ali5341/qasper-chat-format
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ali5341/qasper-chat-format
下载链接
链接失效反馈官方服务:
资源简介:
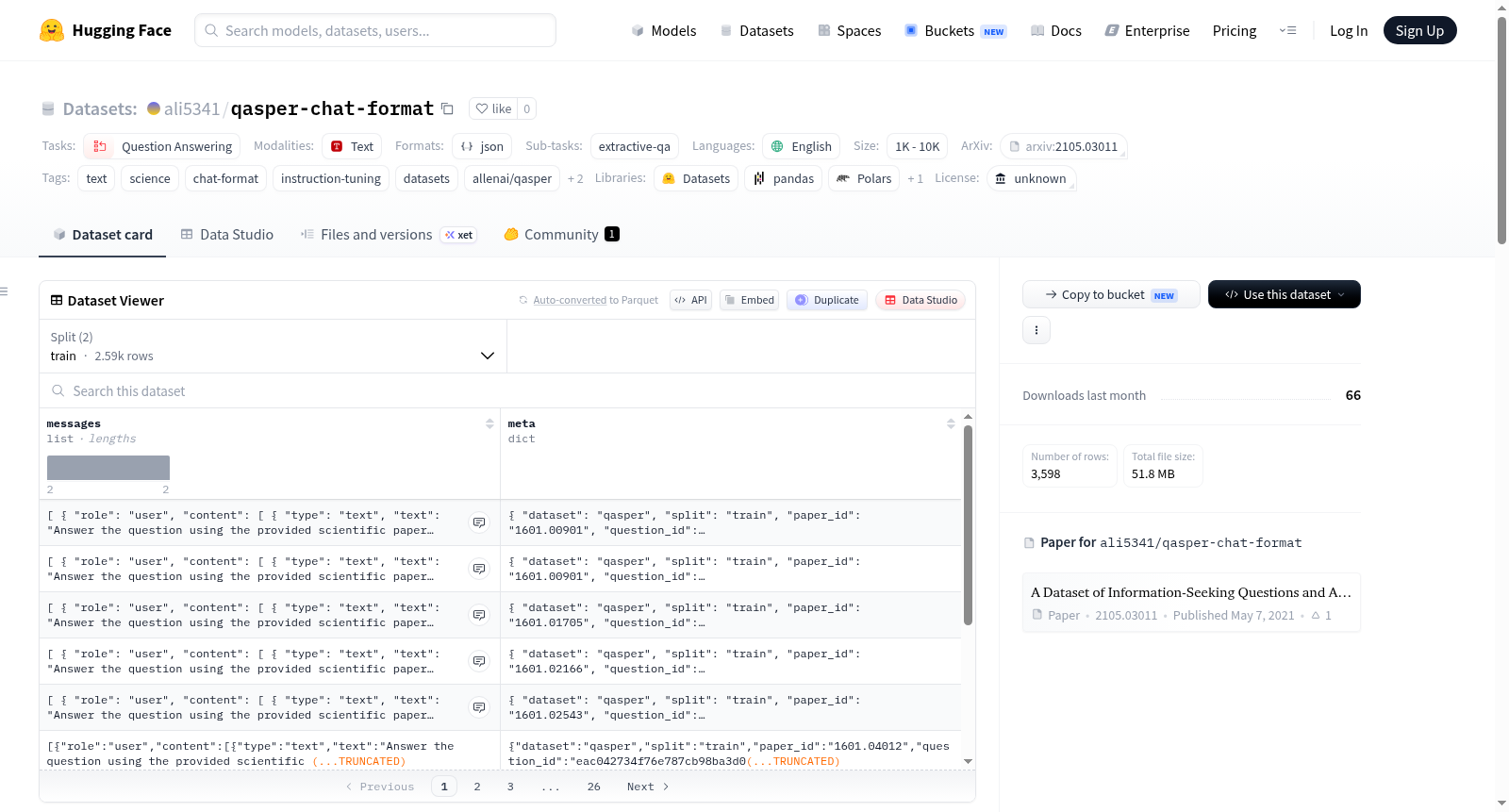
该数据集是QASPER数据集的聊天格式准备版本,用于监督微调(SFT)。数据集包含训练、验证和统计文件,以及一个准备脚本。原始数据集专注于科学NLP论文的问题回答和证据选择,包含5,049个问题和1,585篇论文,具有多种答案类型(自由形式、抽取式、是/否、无法回答)和证据注释。数据集的准备过程包括每个(论文,问题)的最佳注释,答案归一化优先级(自由形式 > 是/否 > 抽取式 > 无法回答),以及混合上下文模式(仅证据或全文)。每个JSONL行包含用户和助手的消息,以及元数据(ID、答案类型、上下文模式、证据计数)。
This dataset is a chat-format preparation of QASPER for supervised fine-tuning (SFT). It includes training, validation, and statistics files, as well as a preparation script. The original dataset focuses on question answering and evidence selection for scientific NLP papers, containing 5,049 questions over 1,585 papers with multiple answer types (free-form, extractive, yes/no, unanswerable) and evidence annotations. The preparation process involves best available annotations per (paper, question), answer normalization priority (free-form > yes/no > extractive > unanswerable), and mixed context mode (evidence-only or full-text). Each JSONL row contains messages from user and assistant, along with metadata (IDs, answer type, context mode, evidence count).
