dataset.
## If you are evaluating SuperviseLab
Use this sample together with:
- the overview Space
- the schema explorer
- the main website
## Related links
- Website: https://superviselab.com/?utm_source=huggingface&utm_medium=dataset&utm_campaign=hf_sample
- Overview Space: https://huggingface.co/spaces/superviselab/superviselab-overview
- Schema Explorer: https://huggingface.co/spaces/superviselab/schema-explorer
提供机构:
superviselab
搜集汇总
数据集介绍
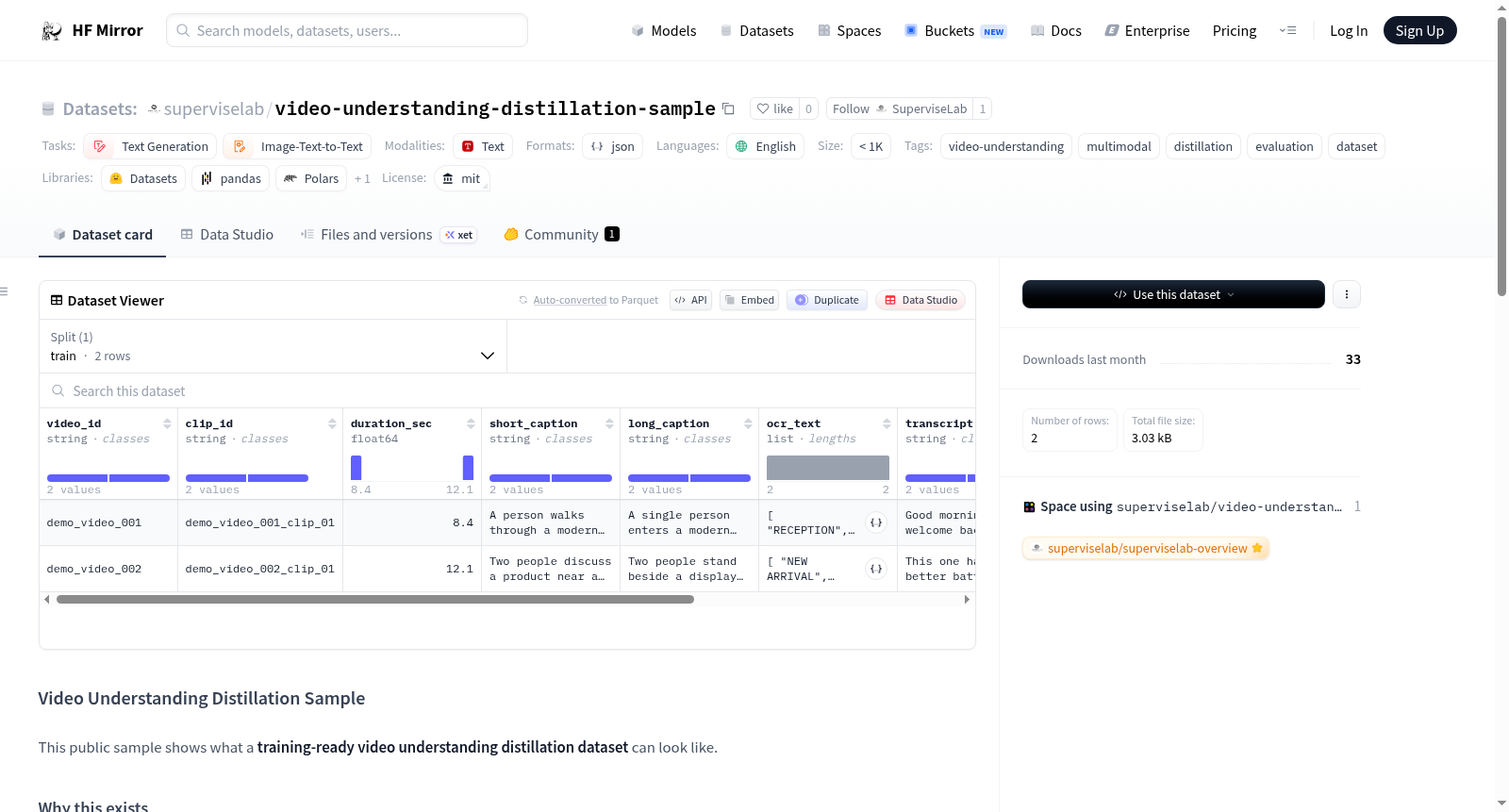
构建方式
本数据集作为视频理解蒸馏技术的样例,旨在展示如何将原始视频片段转化为结构化的、可直接用于模型训练的数据。其构建过程从视频源中提取关键信息,包括视频标识符、片段标识符、时长、短标题、长标题、光学字符识别文本、转录文本、说话人归因以及蒸馏目标。这些字段的精心设计反映了从原始视频内容到模型可用监督信号的完整转换链路,为教师-学生蒸馏及多模态指令微调提供了标准化的数据范式。
使用方法
用户可基于本数据集开展视频理解蒸馏的流程验证与架构探索。典型使用方式包括:将短标题和长标题作为监督信号进行多模态对比学习;利用蒸馏目标字段实施教师-学生框架下的知识蒸馏实验;结合ocr文本和转录开展视频时空信息的联合建模。建议配合SuperviseLab提供的概览空间和模式探索器,以更深入理解数据结构的组织逻辑与应用潜力。
背景与挑战
背景概述
视频理解领域正经历从粗粒度分类向细粒度语义解析的范式转变,亟需能够桥接原始视觉数据与结构化模型监督之间的标准化数据集。Video Understanding Distillation Sample数据集由SuperviseLab平台于近期创建,旨在为多模态蒸馏与教师-学生训练提供示范性样本。该数据集核心解决如何将非结构化视频片段转化为携带短标题、长描述、OCR文本、语音转录及说话人归因的模型就绪格式,其独创性在于引入‘蒸馏目标’字段,为视频理解中的知识迁移与评估基准构建确立可复现的范式。尽管样本规模不足千条,但其结构设计对学术界与工业界中从事多模态SFT及视频理解蒸馏的研究者具有重要参考价值,通过公开的Schema Explorer与概述空间,为数据采购方提供了评估外部供应商交付质量的透明化标尺。
