oliverkinch/doab-da-bt
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/oliverkinch/doab-da-bt
下载链接
链接失效反馈官方服务:
资源简介:
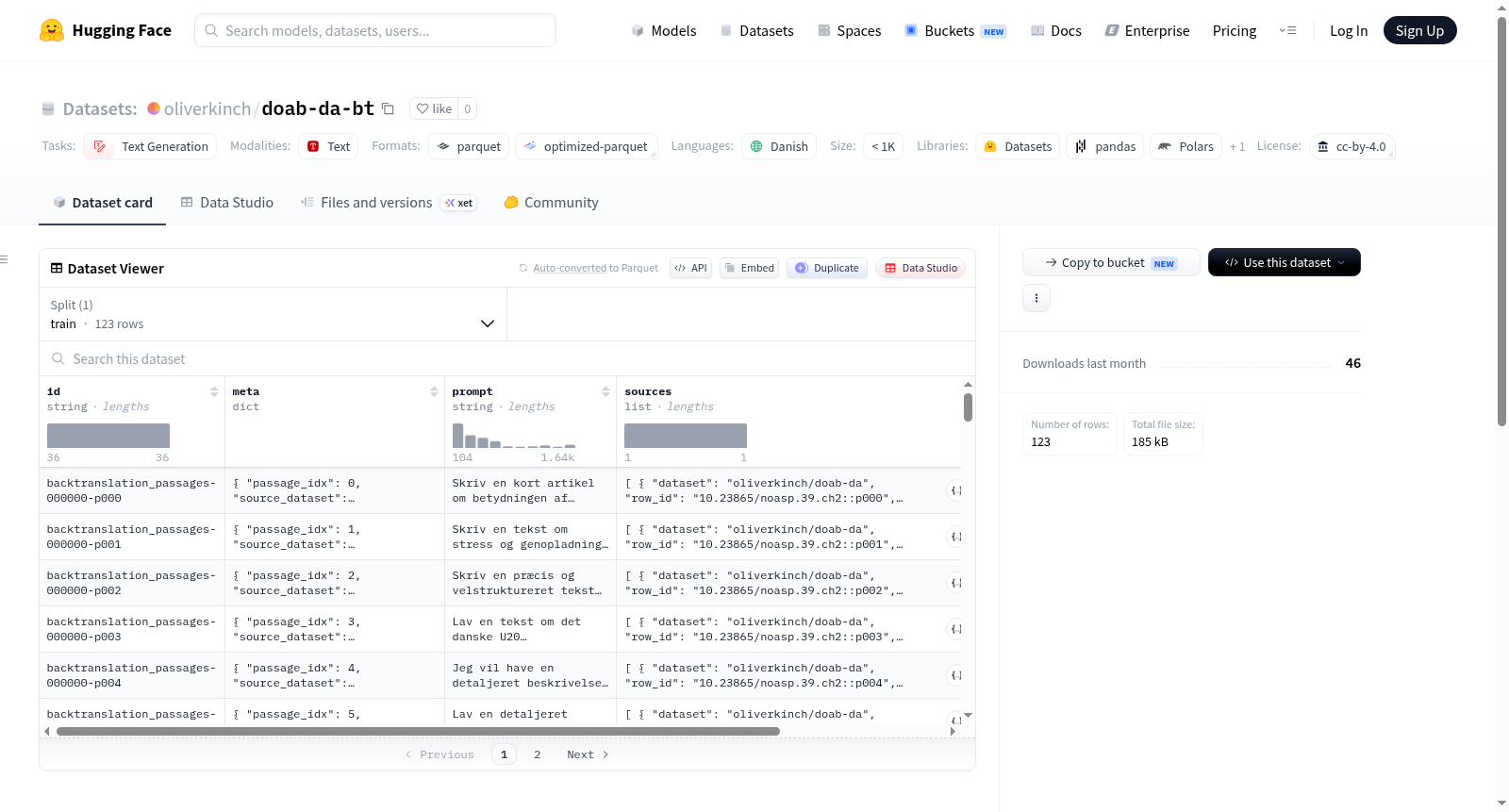
该数据集是一个丹麦语的文本生成数据集,许可证为cc-by-4.0。数据集包含123个训练示例,大小为280346字节。数据集的结构包括id、meta、prompt、sources和target等字段。meta字段包含多个子字段,如passage_idx、source_dataset、source_id等。数据集的生成方法是指令回译,即使用源语料库的段落作为目标,由LLM生成每个段落的提示。提示通过使用nvidia/Nemotron-Personas-USA中的人物进行多样化处理。数据集的来源是oliverkinch/doab-da,包含113行,列包括id、meta、prompt、sources和target。
This dataset is a Danish text generation dataset licensed under cc-by-4.0. It contains 123 training examples with a size of 280346 bytes. The dataset structure includes fields such as id, meta, prompt, sources, and target. The meta field contains multiple subfields like passage_idx, source_dataset, source_id, etc. The generation method of the dataset is instruction backtranslation, where passages from the source corpus are used as targets, and an LLM generates the prompt that would have produced each passage. Prompts are diversified using personas from nvidia/Nemotron-Personas-USA. The dataset source is oliverkinch/doab-da, containing 113 rows with columns including id, meta, prompt, sources, and target.