提供机构:
ali5341
搜集汇总
数据集介绍
构建方式
QASPER Chat-Format 数据集的构建基于原始数据集 allenai/qasper,该原始数据集聚焦于科学 NLP 论文的问答与证据选择。构建过程中,每一条数据对应于一个论文与问题的配对,并采用优先级排序选取最佳注释答案:优先使用自由形式答案,其次是是非题答案,再是抽取式片段,最后为不可回答类。上下文模式融合了仅包含证据的片段与全文内容。用户指令采用问题优先的结构,包含文本指令、问题、论文标题、摘要及上下文,而助手的回答则是对应的标准化答案文本。最终数据以 JSONL 格式存储,包含训练集与验证集,并附带统计文件及可复现的 Python 预处理脚本。
特点
该数据集最显著的特点在于其对话格式的应用,采用 OpenAI 风格的 messages 结构,使其天然适配于指令微调场景。数据保留了原始 QASPER 的多重答案类型与证据注释属性,覆盖了自由形式、是非、抽取式及不可回答等多种问答形态,有助于提升模型对科学文献的深层理解能力。同时,上下文模式的混合设计(证据仅与全文交替)增强了对模型证据选择能力的训练,使得该数据集不仅适用于通用问答任务,更能用于需要精准引用和证据推理的科学文本理解任务。
使用方法
使用 QASPER Chat-Format 数据集时,可直接加载 JSONL 文件中的 messages 字段进行监督式微调。用户部分包含完整的指令与上下文,助手部分为标准答案,无需额外处理即可注入如 Unsloth、HuggingFace Transformers 等框架。数据集的 schema 清晰,每条记录还包含元数据(如证据数量、答案类型),便于进行实验分析或过滤。若要复现构建流程,可运行提供的 Python 脚本 prepare_qasper_unsloth.py,从而获得完全一致的对话格式数据,适配不同微调需求。
背景与挑战
背景概述
近年来,随着自然语言处理技术的迅猛发展,对话式问答系统在科学文献理解领域展现出巨大潜力。QASPER Chat-Format数据集诞生于2021年,由Allen人工智能研究所(AI2)的研究团队基于其原始QASPER数据集改造而来,旨在将科学论文问答任务转化为指令微调格式。该数据集聚焦于自然语言处理领域的学术论文,整合了5049个问题与1585篇论文的对应关系,核心研究问题在于提升模型对论文中信息性问题的理解与证据选择能力。作为QASPER的衍生版本,它采用OpenAI风格的对话格式,适用于监督微调,显著增强了模型在科学问答任务上的表现,对推动学术文献挖掘和智能问答系统的发展具有重要意义。
当前挑战
该数据集面临的挑战主要体现在两个层面。在领域问题层面,科学论文问答任务需处理多种答案类型(自由形式、是非题、抽取式片段及不可回答),并要求模型具备精准的证据选择能力,这对模型的语义理解和信息定位提出了极高要求。在构建过程中,研究团队需对原始QASPER数据集进行格式转换,将每个问题与论文的最优答案相关联,并混合使用仅证据和全文两种上下文模式,这一过程涉及复杂的答案优先级排序(自由形式优先)和结构统一,同时需确保对话格式的语义保真度,从而增加了数据预处理的复杂度。
常用场景
经典使用场景
在科学文献理解与问答领域,QASPER Chat-Format数据集被广泛用于训练和评估大语言模型在科研论文上的信息检索与问答能力。该数据集以对话格式封装了来自自然语言处理领域学术论文的5,049个问题及其对应答案,涵盖自由文本、抽取式片段、是/否判断及不可回答等多种答案类型。研究者利用这一格式,能够高效地将科学问答任务转化为指令微调场景,从而提升模型在专业文献中定位证据、提取信息并生成准确回答的能力。
衍生相关工作
QASPER Chat-Format数据集的衍生工作涵盖了多个研究方向。在指令微调领域,研究者借鉴其对话格式设计,开发了面向生物医学、计算语言学等学科的类似科学问答数据集。在证据选择方面,该数据集的注释规范启发了多项关于可解释问答模型的工作,例如利用注意力机制定位支持性文本片段。此外,原始QASPER论文(arxiv:2105.03011)提出的混合上下文模式,被后续研究广泛采纳用于构建更复杂的多证据推理任务,推动了科学文献理解技术的持续进步。
数据集最近研究
最新研究方向
当前,QASPER数据集的对话式指令微调版本正成为科学文献问答领域的前沿研究焦点。该数据集将原本面向NLP论文的复杂信息检索与证据选择任务,转化为更契合大语言模型的聊天格式,推动了从传统抽取式问答向多轮对话与指令遵循能力的迁移。研究者利用其多类型答案结构(自由形式、二值判断、抽取片段及不可回答)和证据标注,探索模型在科学推理中的可解释性与忠实性。同时,结合最新的Arxiv论文(2105.03011),该数据集的标准化处理正助力于构建更具鲁棒性的科学助手,对加速学术知识挖掘与自动化文献综述具有深远影响。
以上内容由遇见数据集搜集并总结生成


