subCat-human
收藏Hugging Face2025-08-12 更新2025-08-13 收录
下载链接:
https://huggingface.co/datasets/ABSTRACTION-ERC/subCat-human
下载链接
链接失效反馈官方服务:
资源简介:
SubCat是一个意大利语的心理学语言数据集,旨在研究意大利语母语者如何为常见物体类别生成示例。该数据集包含187个基础级别具体类别下的24,659个从属类别示例,这些类别被组织在12个上级语义类别下。
创建时间:
2025-08-05
原始信息汇总
SubCat: 意大利语言中人类心智与LLMs下属类别数据集
数据集概述
- 名称: SubCat
- 用途: 研究意大利母语者对常见物体类别生成示例的方式
- 语言: 意大利语
- 许可证: CC BY 4.0
- 论文: How Humans and LLMs Organize Conceptual Knowledge: Exploring Subordinate Categories in Italian
数据集创建
- 刺激材料: 187个基本级别具体类别(如狗、桌子),分为12个上位语义类别(如动物、家具)
- 参与者: 365名意大利母语者
- 任务: 为每个概念生成尽可能多的示例
- 最终数据: 24,659个经过清理和标准化的示例
数据处理
- 步骤: 纠正常见拼写错误和打字错误
- 目的: 确保最终数据集的准确性和一致性
数据集结构
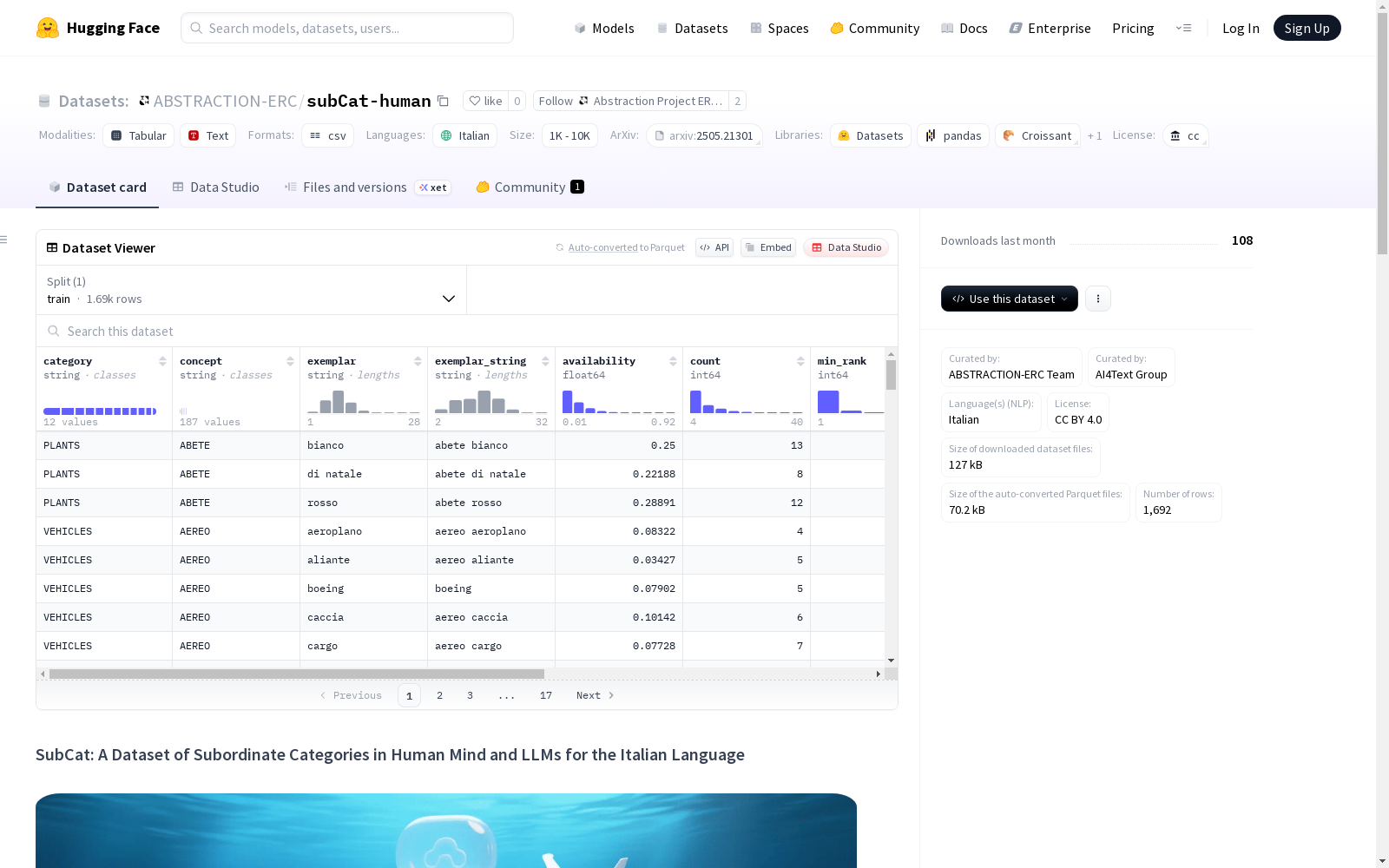
- 列名:
category: 上位类别concept: 基本级别类别exemplar: 生成的下属级别示例/概念exemplar_string: 经过清理的示例版本availability: 示例作为其关联类别成员的易生成性指标count: 示例在参与者中的出现次数min_rank: 示例出现的最小排名max_rank: 示例出现的最高排名mean_rank: 示例出现的平均排名first_occur: 示例首次出现的比例dominance: 生成该示例的参与者比例abs_freq_corpus: 仅适用于LLM生成的示例,在意大利语料库ItTenTen中的出现次数
引用信息
bibtex @inproceedings{pedrotti-etal-2025-humans, title = "How Humans and {LLM}s Organize Conceptual Knowledge: Exploring Subordinate Categories in {I}talian", author = "Pedrotti, Andrea and Rambelli, Giulia and Villani, Caterina and Bolognesi, Marianna", editor = "Che, Wanxiang and Nabende, Joyce and Shutova, Ekaterina and Pilehvar, Mohammad Taher", booktitle = "Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)", month = jul, year = "2025", address = "Vienna, Austria", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2025.acl-long.224/", doi = "10.18653/v1/2025.acl-long.224", pages = "4464--4482", ISBN = "979-8-89176-251-0", }