提供机构:
oliverkinch
搜集汇总
数据集介绍
构建方式
该数据集源自丹麦语开源书籍语料库doab-da,通过指令反向翻译技术构建。从语料库中抽取113个文本段落作为目标输出,利用大语言模型为每个段落反向生成对应的用户指令作为prompt。为增强指令多样性,引入Nvidia的Nemotron人物角色数据集,为不同段落分配多样化的虚拟用户身份,使生成的prompt风格与内容更加丰富。最终数据集包含id、meta、prompt、sources、target五个字段,覆盖123条训练样本。
特点
该数据集专为丹麦语文本生成任务设计,具有指令反向翻译的独特构建方式,使每条数据天然形成问答对结构。人物角色的引入有效提升了指令的多样性,有助于模型学习应对不同风格的用户请求。数据集中保留完整的来源元信息,包括原始数据集、分片、URL及标题,便于追溯与验证。字段设计简洁而全面,兼顾生成任务所需的核心输入输出与辅助元数据。
使用方法
该数据集适用于微调丹麦语大语言模型以执行指令跟随式文本生成任务。使用时以prompt字段作为模型输入,target字段作为期望输出,构建标准的监督式训练流程。sources与meta字段可用于数据筛选、去重或质量评估。由于train分片采用glob匹配方式加载,用户可通过HuggingFace datasets库的load_dataset函数直接指定配置名称default加载全部数据,适用于单轮对话或段落补全类场景。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的指令微调数据集稀缺,严重制约了大型语言模型在多语言场景下的性能表现。丹麦语作为斯堪的纳维亚语系的重要成员,其相关高质量指令数据的匮乏尤为显著。名为doab-da-bt的数据集于近期由研究人员基于开放获取图书语料库构建,旨在通过指令反向翻译技术填补这一空白。该数据集由113条样本组成,每条样本包含自动生成的丹麦语提示词与对应的语料库段落,其提示词生成过程引入了多样化的用户角色设定,以增强语义丰富性。作为丹麦语指令微调数据生成的范式探索,该数据集为低资源语言的模型对齐研究提供了可复现的基准,并推动了多语言自然语言处理技术在学术与工业场景中的落地。
当前挑战
该数据集的核心挑战在于解决低资源语言指令微调数据的领域问题:丹麦语缺乏大规模人工标注的指令对,传统数据构建方法成本高昂且难以扩展。构建过程中,自动生成的提示词尽管通过角色多样化提升质量,但仍可能无法完全覆盖真实用户意图的复杂性,导致模型泛化能力受限。此外,数据集的规模仅为113条,远小于英语等主流语言的数据集,限制了指令微调效果的鲁棒性。来源语料库局限于开放获取图书,体裁单一性使得模型在对话、摘要等多样化任务上的适应性存疑。最后,反向翻译过程中引入的噪声可能传播至模型训练,如何有效过滤低质量生成结果成为维持数据可靠性的关键瓶颈。
常用场景
经典使用场景
该数据集专为丹麦语的指令微调与文本生成任务而构建,其经典使用场景在于训练和评估大语言模型在丹麦语境下的指令跟随能力。通过将开放获取(Open Access)的学术段落作为目标文本,并利用指令反向翻译技术生成多样化用户提示,研究者可借助该数据集构建能够理解并回应丹麦语指令的对话或问答系统。其典型应用涵盖丹麦语语义理解、段落生成及多轮交互中的语境保持,为低资源语言的指令微调提供了宝贵的数据基础。
解决学术问题
在学术层面,该数据集直击低资源语言在指令微调领域的数据匮乏问题。现有大语言模型多依赖英语或高资源语言进行微调,导致丹麦语等语言的模型性能受限。该数据集通过从开放获取语料库中提取高质量段落,并运用指令反向翻译与角色多样性增强技术,生成了结构化的指令-回答对。它有效助力研究者探索低资源语言的跨任务泛化能力、数据合成方法及模型对齐策略,推动了多语言自然语言处理在公平性与包容性方面的进步。
衍生相关工作
该数据集衍生了一系列关于低资源语言指令微调与数据增强的经典工作。其采用的指令反向翻译方法受启发于自回归式指令数据生成研究,同时结合了角色多样性框架,相关成果可追溯至利用外部知识库丰富提示多样性的探索。此外,该数据集经常与多语言Benchmark如DanLP或ScandiQA联合使用,以评估丹麦语模型在生成、理解及鲁棒性方面的表现,并催生了针对斯堪的纳维亚语言族的跨语言迁移学习研究。
以上内容由遇见数据集搜集并总结生成