当前挑战
该数据集所应对的核心挑战在于视频理解领域普遍存在的训练数据结构化不足问题:传统数据集多停留于视频-文本映射层面,缺乏面向蒸馏任务的细粒度标签,致使教师模型输出难以被高效压缩至学生模型。具体而言,挑战包含:1) 如何从原始视频流中精准提取多维度语义信号(如动态场景下的OCR文本与多说话人语音转录的时空对齐);2) 如何在短标题的简洁性与长描述的全面性之间平衡,以避免信息冗余或遗漏;3) 构建过程中需解决跨模态数据管道的一致性校验难题(如视频片段分割与相应字幕的毫秒级同步)。此外,该样本的规模瓶颈(n<1K)突显了在有限资源下验证蒸馏框架泛化性能的方法论挑战。
常用场景
经典使用场景
在视频理解领域,该数据集作为教学相长的典范,主要被用于构建多模态大语言模型的蒸馏训练流程。其核心价值在于将原始的、未经雕琢的视频片段转化为结构清晰、模型可直接吸收的监督信号,尤其适合教师-学生知识蒸馏场景。研究者和工程师可以利用其中的短描述、长描述、OCR文本、语音转录及说话人归属等字段,设计跨模态对齐与知识迁移的训练范式,从而在视频理解任务中实现轻量化模型对先进大模型能力的吸收与复现。
解决学术问题
该数据集精准地回应了视频理解研究中两大核心困境:数据标注的高昂成本与大模型部署时的推理效率瓶颈。一方面,它通过提供多元化的自动标注信息,缓解了纯手工标注耗时耗力且难以规模的痛点;另一方面,数据集内建的蒸馏目标(distilled_target)为解决大模型向轻量学生模型的知识迁移提供了标准化的示范,促使学术界能够在保持高理解精度的同时,大幅降低计算开销,推动了视频多模态领域绿色化、高效化的发展方向。
实际应用
在实际产业应用中,该数据集的设计蓝图可赋能众多视频内容驱动的场景。例如,在智能安防与监控领域,可基于蒸馏出的轻量模型实现实时的视频异常行为识别;在视频流媒体平台,它可辅助构建高效的视频摘要生成与个性化推荐系统,将冗长影像转化为精准的文字标签。此外,对于在线教育平台,该数据集的转录与说话人归因功能可用于自动生成课程字幕与知识点提炼,极大提升了人机交互的流畅性与信息检索的准确性。
数据集最近研究
最新研究方向
当前多模态视频理解领域的前沿研究方向正聚焦于如何将原始视频数据转化为结构化的、可直接用于模型训练的监督信号。该样本数据集展示了视频理解蒸馏过程中的关键要素,包括视频片段的多粒度语义描述(短字幕与长字幕)、光学字符识别文本、语音转录、说话人归因以及蒸馏目标。这种结构化的数据组织方式为教师-学生蒸馏范式下的视频理解模型训练提供了标准化接口,尤其适用于大语言模型与视觉语言模型的多模态指令微调与评估。随着视频内容理解在多模态大模型应用中的日益重要,此类数据集的设计理念为构建高效、可复用的视频监督信号提供了重要参考。
以上内容由遇见数据集搜集并总结生成


