资源简介:
---
language:
- en
license: cc-by-4.0
license_link: https://creativecommons.org/licenses/by/4.0/
tags:
- automatic-diagnosis
- automatic-symptom-detection
- differential-diagnosis
- synthetic-patients
- diseases
- health-care
pretty_name: DDXPlus
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- tabular-classification
task_ids:
- multi-class-classification
paperswithcode_id: ddxplus
configs:
- config_name: default
data_files:
- split: train
path: "train.csv"
- split: test
path: "test.csv"
- split: validate
path: "validate.csv"
extra_gated_prompt: "By accessing this dataset, you agree to use it solely for research purposes and not for clinical decision-making."
extra_gated_fields:
Consent: checkbox
Purpose of use:
type: select
options:
- Research
- Educational
- label: Other
value: other
train-eval-index:
- config: default
task: medical-diagnosis
task_id: binary-classification
splits:
train_split: train
eval_split: validate
col_mapping:
AGE: AGE
SEX: SEX
PATHOLOGY: PATHOLOGY
EVIDENCES: EVIDENCES
INITIAL_EVIDENCE: INITIAL_EVIDENCE
DIFFERENTIAL_DIAGNOSIS: DIFFERENTIAL_DIAGNOSIS
metrics:
- type: accuracy
name: Accuracy
- type: f1
name: F1 Score
---
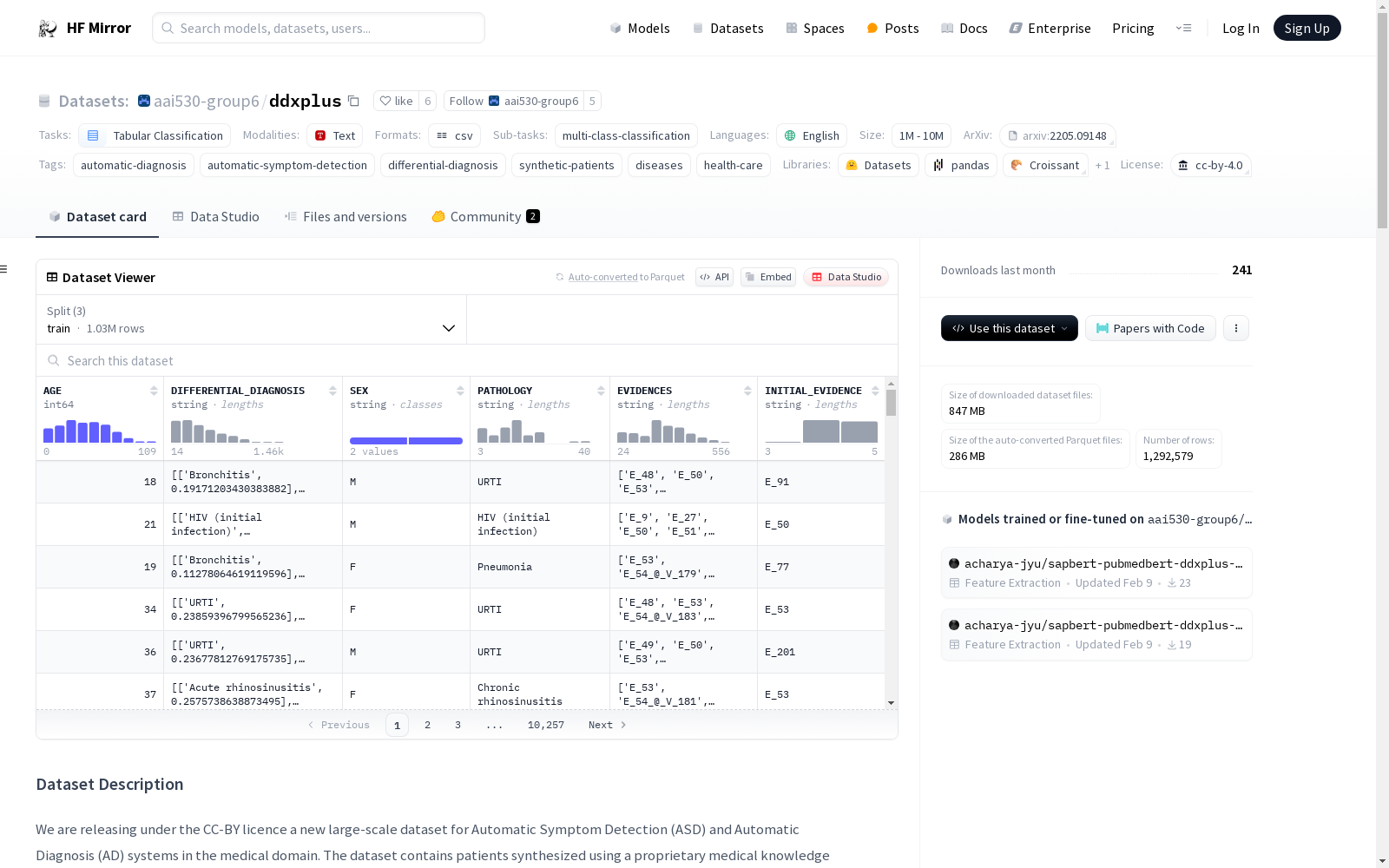
# Dataset Description
We are releasing under the CC-BY licence a new large-scale dataset for Automatic Symptom Detection (ASD) and Automatic Diagnosis (AD) systems in the medical domain. The dataset contains patients synthesized using a proprietary medical knowledge base and a commercial rule-based AD system. Patients in the dataset are characterized by their socio-demographic data, a pathology they are suffering from, a set of symptoms and antecedents related to this pathology, and a differential diagnosis. The symptoms and antecedents can be binary, categorical and multi-choice, with the potential of leading to more efficient and natural interactions between ASD/AD systems and patients. To the best of our knowledge, this is the first large-scale dataset that includes the differential diagnosis, and non-binary symptoms and antecedents.