搜集汇总
数据集介绍
构建方式
在认知语言学领域,SubCat数据集通过严谨的心理学实验范式构建。研究团队选取187个意大利语基础层级概念词,涵盖12个上位语义类别,组织365名意大利母语者参与范例生成任务。参与者需针对每个基础概念自由列举下属类别范例,最终通过拼写校正和标准化处理,形成包含24,659个范例的纯净数据集。数据采集过程注重自然语言产出的生态效度,完整保留了人类概念组织的认知特征。
特点
该数据集以意大利语为研究对象,系统记录了人类概念层级结构的心理表征。每个范例条目包含丰富的元数据,不仅涵盖基础概念与上位类别对应关系,更通过可用性指标、出现频次、主导性指数等量化维度,精确刻画范例在心理词典中的激活模式。独特的排名统计参数(最小/最大/平均排名)与首次出现比率,为研究概念通达时序特征提供了珍贵数据。针对LLM生成范例的语料频率标注,则为跨模态认知比较研究创造了条件。
使用方法
研究者可通过HuggingFace平台获取该CC BY 4.0许可数据集,利用category和concept字段进行语义类别检索。availability与dominance指标适用于认知建模中的概念典型性分析,而rank系列参数可支持概念激活时序研究。对比分析时,abs_freq_corpus字段支持人类与LLM概念组织的量化比较。数据集配套的ACL会议论文提供了详实的理论基础,建议结合ItTenTen意大利语料库进行跨验证研究。
背景与挑战
背景概述
SubCat-human数据集由ABSTRACTION-ERC团队与AI4Text研究组联合构建,旨在探索意大利语使用者在心理词典中如何组织从属类别概念。该数据集于2025年通过大规模心理语言学实验创建,收录365名意大利母语者对187个基础层级概念(如'dog'、'table')生成的24,659个从属范例。作为首例系统研究意大利语概念层级结构的开源资源,其创新性体现在将传统认知心理学范式与自然语言处理技术结合,为比较人类与大型语言模型的概念表征机制提供了基准数据。相关成果发表于计算语言学顶会ACL,对心理语言学、认知科学及跨文化语言模型评估领域具有重要方法论意义。
当前挑战
该数据集面临双重挑战:在科学层面,需要解决概念生成任务中存在的个体差异性问题,不同受试者对同一基础概念产生的从属范例存在显著变异性,这要求设计新型的标准化度量指标(如availability和dominance)来量化概念可及性。在技术层面,意大利语丰富的形态变化导致数据清洗复杂度陡增,原始数据中拼写错误和屈折变化的标准化处理需要开发特定语言的自动化校正流程。此外,如何建立跨模态评估框架,将人类概念生成模式与LLMs的分布语义表征进行有效对比,仍是当前研究的核心难点。
常用场景
经典使用场景
在心理语言学领域,subCat-human数据集为研究意大利语母语者的概念知识组织提供了重要资源。该数据集通过收集187个基础类别下的24,659个从属范例,揭示了人类如何对日常概念进行层级分类。研究人员可利用这些数据,分析不同文化背景下概念组织的共性与差异,探索认知过程中的语言表征机制。
实际应用
在实际应用中,该数据集支撑了教育领域的词汇教学系统开发,帮助设计符合认知规律的语言学习材料。临床心理学领域可借助范例生成模式,评估特定人群的概念形成障碍。人机交互界面设计者则利用这些数据优化意大利语语境下的语义搜索算法。
衍生相关工作
基于该数据集衍生的研究包括跨语言概念可及性比较框架、基于典型性度量的语义网络构建方法等。相关团队进一步开发了结合眼动追踪的范例生成实验范式,推动形成了'概念可达性-语言频率'的双维度评估体系,为认知建模提供了新的理论基础。
以上内容由遇见数据集搜集并总结生成