**Note**: We use evidence as a general term to refer to a symptom or an antecedent.
This directory contains the following files:
- **release_evidences.json**: a JSON file describing all possible evidences considered in the dataset.
- **release_conditions.json**: a JSON file describing all pathologies considered in the dataset.
- **release_train_patients.zip**: a CSV file containing the patients of the training set.
- **release_validate_patients.zip**: a CSV file containing the patients of the validation set.
- **release_test_patients.zip**: a CSV file containing the patients of the test set.
## Evidence Description
Each evidence in the `release_evidences.json` file is described using the following entries:
- **name**: name of the evidence.
- **code_question**: a code allowing to identify which evidences are related. Evidences having the same `code_question` form a group of related symptoms. The value of the `code_question` refers to the evidence that need to be simulated/activated for the other members of the group to be eventually simulated.
- **question_fr**: the query, in French, associated to the evidence.
- **question_en**: the query, in English, associated to the evidence.
- **is_antecedent**: a flag indicating whether the evidence is an antecedent or a symptom.
- **data_type**: the type of evidence. We use `B` for binary, `C` for categorical, and `M` for multi-choice evidences.
- **default_value**: the default value of the evidence. If this value is used to characterize the evidence, then it is as if the evidence was not synthesized.
- **possible-values**: the possible values for the evidences. Only valid for categorical and multi-choice evidences.
- **value_meaning**: The meaning, in French and English, of each code that is part of the `possible-values` field. Only valid for categorical and multi-choice evidences.
## Pathology Description
The file `release_conditions.json` contains information about the pathologies that patients in the datasets may suffer from. Each pathology has the following attributes:
- **condition_name**: name of the pathology.
- **cond-name-fr**: name of the pathology in French.
- **cond-name-eng**: name of the pathology in English.
- **icd10-id**: ICD-10 code of the pathology.
- **severity**: the severity associated with the pathology. The lower the more severe.
- **symptoms**: data structure describing the set of symptoms characterizing the pathology. Each symptom is represented by its corresponding `name` entry in the `release_evidences.json` file.
- **antecedents**: data structure describing the set of antecedents characterizing the pathology. Each antecedent is represented by its corresponding `name` entry in the `release_evidences.json` file.
## Patient Description
Each patient in each of the 3 sets has the following attributes:
- **AGE**: the age of the synthesized patient.
- **SEX**: the sex of the synthesized patient.
- **PATHOLOGY**: name of the ground truth pathology (`condition_name` property in the `release_conditions.json` file) that the synthesized patient is suffering from.
- **EVIDENCES**: list of evidences experienced by the patient. An evidence can either be binary, categorical or multi-choice. A categorical or multi-choice evidence is represented in the format `[evidence-name]_@_[evidence-value]` where [`evidence-name`] is the name of the evidence (`name` entry in the `release_evidences.json` file) and [`evidence-value`] is a value from the `possible-values` entry. Note that for a multi-choice evidence, it is possible to have several `[evidence-name]_@_[evidence-value]` items in the evidence list, with each item being associated with a different evidence value. A binary evidence is represented as `[evidence-name]`.
- **INITIAL_EVIDENCE**: the evidence provided by the patient to kick-start an interaction with an ASD/AD system. This is useful during model evaluation for a fair comparison of ASD/AD systems as they will all begin an interaction with a given patient from the same starting point. The initial evidence is randomly selected from the binary evidences found in the evidence list mentioned above (i.e., `EVIDENCES`) and it is part of this list.
- **DIFFERENTIAL_DIAGNOSIS**: The ground truth differential diagnosis for the patient. It is represented as a list of pairs of the form `[[patho_1, proba_1], [patho_2, proba_2], ...]` where `patho_i` is the pathology name (`condition_name` entry in the `release_conditions.json` file) and `proba_i` is its related probability.
## Note:
We hope this dataset will encourage future works for ASD and AD systems that consider the differential diagnosis and the severity of pathologies. It is important to keep in mind that this dataset is formed of synthetic patients and is meant for research purposes. Given the assumptions made during the generation process of this dataset, we would like to emphasize that the dataset should not be used to train and deploy a model prior to performing rigorous evaluations of the model performance and verifying that the system has proper coverage and representation of the population that it will interact with.
It is important to understand that the level of specificity, sensitivity and confidence that a physician will seek when evaluating a patient will be influenced by the clinical setting. The dataset was built for acute care and biased toward high mortality and morbidity pathologies. Physicians will tend to consider negative evidences as equally important in such a clinical context in order to evaluate high acuity diseases.
In the creation of the DDXPlus dataset, a small subset of the diseases was chosen to establish a baseline. Medical professionals have to consider this very important point when reviewing the results of models trained with this dataset, as the differential is considerably smaller. A smaller differential means less potential evidences to collect. It is thus essential to understand this point when we look at the differential produced and the evidence collected by a model based on this dataset.
For more information, please check our [paper](https://arxiv.org/abs/2205.09148).